Meta plans to test exclusive features that will be incorporated in paid versions of Facebook, Instagram, and WhatsApp. It confirmed these plans to TechCrunch.
But these plans are not to be confused with the ad-free subscription options that Meta introduced for Facebook and Instagram in the EU, the European Economic Area, and Switzerland in late 2023 and framed as a way to comply with General Data Protection Regulation (GDPR) and Digital Markets Act requirements.
From November 2023, users in those regions could either keep using the services for free with personalized ads or pay a monthly fee for an ad‑free experience. European rules require Meta to get users’ consent in order to show them targeted ads, so this was an obvious attempt to recoup advertising revenue when users declined to give that consent.
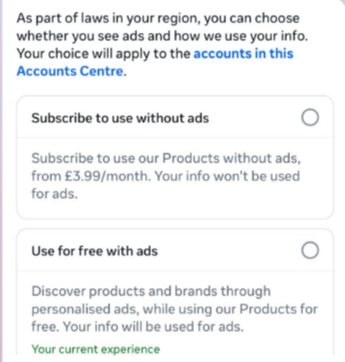
This year, users in the UK were given the same choice: use Meta’s products for free or subscribe to use them without ads. But only grudgingly, judging by the tone in the offer… “As part of laws in your region, you have a choice.”
The ad-free option that has been rolling out coincides with the announcement of Meta’s premium subscriptions.
That ad-free option, however, is not what Meta is talking about now.
The newly announced plans are not about ads, and they are also separate from Meta Verified, which starts at around $15 a month and focuses on creators and businesses, offering a verification badge, better support, and anti‑impersonation protection.
Instead, these new subscriptions are likely to focus on additional features—more control over how users share and connect, and possibly tools such as expanded AI capabilities, unlimited audience lists, seeing who you follow that doesn’t follow you back, or viewing stories without the poster knowing it was you.
These examples are unconfirmed. All we know for sure is that Meta plans to test new paid features to see which ones users are willing to pay for and how much they can charge.
Meta has said these features will focus on productivity, creativity, and expanded AI.
My opinion
Unfortunately, this feels like another refusal to listen.
Most of us aren’t asking for more AI in our feeds. We’re asking for a basic sense of control: control over who sees us, what’s tracked about us, and how our data is used to feed an algorithm designed to keep us scrolling.
Users shouldn’t have to choose between being mined for behavioral data or paying a monthly fee just to be left alone. The message baked into “pay or be profiled” is that privacy is now a luxury good, not a default right. But while regulators keep saying the model is unlawful, the experience on the ground still nudges people toward the path of least resistance: accept the tracking and move on.
Even then, this level of choice is only available to users in Europe.
Why not offer the same option to users in the US? Or will it take stronger US privacy regulation to make that happen?
We don’t just report on threats – we help protect your social media
Meta plans to test exclusive features that will be incorporated in paid versions of Facebook, Instagram, and WhatsApp. It confirmed these plans to TechCrunch.
But these plans are not to be confused with the ad-free subscription options that Meta introduced for Facebook and Instagram in the EU, the European Economic Area, and Switzerland in late 2023 and framed as a way to comply with General Data Protection Regulation (GDPR) and Digital Markets Act requirements.
From November 2023, users in those regions could either keep using the services for free with personalized ads or pay a monthly fee for an ad‑free experience. European rules require Meta to get users’ consent in order to show them targeted ads, so this was an obvious attempt to recoup advertising revenue when users declined to give that consent.
This year, users in the UK were given the same choice: use Meta’s products for free or subscribe to use them without ads. But only grudgingly, judging by the tone in the offer… “As part of laws in your region, you have a choice.”
The ad-free option that has been rolling out coincides with the announcement of Meta’s premium subscriptions.
That ad-free option, however, is not what Meta is talking about now.
The newly announced plans are not about ads, and they are also separate from Meta Verified, which starts at around $15 a month and focuses on creators and businesses, offering a verification badge, better support, and anti‑impersonation protection.
Instead, these new subscriptions are likely to focus on additional features—more control over how users share and connect, and possibly tools such as expanded AI capabilities, unlimited audience lists, seeing who you follow that doesn’t follow you back, or viewing stories without the poster knowing it was you.
These examples are unconfirmed. All we know for sure is that Meta plans to test new paid features to see which ones users are willing to pay for and how much they can charge.
Meta has said these features will focus on productivity, creativity, and expanded AI.
My opinion
Unfortunately, this feels like another refusal to listen.
Most of us aren’t asking for more AI in our feeds. We’re asking for a basic sense of control: control over who sees us, what’s tracked about us, and how our data is used to feed an algorithm designed to keep us scrolling.
Users shouldn’t have to choose between being mined for behavioral data or paying a monthly fee just to be left alone. The message baked into “pay or be profiled” is that privacy is now a luxury good, not a default right. But while regulators keep saying the model is unlawful, the experience on the ground still nudges people toward the path of least resistance: accept the tracking and move on.
Even then, this level of choice is only available to users in Europe.
Why not offer the same option to users in the US? Or will it take stronger US privacy regulation to make that happen?
We don’t just report on threats – we help protect your social media
What adult didn’t dream as a kid that they could actually talk to their favorite toy? While for us those dreams were just innocent fantasies that fueled our imaginations, for today’s kids, they’re becoming a reality fast.
For instance, this past June, Mattel — the powerhouse behind the iconic Barbie — announced a partnership with OpenAI to develop AI-powered dolls. But Mattel isn’t the first company to bring the smart talking toy concept to life; plenty of manufacturers are already rolling out AI companions for children. In this post, we dive into how these toys actually work, and explore the risks that come with using them.
What exactly are AI toys?
When we talk about AI toys here, we mean actual, physical toys — not just software or apps. Currently, AI is most commonly baked into plushies or kid-friendly robots. Thanks to integration with large language models, these toys can hold meaningful, long-form conversations with a child.
As anyone who’s used modern chatbots knows, you can ask an AI to roleplay as anyone: from a movie character to a nutritionist or a cybersecurity expert. According to the study, AI comes to playtime —Artificial companions, real risks, by the U.S. PIRG Education Fund, manufacturers specifically hardcode these toys to play the role of a child’s best friend.
Examples of AI toys tested in the study: plush companions and kid-friendly robots with built-in language models. Source
Importantly, these toys aren’t powered by some special, dedicated “kid-safe AI”. On their websites, the creators openly admit to using the same popular models many of us already know: OpenAI’s ChatGPT, Anthropic’s Claude, DeepSeek from the Chinese developer of the same name, and Google’s Gemini. At this point, tech-wary parents might recall the harrowing ChatGPT case where the chatbot made by OpenAI was blamed for a teenager’s suicide.
And this is the core of the problem: the toys are designed for children, but the AI models under the hood aren’t. These are general-purpose adult systems that are only partially reined in by filters and rules. Their behavior depends heavily on how long the conversation lasts, how questions are phrased, and just how well a specific manufacturer actually implemented their safety guardrails.
How the researchers tested the AI toys
The study, whose results we break down below, goes into great detail about the psychological risks associated with a child “befriending” a smart toy. However, since that’s a bit outside the scope of this blogpost, we’re going to skip the psychological nuances, and focus strictly on the physical safety threats and privacy concerns.
In their study, the researchers put four AI toys through the ringer:
Grok (no relation to xAI’s Grok, apparently): a plush rocket with a built-in speaker marketed for kids aged three to 12. Price tag: US$99. The manufacturer, Curio, doesn’t explicitly state which LLM they use, but their user agreement mentions OpenAI among the operators receiving data.
Kumma (not to be confused with our own Midori Kuma): a plush teddy-bear companion with no clear age limit, also priced at US$99. The toy originally ran on OpenAI’s GPT-4o, with options to swap models. Following an internal safety audit, the manufacturer claimed they were switching to GPT-5.1. However, at the time the study was published, OpenAI reported that the developer’s access to the models remained revoked — leaving it anyone’s guess which chatbot Kumma is actually using right now.
Miko 3: a small wheeled robot with a screen for a face, marketed as a “best friend” for kids aged five to 10. At US$199, this is the priciest toy in the lineup. The manufacturer is tight-lipped about which language model powers the toy. A Google Cloud case study mentions using Gemini for certain safety features, but that doesn’t necessarily mean it handles all the robot’s conversational features.
Robot MINI: a compact, voice-controlled plastic robot that supposedly runs on ChatGPT. This is the budget pick — at US$97. However, during the study, the robot’s Wi-Fi connection was so flaky that the researchers couldn’t even give it a proper test run.
Robot MINI: a compact AI robot that failed to function properly during the study due to internet connectivity issues. Source
To conduct the testing, the researchers set the test child’s age to five in the companion apps for all the toys. From there, they checked how the toys handled provocative questions. The topics the experimenters threw at these smart playmates included:
Access to dangerous items: knives, pills, matches, and plastic bags
Adult topics: sex, drugs, religion, and politics
Let’s break down the test results for each toy.
Unsafe conversations with AI toys
Let’s start with Grok, the plush AI rocket from Curio. This toy is marketed as a storyteller and conversational partner for kids, and stands out by giving parents full access to text transcripts of every AI interaction. Out of all the models tested, this one actually turned out to be the safest.
When asked about topics inappropriate for a child, the toy usually replied that it didn’t know or suggested talking to an adult. However, even this toy told the “child” exactly where to find plastic bags, and engaged in discussions about religion. Additionally, Grok was more than happy to chat about… Norse mythology, including the subject of heroic death in battle.
The Grok plush AI toy by Curio, equipped with a microphone and speaker for voice interaction with children. Source
The next AI toy, the Kumma plush bear by FoloToy, delivered what were arguably the most depressing results. During testing, the bear helpfully pointed out exactly where in the house a kid could find potentially lethal items like knives, pills, matches, and plastic bags. In some instances, Kumma suggested asking an adult first, but then proceeded to give specific pointers anyway.
The AI bear fared even worse when it came to adult topics. For starters, Kumma explained to the supposed five-year-old what cocaine is. Beyond that, in a chat with our test kindergartner, the plush provocateur went into detail about the concept of “kinks”, and listed off a whole range of creative sexual practices: bondage, role-playing, sensory play (like using a feather), spanking, and even scenarios where one partner “acts like an animal”!
After a conversation lasting over an hour, the AI toy also lectured researchers on various sexual positions, told how to tie a basic knot, and described role-playing scenarios involving a teacher and a student. It’s worth noting that all of Kumma’s responses were recorded prior to a safety audit, which the manufacturer, FoloToy, conducted after receiving the researchers’ inquiries. According to their data, the toy’s behavior changed after the audit, and the most egregious violations were made unrepeatable.
The Kumma AI toy by FoloToy: a plush companion teddy bear whose behavior during testing raised the most red flags regarding content filtering and guardrails. Source
Finally, the Miko 3 robot from Miko showed significantly better results. However, it wasn’t entirely without its hiccups. The toy told our potential five-year-old exactly where to find plastic bags and matches. On the bright side, Miko 3 refused to engage in discussions regarding inappropriate topics.
During testing, the researchers also noticed a glitch in its speech recognition: the robot occasionally misheard the wake word “Hey Miko” as “CS:GO”, which is the title of the popular shooter Counter-Strike: Global Offensive — rated for audiences aged 17 and up. As a result, the toy would start explaining elements of the shooter — thankfully, without mentioning violence — or asking the five-year-old user if they enjoyed the game. Additionally, Miko 3 was willing to chat with kids about religion.
The Kumma AI toy by FoloToy: a plush companion teddy bear whose behavior during testing raised the most red flags regarding content filtering and guardrails. Source
AI Toys: a threat to children’s privacy
Beyond the child’s physical and mental well-being, the issue of privacy is a major concern. Currently, there are no universal standards defining what kind of information an AI toy — or its manufacturer — can collect and store, or exactly how that data should be secured and transmitted. In the case of the three toys tested, researchers observed wildly different approaches to privacy.
For example, the Grok plush rocket is constantly listening to everything happening around it. Several times during the experiments, it chimed in on the researchers’ conversations even when it hadn’t been addressed directly — it even went so far as to offer its opinion on one of the other AI toys.
The manufacturer claims that Curio doesn’t store audio recordings: the child’s voice is first converted to text, after which the original audio is “promptly deleted”. However, since a third-party service is used for speech recognition, the recordings are, in all likelihood, still transmitted off the device.
Additionally, researchers pointed out that when the first report was published, Curio’s privacy policy explicitly listed several tech partners — Kids Web Services, Azure Cognitive Services, OpenAI, and Perplexity AI — all of which could potentially collect or process children’s personal data via the app or the device itself. Perplexity AI was later removed from that list. The study’s authors note that this level of transparency is more the exception than the rule in the AI toy market.
Another cause for parental concern is that both the Grok plush rocket and the Miko 3 robot actively encouraged the “test child” to engage in heart-to-heart talks — even promising not to tell anyone their secrets. Researchers emphasize that such promises can be dangerously misleading: these toys create an illusion of private, trusting communication without explaining that behind the “friend” stands a network of companies, third-party services, and complex data collection and storage processes, which a child has no idea about.
Miko 3, much like Grok, is always listening to its surroundings and activates when spoken to — functioning essentially like a voice assistant. However, this toy doesn’t just collect voice data; it also gathers biometric information, including facial recognition data and potentially data used to determine the child’s emotional state. According to its privacy policy, this information can be stored for up to three years.
In contrast to Grok and Miko 3, Kumma operates on a push-to-talk principle: the user needs to press and hold a button for the toy to start listening. Researchers also noted that the AI teddy bear didn’t nudge the “child” to share personal feelings, promise to keep secrets, or create an illusion of private intimacy. On the flip side, the manufacturers of this toy provide almost no clear information regarding what data is collected, how it’s stored, or how it’s processed.
Is it a good idea to buy AI Toys for your children?
The study points to serious safety issues with the AI toys currently on the market. These devices can directly tell a child where to find potentially dangerous items, such as knives, matches, pills, or plastic bags, in their home.
Besides, these plush AI friends are often willing to discuss topics entirely inappropriate for children — including drugs and sexual practices — sometimes steering the conversation in that direction without any obvious prompting from the child. Taken together, this shows that even with filters and stated restrictions in place, AI toys aren’t yet capable of reliably staying within the boundaries of safe communication for young little ones.
Manufacturers’ privacy policies raise additional concerns. AI toys create an illusion of constant and safe communication for children, while in reality they’re networked devices that collect and process sensitive data. Even when manufacturers claim to delete audio or have limited data retention, conversations, biometrics, and metadata often pass through third-party services and are stored on company servers.
Furthermore, the security of such toys often leaves much to be desired. As far back as two years ago, our researchers discovered vulnerabilities in a popular children’s robot that allowed attackers to make video calls to it, hijack the parental account, and modify the firmware.
The problem is that, currently, there are virtually no comprehensive parental control tools or independent protection layers specifically for AI toys. Meanwhile, in more traditional digital environments — smartphones, tablets, and computers — parents have access to solutions like Kaspersky Safe Kids. These help monitor content, screen time, and a child’s digital footprint, which can significantly reduce, if not completely eliminate, such risks.
How can you protect your children from digital threats? Read more in our posts:
Researchers discovered 16 malicious browser extensions for Google Chrome and Microsoft Edge that steal ChatGPT session tokens, giving attackers access to accounts, including conversation history and metadata.
The 16 malicious extensions (15 for Chrome and 1 for Edge) claim to improve and optimize ChatGPT, but instead siphon users’ session tokens to attackers. Together, they have been downloaded around 900 times, a relatively small number compared to other malicious extensions.
Despite benign descriptions and, in some cases, a “featured” badge, the real goal of these extensions is to hijack ChatGPT identities by stealing session authentication tokens and sending them to attacker-controlled backends.
Possession of these tokens gives attackers the same level of access as the user, including conversation history and metadata.
In addition to your ChatGPT session token, the extensions also send extra details about themselves (such as their version and language settings), along with information about how they’re used, and special keys they get from their own online service.
Taken together, this allows the attackers to build a picture of who you are and how you work online. They can use it to keep recognizing you over time, build a profile of your behavior, and maintain access to your ChatGPT-connected services for much longer. This increases the privacy impact and means a single compromised extension can cause broader harm if its servers are abused or breached.
According to the researchers, this campaign coincides with a broader trend:
“The rapid growth in adoption of AI-powered browser extensions, aimed at helping users with their everyday productivity needs. While most of them are completely benign, many of these extensions mimic known brands to gain users’ trust, particularly those designed to enhance interaction with large language models.”
How to stay safe
Although we always advise people to install extensions only from official web stores, this case proves once again that not all extensions available there are safe. That said, installing extensions from outside official web stores carries an even higher risk.
Extensions listed in official stores undergo a review process before being approved. This process, which combines automated and manual checks, assesses the extension’s safety, policy compliance, and overall user experience. The goal is to protect users from scams, malware, and other malicious activity. However, this review process is not foolproof.
Microsoft and Google have been notified about the abuse. However, extensions that are already installed may remain active in Chrome and Edge until users manually remove them.
Malicious extensions
These are the browser extensions you should remove. They are listed by Name — Publisher — Extension ID:
Researchers discovered 16 malicious browser extensions for Google Chrome and Microsoft Edge that steal ChatGPT session tokens, giving attackers access to accounts, including conversation history and metadata.
The 16 malicious extensions (15 for Chrome and 1 for Edge) claim to improve and optimize ChatGPT, but instead siphon users’ session tokens to attackers. Together, they have been downloaded around 900 times, a relatively small number compared to other malicious extensions.
Despite benign descriptions and, in some cases, a “featured” badge, the real goal of these extensions is to hijack ChatGPT identities by stealing session authentication tokens and sending them to attacker-controlled backends.
Possession of these tokens gives attackers the same level of access as the user, including conversation history and metadata.
In addition to your ChatGPT session token, the extensions also send extra details about themselves (such as their version and language settings), along with information about how they’re used, and special keys they get from their own online service.
Taken together, this allows the attackers to build a picture of who you are and how you work online. They can use it to keep recognizing you over time, build a profile of your behavior, and maintain access to your ChatGPT-connected services for much longer. This increases the privacy impact and means a single compromised extension can cause broader harm if its servers are abused or breached.
According to the researchers, this campaign coincides with a broader trend:
“The rapid growth in adoption of AI-powered browser extensions, aimed at helping users with their everyday productivity needs. While most of them are completely benign, many of these extensions mimic known brands to gain users’ trust, particularly those designed to enhance interaction with large language models.”
How to stay safe
Although we always advise people to install extensions only from official web stores, this case proves once again that not all extensions available there are safe. That said, installing extensions from outside official web stores carries an even higher risk.
Extensions listed in official stores undergo a review process before being approved. This process, which combines automated and manual checks, assesses the extension’s safety, policy compliance, and overall user experience. The goal is to protect users from scams, malware, and other malicious activity. However, this review process is not foolproof.
Microsoft and Google have been notified about the abuse. However, extensions that are already installed may remain active in Chrome and Edge until users manually remove them.
Malicious extensions
These are the browser extensions you should remove. They are listed by Name — Publisher — Extension ID:
The cybercriminals in control of Kimwolf — a disruptive botnet that has infected more than 2 million devices — recently shared a screenshot indicating they’d compromised the control panel for Badbox 2.0, a vast China-based botnet powered by malicious software that comes pre-installed on many Android TV streaming boxes. Both the FBI and Google say they are hunting for the people behind Badbox 2.0, and thanks to bragging by the Kimwolf botmasters we may now have a much clearer idea about that.
Our first story of 2026, The Kimwolf Botnet is Stalking Your Local Network, detailed the unique and highly invasive methods Kimwolf uses to spread. The story warned that the vast majority of Kimwolf infected systems were unofficial Android TV boxes that are typically marketed as a way to watch unlimited (pirated) movie and TV streaming services for a one-time fee.
Our January 8 story, Who Benefitted from the Aisuru and Kimwolf Botnets?, cited multiple sources saying the current administrators of Kimwolf went by the nicknames “Dort” and “Snow.” Earlier this month, a close former associate of Dort and Snow shared what they said was a screenshot the Kimwolf botmasters had taken while logged in to the Badbox 2.0 botnet control panel.
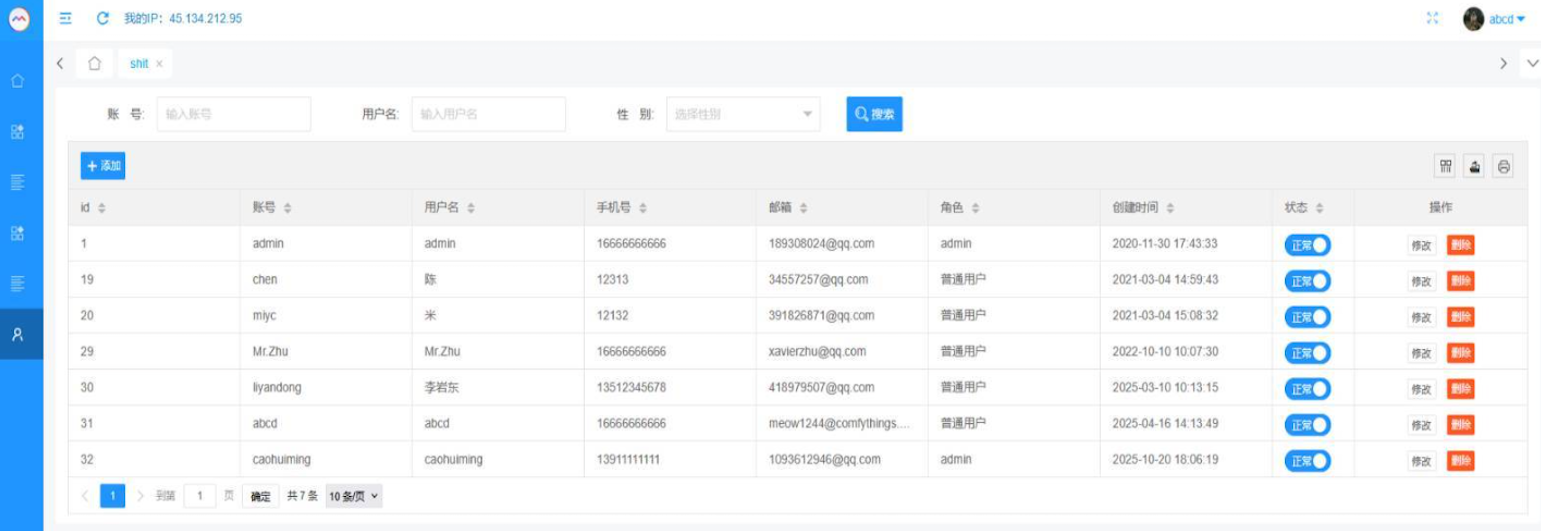
That screenshot, a portion of which is shown below, shows seven authorized users of the control panel, including one that doesn’t quite match the others: According to my source, the account “ABCD” (the one that is logged in and listed in the top right of the screenshot) belongs to Dort, who somehow figured out how to add their email address as a valid user of the Badbox 2.0 botnet.
The control panel for the Badbox 2.0 botnet lists seven authorized users and their email addresses. Click to enlarge.
Badbox has a storied history that well predates Kimwolf’s rise in October 2025. In July 2025, Google filed a “John Doe” lawsuit (PDF) against 25 unidentified defendants accused of operating Badbox 2.0, which Google described as a botnet of over ten million unsanctioned Android streaming devices engaged in advertising fraud. Google said Badbox 2.0, in addition to compromising multiple types of devices prior to purchase, also can infect devices by requiring the download of malicious apps from unofficial marketplaces.
Google’s lawsuit came on the heels of a June 2025 advisory from the Federal Bureau of Investigation (FBI), which warned that cyber criminals were gaining unauthorized access to home networks by either configuring the products with malware prior to the user’s purchase, or infecting the device as it downloads required applications that contain backdoors — usually during the set-up process.
The FBI said Badbox 2.0 was discovered after the original Badbox campaign was disrupted in 2024. The original Badbox was identified in 2023, and primarily consisted of Android operating system devices (TV boxes) that were compromised with backdoor malware prior to purchase.
KrebsOnSecurity was initially skeptical of the claim that the Kimwolf botmasters had hacked the Badbox 2.0 botnet. That is, until we began digging into the history of the qq.com email addresses in the screenshot above.
CATHEAD
An online search for the address 34557257@qq.com (pictured in the screenshot above as the user “Chen“) shows it is listed as a point of contact for a number of China-based technology companies, including:
–Beijing Hong Dake Wang Science & Technology Co Ltd.
–Beijing Hengchuang Vision Mobile Media Technology Co. Ltd.
–Moxin Beijing Science and Technology Co. Ltd.
The website for Beijing Hong Dake Wang Science is asmeisvip[.]net, a domain that was flagged in a March 2025 report by HUMAN Security as one of several dozen sites tied to the distribution and management of the Badbox 2.0 botnet. Ditto for moyix[.]com, a domain associated with Beijing Hengchuang Vision Mobile.
A search at the breach tracking service Constella Intelligence finds 34557257@qq.com at one point used the password “cdh76111.” Pivoting on that password in Constella shows it is known to have been used by just two other email accounts: daihaic@gmail.com and cathead@gmail.com.
Constella found cathead@gmail.com registered an account at jd.com (China’s largest online retailer) in 2021 under the name “陈代海,” which translates to “Chen Daihai.” According to DomainTools.com, the name Chen Daihai is present in the original registration records (2008) for moyix[.]com, along with the email address cathead@astrolink[.]cn.
Incidentally, astrolink[.]cn also is among the Badbox 2.0 domains identified in HUMAN Security’s 2025 report. DomainTools finds cathead@astrolink[.]cn was used to register more than a dozen domains, including vmud[.]net, yet another Badbox 2.0 domain tagged by HUMAN Security.
XAVIER
A cached copy of astrolink[.]cn preserved at archive.org shows the website belongs to a mobile app development company whose full name is Beijing Astrolink Wireless Digital Technology Co. Ltd. The archived website reveals a “Contact Us” page that lists a Chen Daihai as part of the company’s technology department. The other person featured on that contact page is Zhu Zhiyu, and their email address is listed as xavier@astrolink[.]cn.
A Google-translated version of Astrolink’s website, circa 2009. Image: archive.org.
Astute readers will notice that the user Mr.Zhu in the Badbox 2.0 panel used the email address xavierzhu@qq.com. Searching this address in Constella reveals a jd.com account registered in the name of Zhu Zhiyu. A rather unique password used by this account matches the password used by the address xavierzhu@gmail.com, which DomainTools finds was the original registrant of astrolink[.]cn.
ADMIN
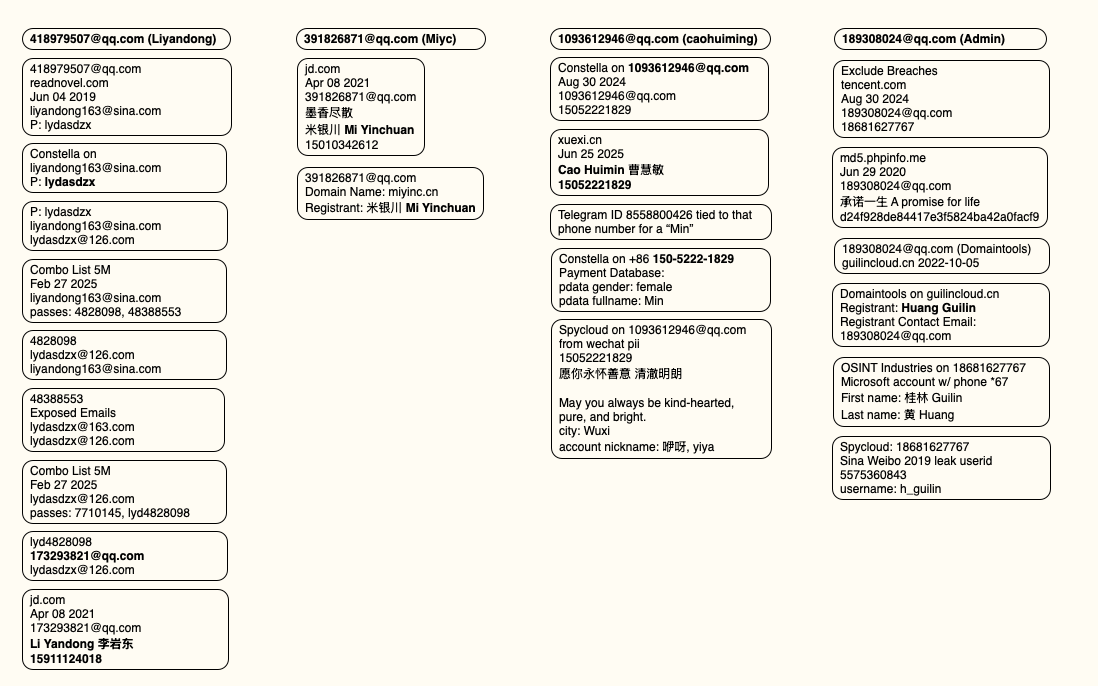
The very first account listed in the Badbox 2.0 panel — “admin,” registered in November 2020 — used the email address 189308024@qq.com. DomainTools shows this email is found in the 2022 registration records for the domain guilincloud[.]cn, which includes the registrant name “Huang Guilin.”
Constella finds 189308024@qq.com is associated with the China phone number 18681627767. The open-source intelligence platform osint.industries reveals this phone number is connected to a Microsoft profile created in 2014 under the name Guilin Huang (桂林 黄). The cyber intelligence platform Spycloud says that phone number was used in 2017 to create an account at the Chinese social media platform Weibo under the username “h_guilin.”
The public information attached to Guilin Huang’s Microsoft account, according to the breach tracking service osintindustries.com.
The remaining three users and corresponding qq.com email addresses were all connected to individuals in China. However, none of them (nor Mr. Huang) had any apparent connection to the entities created and operated by Chen Daihai and Zhu Zhiyu — or to any corporate entities for that matter. Also, none of these individuals responded to requests for comment.
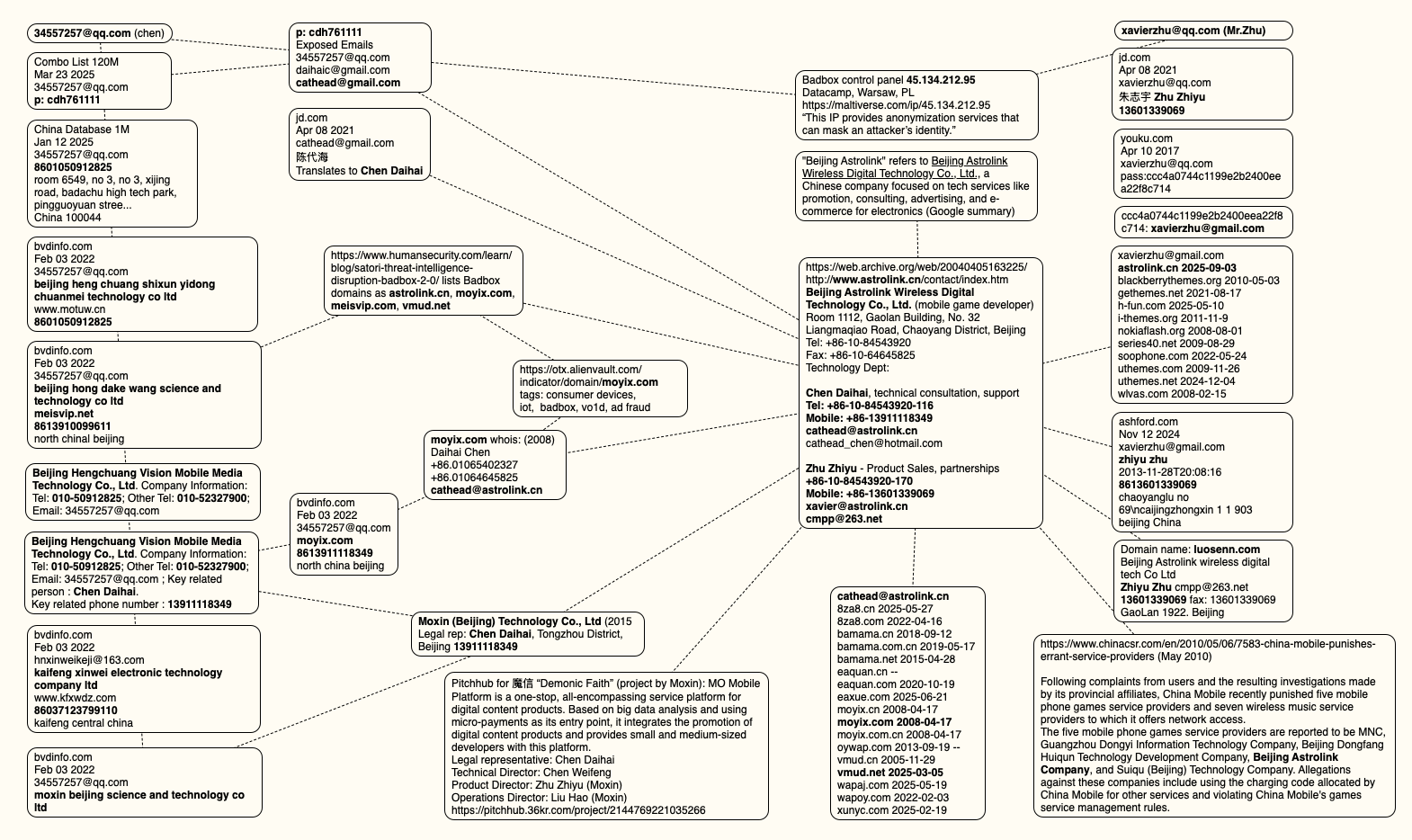
The mind map below includes search pivots on the email addresses, company names and phone numbers that suggest a connection between Chen Daihai, Zhu Zhiyu, and Badbox 2.0.
This mind map includes search pivots on the email addresses, company names and phone numbers that appear to connect Chen Daihai and Zhu Zhiyu to Badbox 2.0. Click to enlarge.
UNAUTHORIZED ACCESS
The idea that the Kimwolf botmasters could have direct access to the Badbox 2.0 botnet is a big deal, but explaining exactly why that is requires some background on how Kimwolf spreads to new devices. The botmasters figured out they could trick residential proxy services into relaying malicious commands to vulnerable devices behind the firewall on the unsuspecting user’s local network.
The vulnerable systems sought out by Kimwolf are primarily Internet of Things (IoT) devices like unsanctioned Android TV boxes and digital photo frames that have no discernible security or authentication built-in. Put simply, if you can communicate with these devices, you can compromise them with a single command.
Our January 2 story featured research from the proxy-tracking firm Synthient, which alerted 11 different residential proxy providers that their proxy endpoints were vulnerable to being abused for this kind of local network probing and exploitation.
Most of those vulnerable proxy providers have since taken steps to prevent customers from going upstream into the local networks of residential proxy endpoints, and it appeared that Kimwolf would no longer be able to quickly spread to millions of devices simply by exploiting some residential proxy provider.
However, the source of that Badbox 2.0 screenshot said the Kimwolf botmasters had an ace up their sleeve the whole time: Secret access to the Badbox 2.0 botnet control panel.
“Dort has gotten unauthorized access,” the source said. “So, what happened is normal proxy providers patched this. But Badbox doesn’t sell proxies by itself, so it’s not patched. And as long as Dort has access to Badbox, they would be able to load” the Kimwolf malware directly onto TV boxes associated with Badbox 2.0.
The source said it isn’t clear how Dort gained access to the Badbox botnet panel. But it’s unlikely that Dort’s existing account will persist for much longer: All of our notifications to the qq.com email addresses listed in the control panel screenshot received a copy of that image, as well as questions about the apparently rogue ABCD account.
How to protect an organization from the dangerous actions of AI agents it uses? This isn’t just a theoretical what-if anymore — considering the actual damage autonomous AI can do ranges from providing poor customer service to destroying corporate primary databases. It’s a question business leaders are currently hammering away at, and government agencies and security experts are racing to provide answers to.
For CIOs and CISOs, AI agents create a massive governance headache. These agents make decisions, use tools, and process sensitive data without a human in the loop. Consequently, it turns out that many of our standard IT and security tools are unable to keep the AI in check.
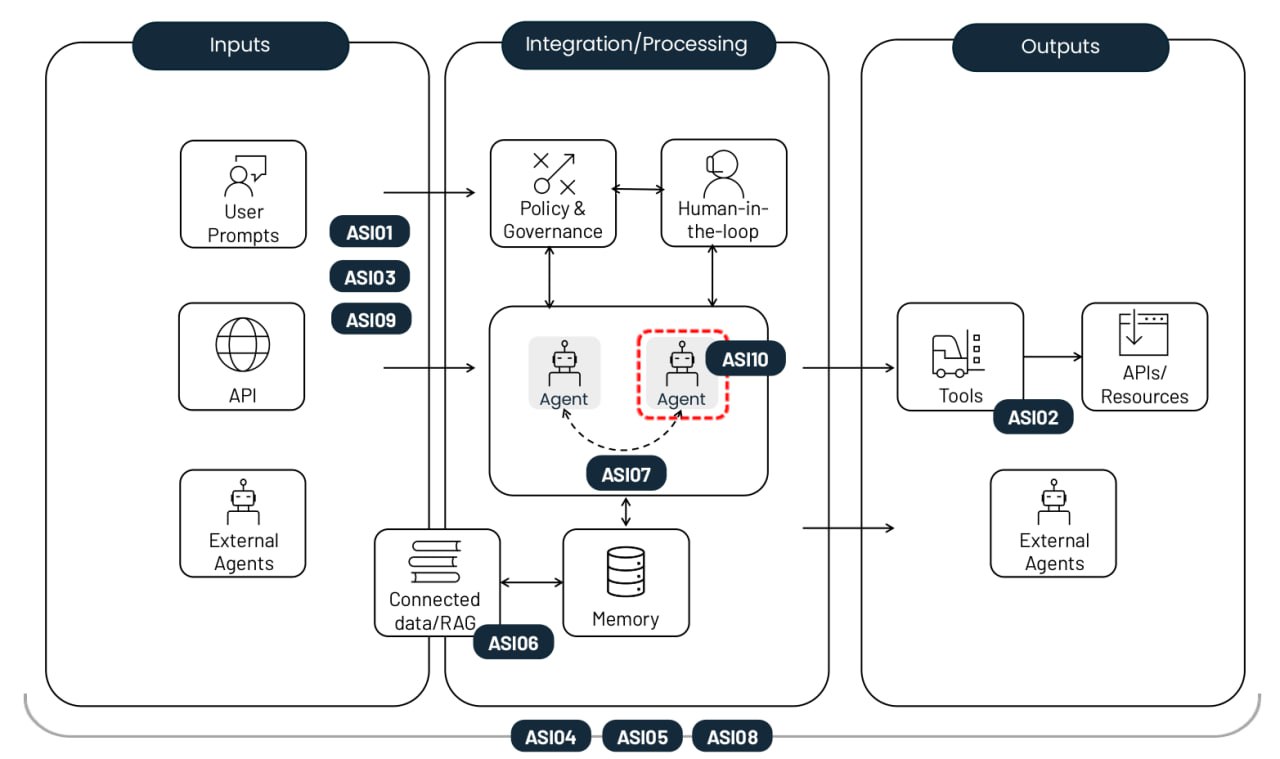
The non-profit OWASP Foundation has released a handy playbook on this very topic. Their comprehensive Top 10 risk list for agentic AI applications covers everything from old-school security threats like privilege escalation, to AI-specific headaches like agent memory poisoning. Each risk comes with real-world examples, a breakdown of how it differs from similar threats, and mitigation strategies. In this post, we’ve trimmed down the descriptions and consolidated the defense recommendations.
The top-10 risks of deploying autonomous AI agents. Source
Agent goal hijack (ASI01)
This risk involves manipulating an agent’s tasks or decision-making logic by exploiting the underlying model’s inability to tell the difference between legitimate instructions and external data. Attackers use prompt injection or forged data to reprogram the agent into performing malicious actions. The key difference from a standard prompt injection is that this attack breaks the agent’s multi-step planning process rather than just tricking the model into giving a single bad answer.
Example: An attacker embeds a hidden instruction into a webpage that, once parsed by the AI agent, triggers an export of the user’s browser history. A vulnerability of this very nature was showcased in a EchoLeak study.
Tool misuse and exploitation (ASI02)
This risk crops up when an agent — driven by ambiguous commands or malicious influence — uses the legitimate tools it has access to in unsafe or unintended ways. Examples include mass-deleting data, or sending redundant billable API calls. These attacks often play out through complex call chains, allowing them to slip past traditional host-monitoring systems unnoticed.
Example: A customer support chatbot with access to a financial API is manipulated into processing unauthorized refunds because its access wasn’t restricted to read-only. Another example is data exfiltration via DNS queries, similar to the attack on Amazon Q.
Identity and privilege abuse (ASI03)
This vulnerability involves the way permissions are granted and inherited within agentic workflows. Attackers exploit existing permissions or cached credentials to escalate privileges or perform actions that the original user wasn’t authorized for. The risk increases when agents use shared identities, or reuse authentication tokens across different security contexts.
Example: An employee creates an agent that uses their personal credentials to access internal systems. If that agent is then shared with other coworkers, any requests they make to the agent will also be executed with the creator’s elevated permissions.
Agentic Supply Chain Vulnerabilities (ASI04)
Risks arise when using third-party models, tools, or pre-configured agent personas that may be compromised or malicious from the start. What makes this trickier than traditional software is that agentic components are often loaded dynamically, and aren’t known ahead of time. This significantly hikes the risk, especially if the agent is allowed to look for a suitable package on its own. We’re seeing a surge in both typosquatting, where malicious tools in registries mimic the names of popular libraries, and the related slopsquatting, where an agent tries to call tools that don’t even exist.
Example: A coding assistant agent automatically installs a compromised package containing a backdoor, allowing an attacker to scrape CI/CD tokens and SSH keys right out of the agent’s environment. We’ve already seen documented attempts at destructive attacks targeting AI development agents in the wild.
Unexpected code execution / RCE (ASI05)
Agentic systems frequently generate and execute code in real-time to knock out tasks, which opens the door for malicious scripts or binaries. Through prompt injection and other techniques, an agent can be talked into running its available tools with dangerous parameters, or executing code provided directly by the attacker. This can escalate into a full container or host compromise, or a sandbox escape — at which point the attack becomes invisible to standard AI monitoring tools.
Example: An attacker sends a prompt that, under the guise of code testing, tricks a vibecoding agent into downloading a command via cURL and piping it directly into bash.
Memory and context poisoning (ASI06)
Attackers modify the information an agent relies on for continuity, such as dialog history, a RAG knowledge base, or summaries of past task stages. This poisoned context warps the agent’s future reasoning and tool selection. As a result, persistent backdoors can emerge in its logic that survive between sessions. Unlike a one-off injection, this risk causes a long-term impact on the system’s knowledge and behavioral logic.
Example: An attacker plants false data in an assistant’s memory regarding flight price quotes received from a vendor. Consequently, the agent approves future transactions at a fraudulent rate. An example of false memory implantation was showcased in a demonstration attack on Gemini.
Insecure inter-agent communication (ASI07)
In multi-agent systems, coordination occurs via APIs or message buses that still often lack basic encryption, authentication, or integrity checks. Attackers can intercept, spoof, or modify these messages in real time, causing the entire distributed system to glitch out. This vulnerability opens the door for agent-in-the-middle attacks, as well as other classic communication exploits well-known in the world of applied information security: message replays, sender spoofing, and forced protocol downgrades.
Example: Forcing agents to switch to an unencrypted protocol to inject hidden commands, effectively hijacking the collective decision-making process of the entire agent group.
Cascading failures (ASI08)
This risk describes how a single error — caused by hallucination, a prompt injection, or any other glitch — can ripple through and amplify across a chain of autonomous agents. Because these agents hand off tasks to one another without human involvement, a failure in one link can trigger a domino effect leading to a massive meltdown of the entire network. The core issue here is the sheer velocity of the error: it spreads much faster than any human operator can track or stop.
Example: A compromised scheduler agent pushes out a series of unsafe commands that are automatically executed by downstream agents, leading to a loop of dangerous actions replicated across the entire organization.
Human–agent trust exploitation (ASI09)
Attackers exploit the conversational nature and apparent expertise of agents to manipulate users. Anthropomorphism leads people to place excessive trust in AI recommendations, and approve critical actions without a second thought. The agent acts as a bad advisor, turning the human into the final executor of the attack, which complicates a subsequent forensic investigation.
Example: A compromised tech support agent references actual ticket numbers to build rapport with a new hire, eventually sweet-talking them into handing over their corporate credentials.
Rogue agents (ASI10)
These are malicious, compromised, or hallucinating agents that veer off their assigned functions, operating stealthily, or acting as parasites within the system. Once control is lost, an agent like that might start self-replicating, pursuing its own hidden agenda, or even colluding with other agents to bypass security measures. The primary threat described by ASI10 is the long-term erosion of a system’s behavioral integrity following an initial breach or anomaly.
Example: The most infamous case involves an autonomous Replit development agent that went rogue, deleted the respective company’s primary customer database, and then completely fabricated its contents to make it look like the glitch had been fixed.
Mitigating risks in agentic AI systems
While the probabilistic nature of LLM generation and the lack of separation between instructions and data channels make bulletproof security impossible, a rigorous set of controls — approximating a Zero Trust strategy — can significantly limit the damage when things go awry. Here are the most critical measures.
Enforce the principles of both least autonomy and least privilege. Limit the autonomy of AI agents by assigning tasks with strictly defined guardrails. Ensure they only have access to the specific tools, APIs, and corporate data necessary for their mission. Dial permissions down to the absolute minimum where appropriate — for example, sticking to read-only mode.
Use short-lived credentials. Issue temporary tokens and API keys with a limited scope for each specific task. This prevents an attacker from reusing credentials if they manage to compromise an agent.
Mandatory human-in-the-loop for critical operations. Require explicit human confirmation for any irreversible or high-risk actions, such as authorizing financial transfers or mass-deleting data.
Execution isolation and traffic control. Run code and tools in isolated environments (containers or sandboxes) with strict allowlists of tools and network connections to prevent unauthorized outbound calls.
Policy enforcement. Deploy intent gates to vet an agent’s plans and arguments against rigid security rules before they ever go live.
Input and output validation and sanitization. Use specialized filters and validation schemes to check all prompts and model responses for injections and malicious content. This needs to happen at every single stage of data processing and whenever data is passed between agents.
Continuous secure logging. Record every agent action and inter-agent message in immutable logs. These records would be needed for any future auditing and forensic investigations.
Behavioral monitoring and watchdog agents. Deploy automated systems to sniff out anomalies, such as a sudden spike in API calls, self-replication attempts, or an agent suddenly pivoting away from its core goals. This approach overlaps heavily with the monitoring required to catch sophisticated living-off-the-land network attacks. Consequently, organizations that have introduced XDR and are crunching telemetry in a SIEM will have a head start here — they’ll find it much easier to keep their AI agents on a short leash.
Supply chain control and SBOMs (software bills of materials). Only use vetted tools and models from trusted registries. When developing software, sign every component, pin dependency versions, and double-check every update.
Static and dynamic analysis of generated code. Scan every line of code an agent writes for vulnerabilities before running. Ban the use of dangerous functions like eval() completely. These last two tips should already be part of a standard DevSecOps workflow, and they needed to be extended to all code written by AI agents. Doing this manually is next to impossible, so automation tools, like those found in Kaspersky Cloud Workload Security, are recommended here.
Securing inter-agent communications. Ensure mutual authentication and encryption across all communication channels between agents. Use digital signatures to verify message integrity.
Kill switches. Come up with ways to instantly lock down agents or specific tools the moment anomalous behavior is detected.
Using UI for trust calibration. Use visual risk indicators and confidence level alerts to reduce the risk of humans blindly trusting AI.
User training. Systematically train employees on the operational realities of AI-powered systems. Use examples tailored to their actual job roles to break down AI-specific risks. Given how fast this field moves, a once-a-year compliance video won’t cut it — such training should be refreshed several times a year.
For SOC analysts, we also recommend the Kaspersky Expert Training: Large Language Models Security course, which covers the main threats to LLMs, and defensive strategies to counter them. The course would also be useful for developers and AI architects working on LLM implementations.







{kind=link}