
The Five Phases of the Threat Intelligence Lifecycle
Blog
The Five Phases of the Threat Intelligence Lifecycle: A Strategic Guide
The threat intelligence lifecycle is a fundamental framework for all fraud, physical, and cybersecurity programs. It is useful whether a program is mature and sophisticated or just starting out.
What is the Core Purpose of the Threat Intelligence Lifecycle?
The threat intelligence lifecycle is a foundational framework for all fraud, physical security, and cybersecurity programs at every stage of maturity. It provides a structured way to understand how intelligence is defined, built, and applied to support real-world decisions.
At a high level, the lifecycle outlines how organizations move from questions to insight to action. Rather than focusing on tools or outputs alone, it emphasizes the practices required to produce intelligence that is relevant, timely, and trusted. This iterative, adaptable methodology consists of five stages that guide how intelligence requirements are set, how information is collected and analyzed, how insight reaches decision-makers, and how priorities are continuously refined based on feedback and changing risk conditions.
The Five Phases of the Threat Intelligence Lifecycle
Key Objectives at Each Phase of the Threat Intelligence Lifecycle
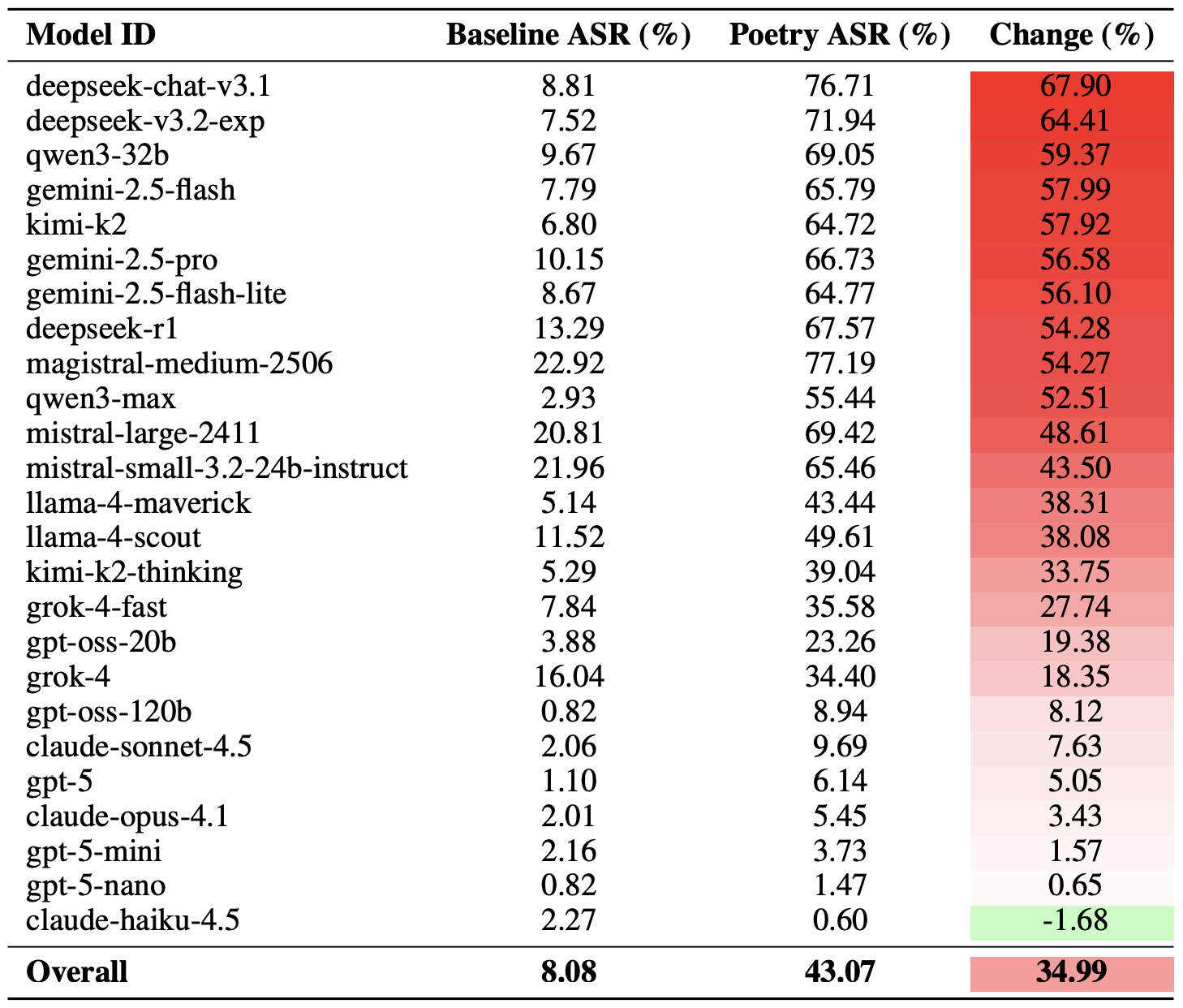
- Requirements & Tasking: Define what intelligence needs to answer and why. This phase establishes clear priorities tied to business risk, assets, and stakeholder needs, providing direction for all downstream intelligence activity.
- Collection & Discovery: Gather relevant information from internal and external sources and expand visibility as threats evolve. This includes identifying new sources, closing visibility gaps, and ensuring coverage aligns with defined intelligence requirements.
- Analysis & Prioritization: Transform collections into insight by connecting signals, context, and impact. Analysts assess relevance, likelihood, and business significance to determine which threats, actors, or exposures matter most.
- Dissemination & Action: Deliver intelligence in formats that reach the right stakeholders at the right time. This phase ensures intelligence informs operations, response, and decision-making, not just reporting.
- Feedback & Retasking: Continuously review outcomes, stakeholder input, and changing threats to refine requirements and adjust collection and analysis. This feedback loop keeps the intelligence program aligned with real-world risk and operational needs.
PHASE 1: Requirements & Tasking
The first phase of the threat intelligence lifecycle is arguably the most important because it defines the purpose and direction of every activity that follows. This phase focuses on clearly articulating what intelligence needs to answer and why.
As an initial step, organizations should define their intelligence requirements, often referred to as Priority Intelligence Requirements (PIRs). In public sector contexts, these may also be called Essential Elements of Information (EEIs). Regardless of terminology, the goal is the same: establish clear, stakeholder-driven questions that intelligence is expected to support.
Effective requirements are tied directly to business risk and operational outcomes. They should reflect what the organization is trying to protect, the threats of greatest concern, and the decisions intelligence is meant to inform, such as reducing operational risk, improving efficiency, or accelerating detection and response.
This process often resembles building a business case, and that’s intentional. Clearly defined requirements make it easier to align intelligence efforts with organizational priorities, establish meaningful key performance indicators (KPIs), and demonstrate the value of intelligence over time.
In many organizations, senior leadership, such as the Chief Information Security Officer (CISO or CSO), plays a key role in shaping requirements by identifying critical assets, defining risk tolerance, and setting expectations for how intelligence should support decision-making.
Key Considerations in Phase 1
— Which assets, processes, or people present the highest risk to the organization?
— What decisions should intelligence help inform or accelerate?
— How should intelligence improve efficiency, prioritization, or response across teams?
— Which downstream teams or systems will rely on these intelligence outputs?
PHASE 2: Collection & Discovery
The Collection & Discovery phase focuses on building visibility into the threat environments most relevant to your organization. Both the breadth and depth of collection matter. Too little visibility creates blind spots; too much unfocused data overwhelms teams with noise and false positives.
At this stage, organizations determine where and how intelligence is collected, including the types of sources monitored and the mechanisms used to adapt coverage as threats evolve. This can include visibility into phishing activity, compromised credentials, vulnerabilities and exploits, malware tooling, fraud schemes, and other adversary behaviors across open, deep, and closed environments.
Effective programs increasingly rely on Primary Source Collection, or the ability to collect intelligence directly from original sources based on defined requirements, rather than consuming static, vendor-defined feeds. This approach enables teams to monitor the environments where threats originate, coordinate, and evolve—and to adjust collection dynamically as priorities shift.
Discovery extends collection beyond static source lists. Rather than relying solely on predefined feeds, effective programs continuously identify new sources, communities, and channels as threat actors shift tactics, platforms, and coordination methods. This adaptability is critical for surfacing early indicators and upstream activity before threats materialize internally.
The processing component of this phase ensures collected data is usable. Raw inputs are normalized, structured, translated, deduplicated, and enriched so analysts can quickly assess relevance and move into analysis. Common processing activities include language translation, metadata extraction, entity normalization, and reduction of low-signal content.
Key Considerations in Phase 2
— Where do you lack visibility into emerging or upstream threat activity?
— Are your collection methods adaptable as threat actors and platforms change?
— Do you have the ability to collect directly from primary sources based on your own intelligence requirements, rather than relying on fixed vendor feeds?
— How effectively can you access and monitor closed or high-risk environments?
— Is collected data structured and enriched in a way that supports efficient analysis?
PHASE 3: Analysis & Prioritization
The Analysis & Prioritization phase focuses on transforming processed data into meaningful intelligence that supports real decisions. This is where analysts connect signals across sources, enrich raw findings with context, assess credibility and relevance, and determine why a threat matters to the organization.
Effective analysis evaluates activity, likelihood, impact, and business relevance. Analysts correlate threat actor behavior, infrastructure, vulnerabilities, and targeting patterns to understand exposure and prioritize response. This step is critical for moving from information awareness to actionable insight.
As artificial intelligence and machine learning continue to mature, they increasingly support this phase by accelerating enrichment, correlation, translation, and pattern recognition across large datasets. When applied thoughtfully, AI helps analysts scale their work and improve consistency, while human expertise remains essential for judgment, context, and prioritization especially for high-risk or ambiguous threats.
This phase delivers clarity and a defensible view of what requires attention first and why.
Key Considerations in Phase 3
— Which threats pose the greatest risk based on likelihood, impact, and business relevance?
— How effectively are analysts correlating signals across sources, assets, and domains?
— Where can automation or AI reduce manual effort without sacrificing analytic rigor?
— Are analysis outputs clearly prioritized to support downstream action?
PHASE 4: Dissemination & Action
Once analysis and prioritization are complete, intelligence must be delivered in a way that enables action. The Dissemination & Action phase focuses on translating finished intelligence into formats that are clear, relevant, and aligned to how different stakeholders make decisions.
This phase is dedicated to ensuring the right information reaches the right teams at the right time. Effective dissemination considers audience, urgency, and operational context, whether intelligence is supporting detection engineering, incident response, fraud prevention, vulnerability remediation, or executive decision-making.
Finished intelligence should include clear assessments, confidence levels, and recommended actions. These recommendations may inform incident response playbooks, ransomware mitigation steps, patch prioritization, fraud controls, or monitoring adjustments. The goal is to remove ambiguity and enable stakeholders to act decisively.
Ultimately, intelligence only delivers value when it drives outcomes. In this phase, stakeholders evaluate the intelligence provided and determine whether, and how, to act on it.
Key Considerations in Phase 4
— Who needs this intelligence, and how should it be delivered to support timely decisions?
— Are findings communicated with appropriate context, confidence, and clarity?
— Do outputs include clear recommendations or actions tailored to the audience?
— Is intelligence integrated into operational workflows, not just distributed as static reports?
PHASE 5: Feedback & Retasking
The Feedback & Retasking phase closes the intelligence lifecycle loop by ensuring intelligence remains aligned to real-world needs as threats, priorities, and business conditions change. Rather than treating intelligence delivery as an endpoint, this phase focuses on evaluating impact and continuously refining what the intelligence function is working on and why.
Once intelligence has been acted on, stakeholders assess whether it was timely, relevant, and actionable. Their feedback informs updates to requirements, collection priorities, analytic focus, and delivery methods. Mature programs use this input to adjust tasking in near real time, ensuring intelligence efforts remain focused on the threats that matter most.
Improvements at this stage often center on shortening retasking cycles, reducing low-value outputs, and strengthening alignment between intelligence producers and decision-makers. Over time, this creates a more adaptive and responsive intelligence function that evolves alongside the threat landscape.
Key Considerations in Phase 5
— How frequently are intelligence priorities reviewed and updated?
— Which intelligence outputs led to decisions or action—and which did not?
— Are stakeholders able to provide structured feedback on relevance and impact?
— How quickly can requirements, sources, or analytic focus be adjusted based on new threats or business needs?
— Does the feedback loop actively improve future intelligence collection, analysis, and delivery?
Assessing Your Threat Intelligence Lifecycle in Practice
Understanding the threat intelligence lifecycle is one thing. Knowing how effectively it operates inside your organization today is another.
Most teams don’t struggle because they lack intelligence activities; they struggle because those activities aren’t consistently aligned, operationalized, or adapted as needs change. Requirements may be defined in one area, while collection, analysis, and dissemination evolve unevenly across teams like CTI, vulnerability management, fraud, or physical security.
To help organizations move from conceptual understanding to practical evaluation, Flashpoint developed the Threat Intelligence Capability Assessment.
The assessment maps directly to the lifecycle outlined above, evaluating how intelligence functions across five core dimensions:
- Requirements & Tasking – How clearly intelligence priorities are defined and tied to real business risk
- Collection & Discovery – Whether visibility is broad, deep, and adaptable as threats evolve
- Analysis & Prioritization – How effectively analysts connect signals, context, and impact
- Dissemination & Action – How intelligence reaches operations and decision-makers
- Feedback & Retasking – How frequently priorities are reviewed and adjusted
Based on responses, organizations are mapped to one of four stages—Developing, Maturing, Advanced, or Leader—reflecting how intelligence actually flows across the lifecycle today.
Teams can apply insights by function or workflow, using the results to identify where intelligence is working well, where friction exists, and where targeted changes will have the greatest impact. Each participant also receives a companion guide with practical guidance, including strategic priorities, immediate actions, and a 90-day planning framework to help translate lifecycle insight into execution.
Take the Threat Intelligence Capability Assessment to evaluate how your program aligns to the lifecycle and where to focus next.
See Flashpoint in Action
Flashpoint’s comprehensive threat intelligence platform supports intelligence teams across every phase of the threat intelligence lifecycle, from defining clear requirements and expanding visibility into relevant threat ecosystems, to analysis, prioritization, dissemination, and continuous retasking as conditions change.
Schedule a demo to see how Flashpoint delivers actionable intelligence, analyst expertise, and workflow-ready outputs that help teams identify, prioritize, and respond to threats with greater clarity and confidence—so intelligence doesn’t just inform awareness, but drives timely, measurable action across the organization.
Frequently Asked Questions (FAQs)
What are the five phases of the threat intelligence lifecycle?
The threat intelligence lifecycle consists of five repeatable phases that describe how intelligence moves from intent to action:
Requirements & Tasking, Collection & Discovery, Analysis & Prioritization, Dissemination & Action, and Feedback & Retasking.
Together, these phases ensure that intelligence is driven by real business needs, grounded in relevant visibility, enriched with context, delivered to decision-makers, and continuously refined as threats and priorities change.
| Phase | Primary Objective |
| Requirements & Tasking | Defining intelligence priorities and tying them to real business risk |
| Collection & Discovery | Gathering data from relevant sources and expanding visibility as threats evolve |
| Analysis & Prioritization | Connecting signals, context, and impact to determine what matters most |
| Dissemination & Action | Delivering intelligence to operations and decision-makers in usable formats |
| Feedback & Retasking | Reviewing outcomes and adjusting priorities, sources, and focus over time |
How do intelligence requirements guide security operations?
Intelligence requirements—often formalized as Priority Intelligence Requirements (PIRs)—define the specific questions intelligence teams must answer to support the business. They provide the north star for what to collect, analyze, and report on.
Clear requirements help teams:
- Focus: Reduce noise by prioritizing intelligence aligned to real risk
- Measure: Track whether intelligence outputs are driving decisions or action
- Align: Ensure security, fraud, physical security, and risk teams are working toward shared outcomes
Without clear requirements, intelligence efforts often default to reactive collection and generic reporting that struggle to deliver impact.
Why is the feedback phase of the intelligence lifecycle necessary for a proactive defense?
Feedback & Retasking turns the intelligence lifecycle from a linear process into a continuous improvement loop. It ensures intelligence stays aligned with changing threats, business priorities, and operational needs.
Through regular review and stakeholder input, teams can:
- Identify which intelligence outputs led to action and which did not
- Retire low-value sources or reporting formats
- Adjust requirements, collection, and analysis as new threats emerge
This phase is essential for moving from static reporting to intelligence-led operations, where priorities evolve in near real time and intelligence continuously improves its relevance and impact.
The post The Five Phases of the Threat Intelligence Lifecycle appeared first on Flashpoint.












{kind=link}