On the surface, the Superbox media streaming devices for sale at retailers like BestBuy and Walmart may seem like a steal: They offer unlimited access to more than 2,200 pay-per-view and streaming services like Netflix, ESPN and Hulu, all for a one-time fee of around $400. But security experts warn these TV boxes require intrusive software that forces the user’s network to relay Internet traffic for others, traffic that is often tied to cybercrime activity such as advertising fraud and account takeovers.

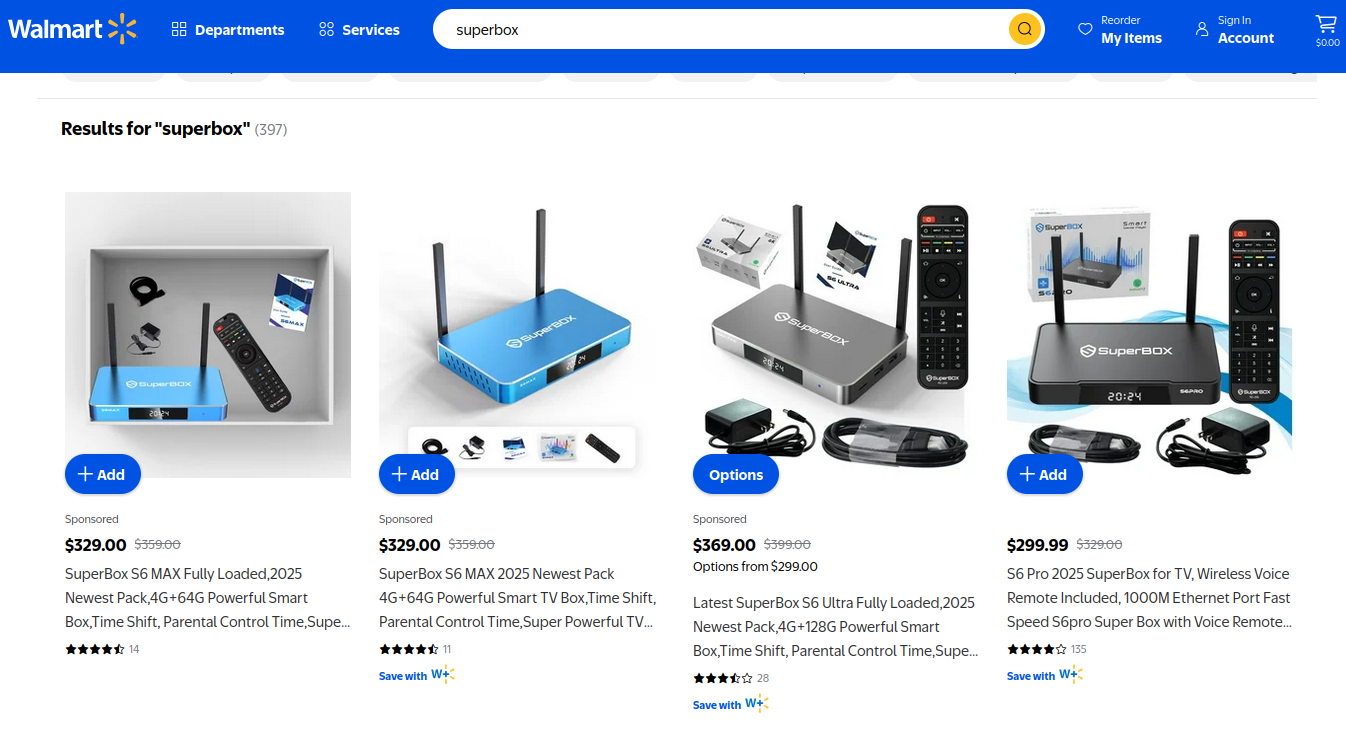
Superbox media streaming boxes for sale on Walmart.com.
Superbox bills itself as an affordable way for households to stream all of the television and movie content they could possibly want, without the hassle of monthly subscription fees — for a one-time payment of nearly $400.
“Tired of confusing cable bills and hidden fees?,” Superbox’s website asks in a recent blog post titled, “Cheap Cable TV for Low Income: Watch TV, No Monthly Bills.”
“Real cheap cable TV for low income solutions does exist,” the blog continues. “This guide breaks down the best alternatives to stop overpaying, from free over-the-air options to one-time purchase devices that eliminate monthly bills.”
Superbox claims that watching a stream of movies, TV shows, and sporting events won’t violate U.S. copyright law.
“SuperBox is just like any other Android TV box on the market, we can not control what software customers will use,” the company’s website maintains. “And you won’t encounter a law issue unless uploading, downloading, or broadcasting content to a large group.”
A blog post from the Superbox website.
There is nothing illegal about the sale or use of the Superbox itself, which can be used strictly as a way to stream content at providers where users already have a paid subscription. But that is not why people are shelling out $400 for these machines. The only way to watch those 2,200+ channels for free with a Superbox is to install several apps made for the device that enable them to stream this content.
Superbox’s homepage includes a prominent message stating the company does “not sell access to or preinstall any apps that bypass paywalls or provide access to unauthorized content.” The company explains that they merely provide the hardware, while customers choose which apps to install.
“We only sell the hardware device,” the notice states. “Customers must use official apps and licensed services; unauthorized use may violate copyright law.”
Superbox is technically correct here, except for maybe the part about how customers must use official apps and licensed services: Before the Superbox can stream those thousands of channels, users must configure the device to update itself, and the first step involves ripping out Google’s official Play store and replacing it with something called the “App Store” or “Blue TV Store.”
Superbox does this because the device does not use the official Google-certified Android TV system, and its apps will not load otherwise. Only after the Google Play store has been supplanted by this unofficial App Store do the various movie and video streaming apps that are built specifically for the Superbox appear available for download (again, outside of Google’s app ecosystem).
Experts say while these Android streaming boxes generally do what they advertise — enabling buyers to stream video content that would normally require a paid subscription — the apps that enable the streaming also ensnare the user’s Internet connection in a distributed residential proxy network that uses the devices to relay traffic from others.
Ashley is a senior solutions engineer at Censys, a cyber intelligence company that indexes Internet-connected devices, services and hosts. Ashley requested that only her first name be used in this story.
In a recent video interview, Ashley showed off several Superbox models that Censys was studying in the malware lab — including one purchased off the shelf at BestBuy.
“I’m sure a lot of people are thinking, ‘Hey, how bad could it be if it’s for sale at the big box stores?'” she said. “But the more I looked, things got weirder and weirder.”
Ashley said she found the Superbox devices immediately contacted a server at the Chinese instant messaging service Tencent QQ, as well as a residential proxy service called Grass IO.
GET GRASSED
Also known as getgrass[.]io, Grass says it is “a decentralized network that allows users to earn rewards by sharing their unused Internet bandwidth with AI labs and other companies.”
“Buyers seek unused internet bandwidth to access a more diverse range of IP addresses, which enables them to see certain websites from a retail perspective,” the Grass website explains. “By utilizing your unused internet bandwidth, they can conduct market research, or perform tasks like web scraping to train AI.”
Reached via Twitter/X, Grass founder Andrej Radonjic told KrebsOnSecurity he’d never heard of a Superbox, and that Grass has no affiliation with the device maker.
“It looks like these boxes are distributing an unethical proxy network which people are using to try to take advantage of Grass,” Radonjic said. “The point of grass is to be an opt-in network. You download the grass app to monetize your unused bandwidth. There are tons of sketchy SDKs out there that hijack people’s bandwidth to help webscraping companies.”
Radonjic said Grass has implemented “a robust system to identify network abusers,” and that if it discovers anyone trying to misuse or circumvent its terms of service, the company takes steps to stop it and prevent those users from earning points or rewards.
Superbox’s parent company, Super Media Technology Company Ltd., lists its street address as a UPS store in Fountain Valley, Calif. The company did not respond to multiple inquiries.
According to this teardown by behindmlm.com, a blog that covers multi-level marketing (MLM) schemes, Grass’s compensation plan is built around “grass points,” which are earned through the use of the Grass app and through app usage by recruited affiliates. Affiliates can earn 5,000 grass points for clocking 100 hours usage of Grass’s app, but they must progress through ten affiliate tiers or ranks before they can redeem their grass points (presumably for some type of cryptocurrency). The 10th or “Titan” tier requires affiliates to accumulate a whopping 50 million grass points, or recruit at least 221 more affiliates.
Radonjic said Grass’s system has changed in recent months, and confirmed the company has a referral program where users can earn Grass Uptime Points by contributing their own bandwidth and/or by inviting other users to participate.
“Users are not required to participate in the referral program to earn Grass Uptime Points or to receive Grass Tokens,” Radonjic said. “Grass is in the process of phasing out the referral program and has introduced an updated Grass Points model.”
A review of the Terms and Conditions page for getgrass[.]io at the Wayback Machine shows Grass’s parent company has changed names at least five times in the course of its two-year existence. Searching the Wayback Machine on getgrass[.]io shows that in June 2023 Grass was owned by a company called Wynd Network. By March 2024, the owner was listed as Lower Tribeca Corp. in the Bahamas. By August 2024, Grass was controlled by a Half Space Labs Limited, and in November 2024 the company was owned by Grass OpCo (BVI) Ltd. Currently, the Grass website says its parent is just Grass OpCo Ltd (no BVI in the name).
Radonjic acknowledged that Grass has undergone “a handful of corporate clean-ups over the last couple of years,” but described them as administrative changes that had no operational impact. “These reflect normal early-stage restructuring as the project moved from initial development…into the current structure under the Grass Foundation,” he said.
UNBOXING
Censys’s Ashley said the phone home to China’s Tencent QQ instant messaging service was the first red flag with the Superbox devices she examined. She also discovered the streaming boxes included powerful network analysis and remote access tools, such as Tcpdump and Netcat.
“This thing DNS hijacked my router, did ARP poisoning to the point where things fall off the network so they can assume that IP, and attempted to bypass controls,” she said. “I have root on all of them now, and they actually have a folder called ‘secondstage.’ These devices also have Netcat and Tcpdump on them, and yet they are supposed to be streaming devices.”
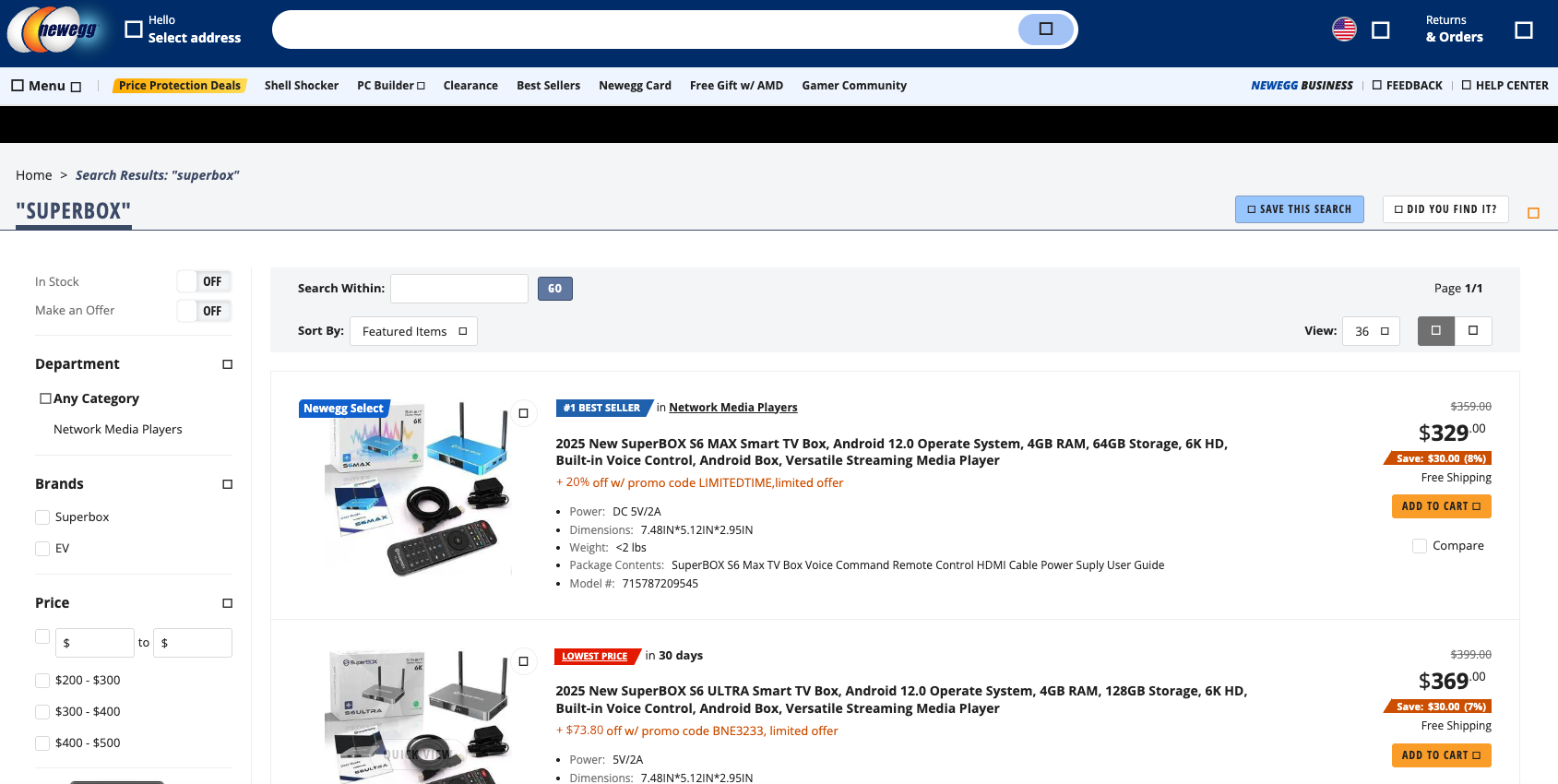
A quick online search shows various Superbox models and many similar Android streaming devices for sale at a wide range of top retail destinations, including Amazon, BestBuy, Newegg, and Walmart. Newegg.com, for example, currently lists more than three dozen Superbox models. In all cases, the products are sold by third-party merchants on these platforms, but in many instances the fulfillment comes from the e-commerce platform itself.
“Newegg is pretty bad now with these devices,” Ashley said. “Ebay is the funniest, because they have Superbox in Spanish — the SuperCaja — which is very popular.”
Superbox devices for sale via Newegg.com.
Ashley said Amazon recently cracked down on Android streaming devices branded as Superbox, but that those listings can still be found under the more generic title “modem and router combo” (which may be slightly closer to the truth about the device’s behavior).
Superbox doesn’t advertise its products in the conventional sense. Rather, it seems to rely on lesser-known influencers on places like Youtube and TikTok to promote the devices. Meanwhile, Ashley said, Superbox pays those influencers 50 percent of the value of each device they sell.
“It’s weird to me because influencer marketing usually caps compensation at 15 percent, and it means they don’t care about the money,” she said. “This is about building their network.”
A TikTok influencer casually mentions and promotes Superbox while chatting with her followers over a glass of wine.
BADBOX
As plentiful as the Superbox is on e-commerce sites, it is just one brand in an ocean of no-name Android-based TV boxes available to consumers. While these devices generally do provide buyers with “free” streaming content, they also tend to include factory-installed malware or require the installation of third-party apps that engage the user’s Internet address in advertising fraud.
In July 2025, Google filed a “John Doe” lawsuit (PDF) against 25 unidentified defendants dubbed the “BadBox 2.0 Enterprise,” which Google described as a botnet of over ten million Android streaming devices that engaged in advertising fraud. Google said the BADBOX 2.0 botnet, in addition to compromising multiple types of devices prior to purchase, can also infect devices by requiring the download of malicious apps from unofficial marketplaces.
Some of the unofficial Android devices flagged by Google as part of the Badbox 2.0 botnet are still widely for sale at major e-commerce vendors. Image: Google.
Several of the Android streaming devices flagged in Google’s lawsuit are still for sale on top U.S. retail sites. For example, searching for the “X88Pro 10” and the “T95” Android streaming boxes finds both continue to be peddled by Amazon sellers.
Google’s lawsuit came on the heels of a June 2025 advisory from the Federal Bureau of Investigation (FBI), which warned that cyber criminals were gaining unauthorized access to home networks by either configuring the products with malicious software prior to the user’s purchase, or infecting the device as it downloads required applications that contain backdoors, usually during the set-up process.
“Once these compromised IoT devices are connected to home networks, the infected devices are susceptible to becoming part of the BADBOX 2.0 botnet and residential proxy services known to be used for malicious activity,” the FBI said.
The FBI said BADBOX 2.0 was discovered after the original BADBOX campaign was disrupted in 2024. The original BADBOX was identified in 2023, and primarily consisted of Android operating system devices that were compromised with backdoor malware prior to purchase.
Riley Kilmer is founder of Spur, a company that tracks residential proxy networks. Kilmer said Badbox 2.0 was used as a distribution platform for IPidea, a China-based entity that is now the world’s largest residential proxy network.
Kilmer and others say IPidea is merely a rebrand of 911S5 Proxy, a China-based proxy provider sanctioned last year by the U.S. Department of the Treasury for operating a botnet that helped criminals steal billions of dollars from financial institutions, credit card issuers, and federal lending programs (the U.S. Department of Justice also arrested the alleged owner of 911S5).
How are most IPidea customers using the proxy service? According to the proxy detection service Synthient, six of the top ten destinations for IPidea proxies involved traffic that has been linked to either ad fraud or credential stuffing (account takeover attempts).
Kilmer said companies like Grass are probably being truthful when they say that some of their customers are companies performing web scraping to train artificial intelligence efforts, because a great deal of content scraping which ultimately benefits AI companies is now leveraging these proxy networks to further obfuscate their aggressive data-slurping activity. By routing this unwelcome traffic through residential IP addresses, Kilmer said, content scraping firms can make it far trickier to filter out.
“Web crawling and scraping has always been a thing, but AI made it like a commodity, data that had to be collected,” Kilmer told KrebsOnSecurity. “Everybody wanted to monetize their own data pots, and how they monetize that is different across the board.”
SOME FRIENDLY ADVICE
Products like Superbox are drawing increased interest from consumers as more popular network television shows and sportscasts migrate to subscription streaming services, and as people begin to realize they’re spending as much or more on streaming services than they previously paid for cable or satellite TV.
These streaming devices from no-name technology vendors are another example of the maxim, “If something is free, you are the product,” meaning the company is making money by selling access to and/or information about its users and their data.
Superbox owners might counter, “Free? I paid $400 for that device!” But remember: Just because you paid a lot for something doesn’t mean you are done paying for it, or that somehow you are the only one who might be worse off from the transaction.
It may be that many Superbox customers don’t care if someone uses their Internet connection to tunnel traffic for ad fraud and account takeovers; for them, it beats paying for multiple streaming services each month. My guess, however, is that quite a few people who buy (or are gifted) these products have little understanding of the bargain they’re making when they plug them into an Internet router.
Superbox performs some serious linguistic gymnastics to claim its products don’t violate copyright laws, and that its customers alone are responsible for understanding and observing any local laws on the matter. However, buyer beware: If you’re a resident of the United States, you should know that using these devices for unauthorized streaming violates the Digital Millennium Copyright Act (DMCA), and can incur legal action, fines, and potential warnings and/or suspension of service by your Internet service provider.
According to the FBI, there are several signs to look for that may indicate a streaming device you own is malicious, including:
-The presence of suspicious marketplaces where apps are downloaded.
-Requiring Google Play Protect settings to be disabled.
-Generic TV streaming devices advertised as unlocked or capable of accessing free content.
-IoT devices advertised from unrecognizable brands.
-Android devices that are not Play Protect certified.
-Unexplained or suspicious Internet traffic.
This explainer from the Electronic Frontier Foundation delves a bit deeper into each of the potential symptoms listed above.