IAM Identity Center now supports IPv6
Amazon Web Services (AWS) recommends using AWS IAM Identity Center to provide your workforce access to AWS managed applications—such as Amazon Q Developer—and AWS accounts. Today, we announced IAM Identity Center support for IPv6. To learn more about the advantages of IPv6, visit the IPv6 product page.
When you enable IAM Identity center, it provides an access portal for workforce users to access their AWS applications and accounts either by signing in to the access portal using a URL or by using a bookmark for the application URL. In either case, the access portal handles user authentication before granting access to applications and accounts. Supporting both IPv4 and IPv6 connectivity to the access portal helps facilitate seamless access for clients, such as browsers and applications, regardless of their network configuration.
The launch of IPv6 support in IAM Identity Center introduces new dual-stack endpoints that support both IPv4 and IPv6, so that users can connect using IPv4, IPv6, or dual-stack clients. Current IPv4 endpoints continue to function with no action required. The dual stack capability offered by Identity Center extends to managed applications. When users access the application dual-stack endpoint, the application automatically routes to the Identity Center dual-stack endpoint for authentication. To use Identity Center from IPv6 clients, you must direct your workforce to use the new dual-stack endpoints, and update configurations on your external identity provider (IdP), if you use one.
In this post, we show you how to update your configuration to allow IPv6 clients to connect directly to IAM Identity Center endpoints without requiring network address translation services. We also show you how to monitor which endpoint users are connecting to. Before diving into the implementation details, let’s review the key phases of the transition process.
Transition overview
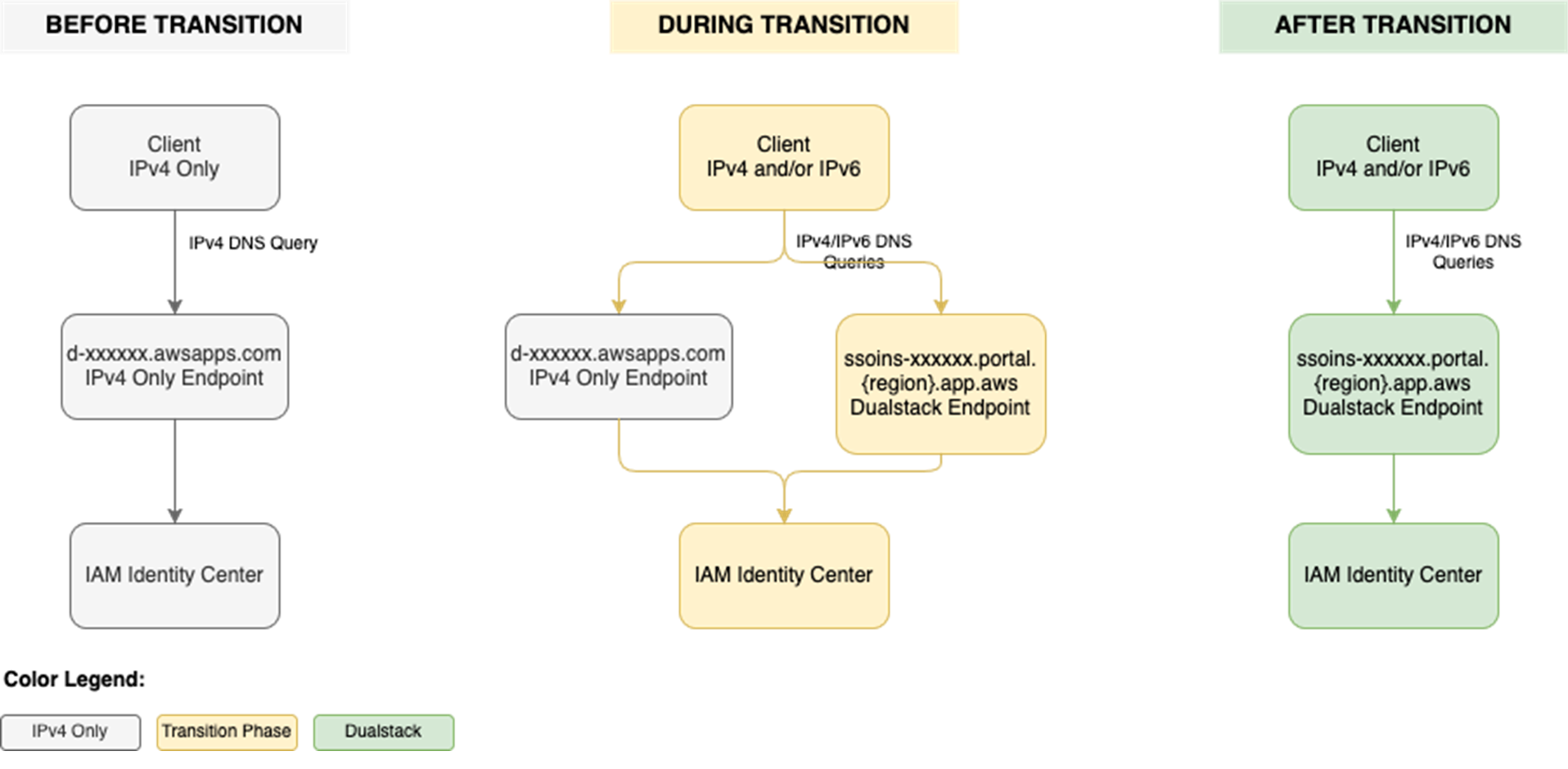
To use IAM Identity Center from an IPv6 network and client, you need to use the new dual-stack endpoints. Figure 1 shows what the transition from IPv4 to IPv6 over dual-stack endpoints looks like when using Identity Center. The figure shows:
- A before state where clients use the IPv4 endpoints.
- The transition phase, when your clients use a combination of IPv4 and dual-stack endpoints.
- After the transition is complete, your clients will connect to dual-stack endpoints using their IPv4 or IPv6, depending on their preferences.
Figure 1: Transition from IPv4-only to dual-stack endpoints
Prerequisites
You must have the following prerequisites in place to enable IPv6 access for your workforce users and administrators:
- An existing IAM Identity Center instance
- Updated firewalls or gateways to include the new dual-stack endpoints
- IPv6 capable clients and networks
Work with your network administrators to update the configuration of your firewalls and gateways and to verify that your clients, such as laptops or desktops, are ready to accept IPv6 connectivity. If you have already enabled IPv6 connectivity for other AWS services, you might be familiar with these changes. Next, implement the two steps that follow.
Step 1: Update your IdP configuration
You can skip this step If you don’t use an external IdP as your identity source.
In this step, you update the Assertion Consumer Service (ACS) URL from your IAM Identity Center instance into your IdP’s configuration for single sign-on and the SCIM configuration for user provisioning. Your IdP’s capability determines how you update the ACS URLs. If your IdP supports multiple ACS URLs, configure both IPv4 and dual-stack URLs to enable a flexible transition. With that configuration, some users can continue using IPv4-only endpoints while others use dual-stack endpoints for IPv6. If your IdP supports only one ACS URL, to use IPv6 you must update the new dual-stack ACS URL in your IdP and transition all users to using dual-stack endpoints. If you don’t use an external IdP, you can skip this step and go to the next step.
Update both the SAML single sign-on and the SCIM provisioning configurations:
- Update the single sign-on settings in your IdP to use the new dual-stack URLs. First, locate the URLs in the AWS Management Console for IAM Identity Center.
- Choose Settings in the navigation pane and then select Identity source.
- Choose Actions and select Manage authentication.
- in Under Manage SAML 2.0 authentication, you will find the following URLs under Service provider metadata:
- AWS access portal sign-in URL
- IAM Identity Center Assertion Consumer Service (ACS) URL
- IAM Identity Center issuer URL
- If your IdP supports multiple ACS URLs, then add the dual-stack URL to your IdP configuration alongside existing IPv4 one. With this setting, you and your users can decide when to start using the dual-stack endpoints, without all users in your organization having to switch together.

Figure 2: Dual-stack single sign-on URLs
- If your IdP does not support multiple ACS URLs, replace the existing IPv4 URL with the new dual-stack URL, and switch your workforce to use only the dual-stack endpoints.
- Update the provisioning endpoint in your IdP. Choose Settings in the navigation pane and under Identity source, choose Actions and select Manage provisioning. Under Automatic provisioning, copy the new SCIM endpoint that ends in
api.aws. Update this new URL in your external IdP.
Figure 3: Dual-stack SCIM endpoint URL
Step 2: Locate and share the new dual-stack endpoints
Your organization needs two kinds of URLs for IPv6 connectivity. The first is the new dual-stack access portal URL that your workforce users use to access their assigned AWS applications and accounts. The dual-stack access portal URL is available in the IAM Identity Center console, listed as the Dual-stack in the Settings summary (you might need to expand the Access portal URLs section, shown in Figure 4).
Figure 4: Locate dual-stack access portal endpoints
This dual-stack URL ends with app.aws as its top-level domain (TLD). Share this URL with your workforce and ask them to use this dual-stack URL to connect over IPv6. As an example, if your workforce uses the access portal to access AWS accounts, they will need to sign in through the new dual-stack access portal URL when using IPv6 connectivity. Alternately, if your workforce accesses the application URL, you need to enable the dual-stack application URL following application-specific instructions. For more information, see AWS services that support IPv6.
The URLs that administrators use to manage IAM Identity Center are the second kind of URL your organization needs. The new dual-stack service endpoints end in api.aws as their TLD and are listed in the Identity Center service endpoints. Administrators can use these service endpoints to manage users and groups in Identity Center, update their access to applications and resources, and perform other management operations. As an example, if your administrator uses identitystore.{region}.amazonaws.com to manage users and groups in Identity Center, they should now use the dual-stack version of the same service endpoint which is identitystore.{region}.api.aws, so they can connect to service endpoints using IPv6 clients and networks.
If your users or administrators use an AWS SDK to access AWS applications and accounts or manage services, follow Dual-stack and FIPS endpoints to enable connectivity to the dual-stack endpoints.
After completing these two steps, your workforce and administrators can connect to IAM Identity Center using IPv6. Remember, these endpoints also support IPv4, so clients not yet IPv6-capable can continue to connect using IPv4.
Monitoring dual-stack endpoint usage
You can optionally monitor AWS CloudTrail logs to track usage of dual-stack endpoints. The key difference between IPv4-only and dual-stack endpoint usage is the TLD and appears in the clientProvidedHostHeader field. The following example shows the difference between these CloudTrail events for the CreateTokenWithIAM API call.
| IPv4-only endpoints | Dual-stack endpoints |
|
|
Conclusion
IAM Identity Center now allows clients to connect over IPv6 natively with no network address translation infrastructure. This post showed you how to transition your organization to use IPv6 with Identity Center and its integrated applications. Remember that existing IPv4 endpoints will continue to function, so you can transition at your own pace. Also, no immediate action is required by you. However, we recommend planning your transition to take advantage of IPv6 benefits and meet compliance requirements. If you have questions, comments, or concerns, contact AWS Support, or start a new thread in the IAM Identity Center re:Post channel.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.




