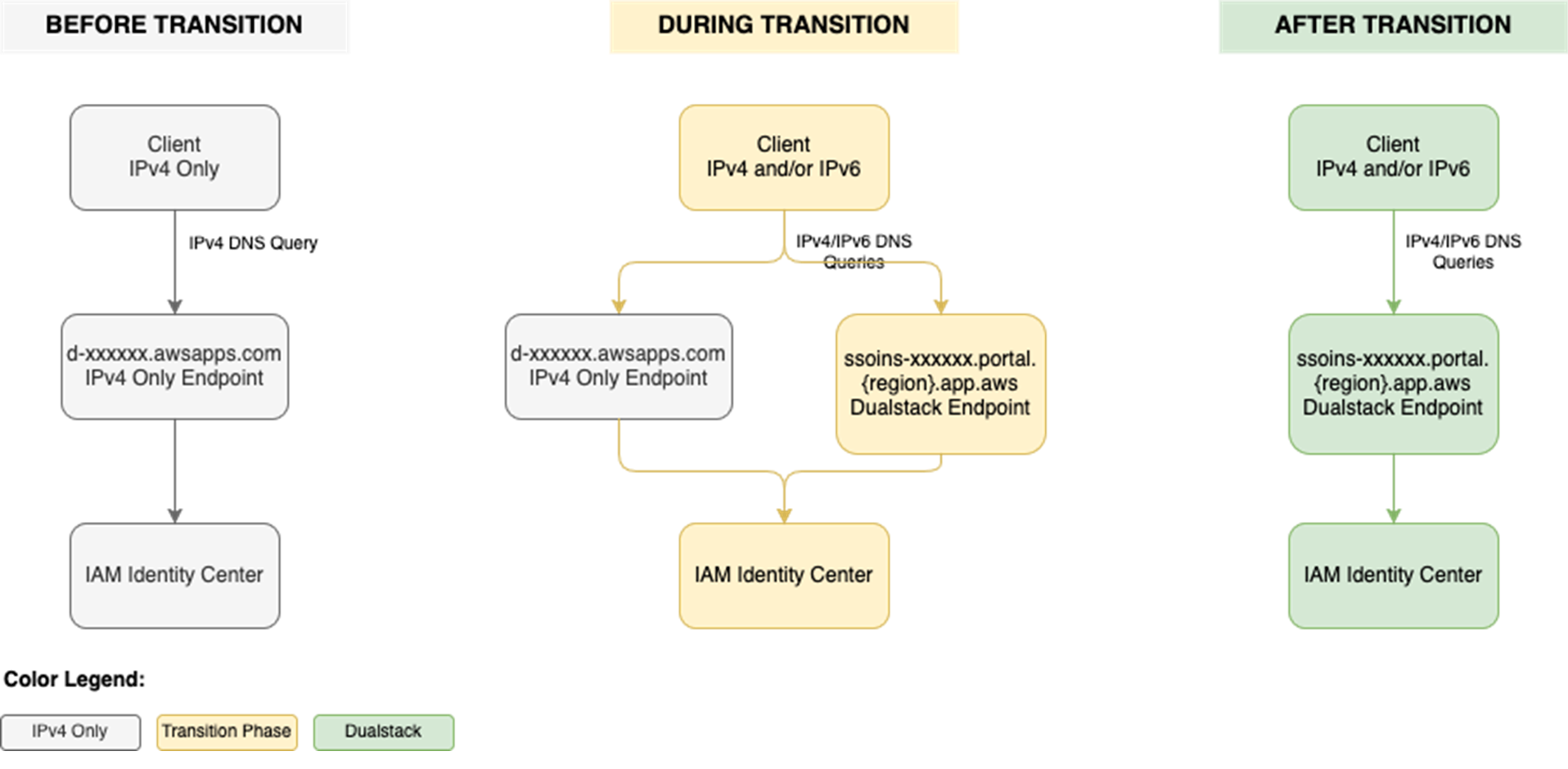
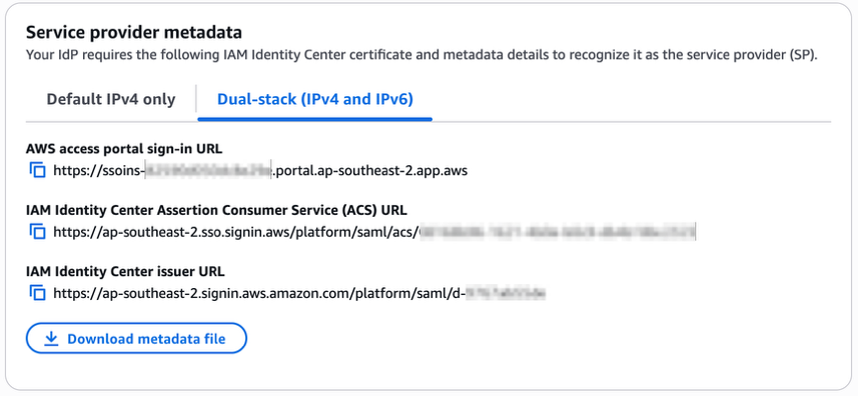
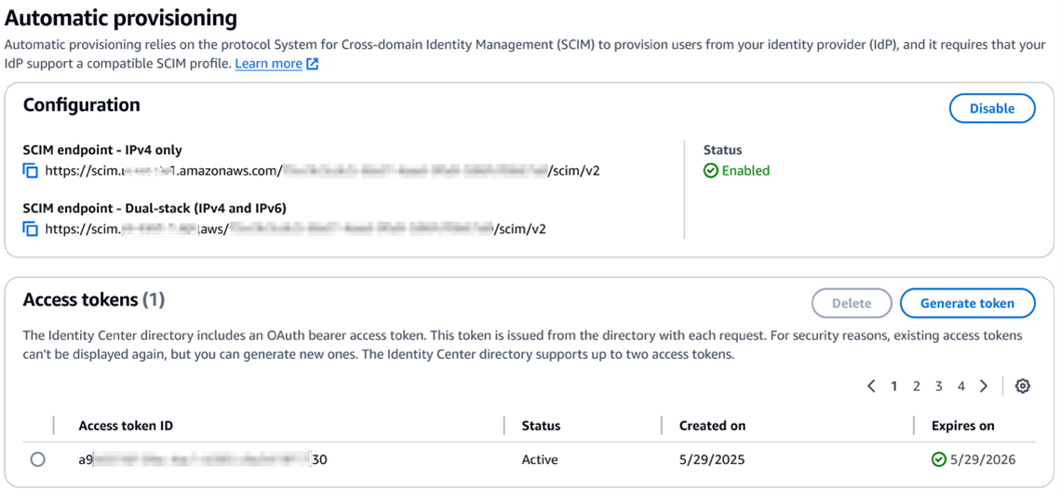
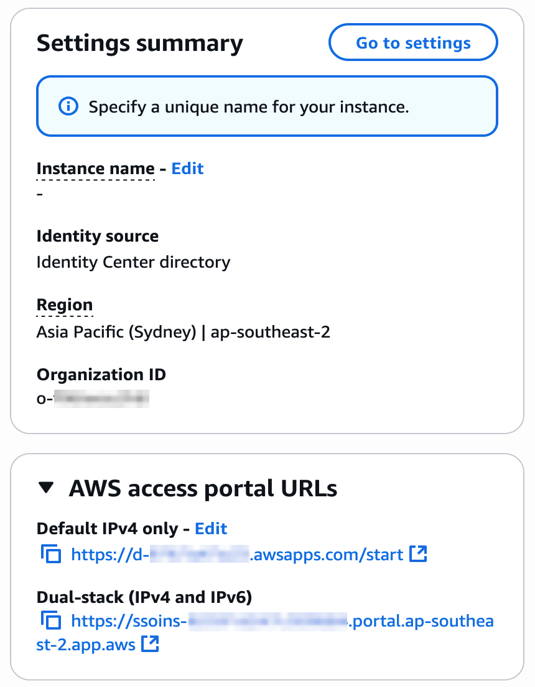
December 2, 2019: Original publication date of this post.
At AWS, we encourage you to use automation. Not just to deploy your workloads and configure services, but to also help you quickly detect and respond to security events within your AWS environments. In addition to increasing the speed of detection and response, automation also helps you scale your security operations as your workloads in AWS increase and scale as well. For these reasons, security automation is a key principle outlined in the Well-Architected Framework, the AWS Cloud Adoption Framework, and the AWS Security Incident Response Guide.
Security response automation is a broad topic that spans many areas. The goal of this blog post is to introduce you to core concepts and help you get started. You will learn how to implement automated security response mechanisms within your AWS environments. This post will include common patterns that customers often use, implementation considerations, and an example solution. Additionally, we will share resources AWS has produced in the form of the Automated Security Response GitHub repo. The GitHub repo includes scripts that are ready-to-deploy for common scenarios.
What is security response automation?
Security response automation is a planned and programmed action taken to achieve a desired state for an application or resource based on a condition or event. When you implement security response automation, you should adopt an approach that draws from existing security frameworks. Frameworks are published materials which consist of standards, guidelines, and best practices in order help organizations manage cybersecurity-related risk. Using frameworks helps you achieve consistency and scalability and enables you to focus more on the strategic aspects of your security program. You should work with compliance professionals within your organization to understand any specific compliance or security frameworks that are also relevant for your AWS environment.
Our example solution is based on the NIST Cybersecurity Framework (CSF), which is designed to help organizations assess and improve their ability to help prevent, detect, and respond to security events. According to the CSF, “cybersecurity incident response” supports your ability to contain the impact of potential cybersecurity events.
Although automation is not a CSF requirement, automating responses to events enables you to create repeatable, predictable approaches to monitoring and responding to threats. When we build automation around events that we know should not occur, it gives us an advantage over a malicious actor because the automation is able to respond within minutes or even seconds compared to an on-call support engineer.
The five main steps in the CSF are identify, protect, detect, respond and recover. We’ve expanded the detect and respond steps to include automation and investigation activities.
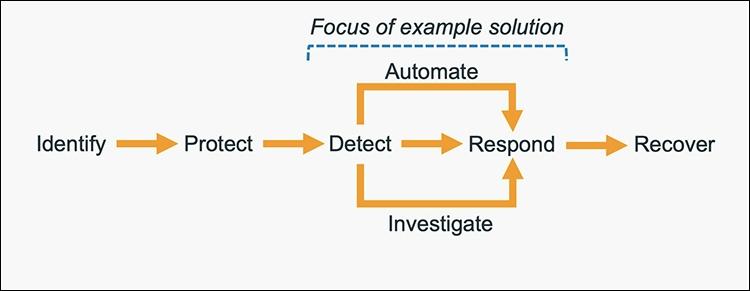
Figure 1: The five steps in the CSF
The following definitions for each step in the diagram above are based on the CSF but have been adapted for our example in this blog post. Although we will focus on the detect, automate and respond steps, it’s important to understand the entire process flow.
- Identify: Identify and understand the resources, applications, and data within your AWS environment.
- Protect: Develop and implement appropriate controls and safeguards to facilitate the delivery of services.
- Detect: Develop and implement appropriate activities to identify the occurrence of a cybersecurity event. This step includes the implementation of monitoring capabilities which will be discussed further in the next section.
- Automate: Develop and implement planned, programmed actions that will achieve a desired state for an application or resource based on a condition or event.
- Investigate: Perform a systematic examination of the security event to establish the root cause.
- Respond: Develop and implement appropriate activities to take automated or manual actions regarding a detected security event.
- Recover: Develop and implement appropriate activities to maintain plans for resilience and to restore capabilities or services that were impaired due to a security event
Security response automation on AWS
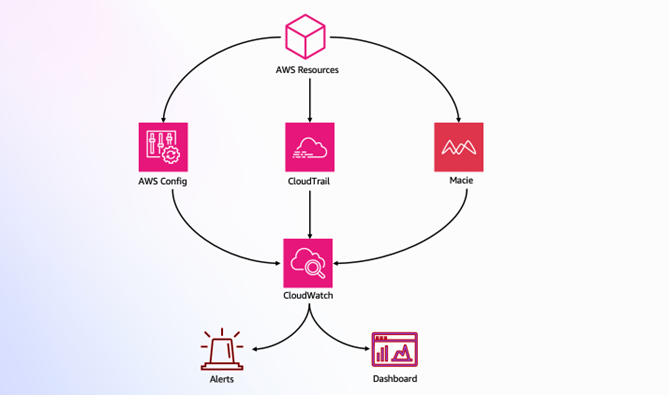
AWS CloudTrail and AWS Config continuously log details regarding users and other identity principals, the resources they interacted with, and configuration changes they might have made in your AWS account. We are able to combine these logs with Amazon EventBridge, which gives us a single service to trigger automations based on events. You can use this information to automatically detect resource changes and to react to deviations from your desired state.
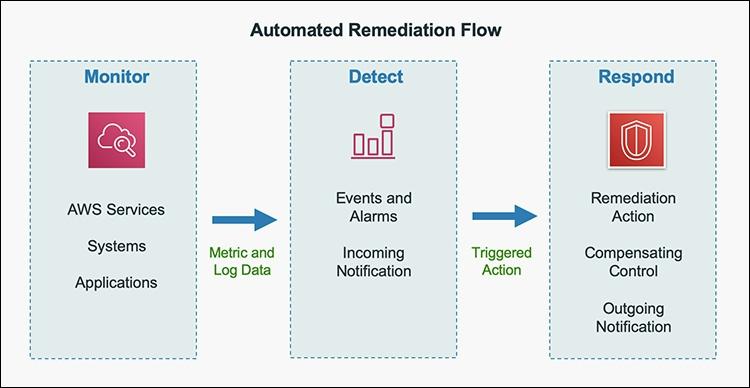
Figure 2: Automated remediation flow
As shown in the diagram above, an automated remediation flow on AWS has three stages:
- Monitor: Your automated monitoring tools collect information about resources and applications running in your AWS environment. For example, they might collect AWS CloudTrail information about activities performed in your AWS account, usage metrics from your Amazon EC2 instances, or flow log information about the traffic going to and from network interfaces in your Amazon Virtual Private Cloud (VPC).
- Detect: When a monitoring tool detects a predefined condition—such as a breached threshold, anomalous activity, or configuration deviation—it raises a flag within the system. A triggering condition might be an anomalous activity detected by Amazon GuardDuty, a resource out of compliance with an AWS Config rule, or a high rate of blocked requests on an Amazon VPC security group or AWS Web Application Firewall (AWS WAF) web access control list (web-acl).
- Respond: When a condition is flagged, an automated response is triggered that performs an action you’ve predefined—something intended to remediate or mitigate the flagged condition.
Examples of automated response actions may include modifying a VPC security group, patching an Amazon EC2 instance, rotating various different types of credentials, or adding an additional entry into an IP set in AWS WAF that is part of a web-acl rule to block suspicious clients who triggered a threshold from a monitoring metric.
You can use the event-driven flow described above to achieve a variety of automated response patterns with varying degrees of complexity. Your response pattern could be as simple as invoking a single AWS Lambda function, or it could be a complex series of AWS Step Function tasks with advanced logic. In this blog post, we’ll use two simple Lambda functions in our example solution.
How to define your response automation
Now that we’ve introduced the concept of security response automation, start thinking about security requirements within your environment that you’d like to enforce through automation. These design requirements might come from general best practices you’d like to follow, or they might be specific controls from compliance frameworks relevant for your business.
Customers start with the run-books they already use as part of their Incident Response Lifecycle. Simple run-books, like responding to an exfiltrated credential, can be quickly mapped to automation especially if your run book calls for the disabling of the credential and the notification of on-call personnel. But it can be resource driven as well. Events such as a new AWS VPC being created might trigger your automation to immediately deploy your company’s standard configuration for VPC flowlog collection.
Your objectives should be quantitative, not qualitative. Here are some examples of quantitative objectives:
- Remote administrative network access to servers should be limited.
- Server storage volumes should be encrypted.
- AWS console logins should be protected by multi-factor authentication.
As an optional step, you can expand these objectives into user stories that define the conditions and remediation actions when there is an event. User stories are informal descriptions that briefly document a feature within a software system. User stories may be global and span across multiple applications or they may be specific to a single application.
For example:
“Remote administrative network access to servers should have limited access from internal trusted networks only. Remote access ports include SSH TCP port 22 and RDP TCP port 3389. If remote access ports are detected within the environment and they are accessible to outside resources, they should be automatically closed and the owner will be notified.”
Once you’ve completed your user story, you can determine how to use automated remediation to help achieve these objectives in your AWS environment. User stories should be stored in a location that provides versioning support and can reference the associated automation code.
You should carefully consider the effect of your remediation mechanisms in order to help prevent unintended impact on your resources and applications. Remediation actions such as instance termination, credential revocation, and security group modification can adversely affect application availability. Depending on the level of risk that’s acceptable to your organization, your automated mechanism can only provide a notification which would then be manually investigated prior to remediation. Once you’ve identified an automated remediation mechanism, you can build out the required components and test them in a non-production environment.
Sample response automation walkthrough
In the following section, we’ll walk you through an automated remediation for a simulated event that indicates potential unauthorized activity—the unintended disabling of CloudTrail logging. Outside parties might want to disable logging to avoid detection and the recording of their unauthorized activity. Our response is to re-enable the CloudTrail logging and immediately notify the security contact. Here’s the user story for this scenario:
“CloudTrail logging should be enabled for all AWS accounts and regions. If CloudTrail logging is disabled, it will automatically be enabled and the security operations team will be notified.”
A note about the sample response automation below as it references Amazon EventBridge: EventBridge was formerly referred to as Amazon CloudWatch Events. If you see other documentation referring to Amazon CloudWatch, you can find that configuration now via the Amazon EventBridge console page.
Additionally, we will be looking at this scenario through the lens of an account that has a stand-alone CloudTrail configuration. While this is an acceptable configuration, AWS recommends using AWS Organizations, which allows you to configure an organizational CloudTrail. These organizational trails are immutable to the child accounts so that logging data cannot be removed or tampered with.
In order to use our sample remediation, you will need to enable Amazon GuardDuty and AWS Security Hub in the AWS Region you have selected. Both of these services include a 30-day trial at no additional cost. See the AWS Security Hub pricing page and the Amazon GuardDuty pricing page for additional details.
Important: You’ll use AWS CloudTrail to test the sample remediation. Running more than one CloudTrail trail in your AWS account will result in charges based on the number of events processed while the trail is running. Charges for additional copies of management events recorded in a Region are applied based on the published pricing plan. To minimize the charges, follow the clean-up steps that we provide later in this post to remove the sample automation and delete the trail.
Deploy the sample response automation
In this section, we’ll show you how to deploy and test the CloudTrail logging remediation sample. Amazon GuardDuty generates the finding
Stealth:IAMUser/CloudTrailLoggingDisabled when CloudTrail logging is disabled, and AWS Security Hub collects findings from GuardDuty using the standardized finding format mentioned earlier. We recommend that you deploy this sample into a non- production AWS account.
Select the Launch Stack button below to deploy a CloudFormation template with an automation sample in the us-east-1 Region. You can also download the template and implement it in another Region. The template consists of an Amazon EventBridge rule, an AWS Lambda function, and the IAM permissions necessary for both components to execute. It takes several minutes for the CloudFormation stack build to complete.

- In the CloudFormation console, choose the Select Template form, and then select Next.
- On the Specify Details page, provide the email address for a security contact. For the purpose of this walkthrough, it should be an email address that you have access to. Then select Next.
- On the Options page, accept the defaults, then select Next.
- On the Review page, confirm the details, then select Create.
- While the stack is being created, check the inbox of the email address that you provided in step 2. Look for an email message with the subject AWS Notification – Subscription Confirmation. Select the link in the body of the email to confirm your subscription to the Amazon Simple Notification Service (Amazon SNS) topic. You should see a success message like the one shown in Figure 3:
Figure 3: SNS subscription confirmation
- Return to the CloudFormation console. After the Status field for the CloudFormation stack changes to CREATE COMPLETE (as shown in Figure 4), the solution is implemented and is ready for testing.
Figure 4: CREATE_COMPLETE status
Test the sample automation
You’re now ready to test the automated response by creating a test trail in CloudTrail, then trying to stop it.
- From the AWS Management Console, choose Services > CloudTrail.
- Select Trails, then select Create Trail.
- On the Create Trail form:
- Enter a value for Trail name and for AWS KMS alias, as shown in Figure 5.
- For Storage location, create a new S3 bucket or choose an existing one. For our testing, we create a new S3 bucket.
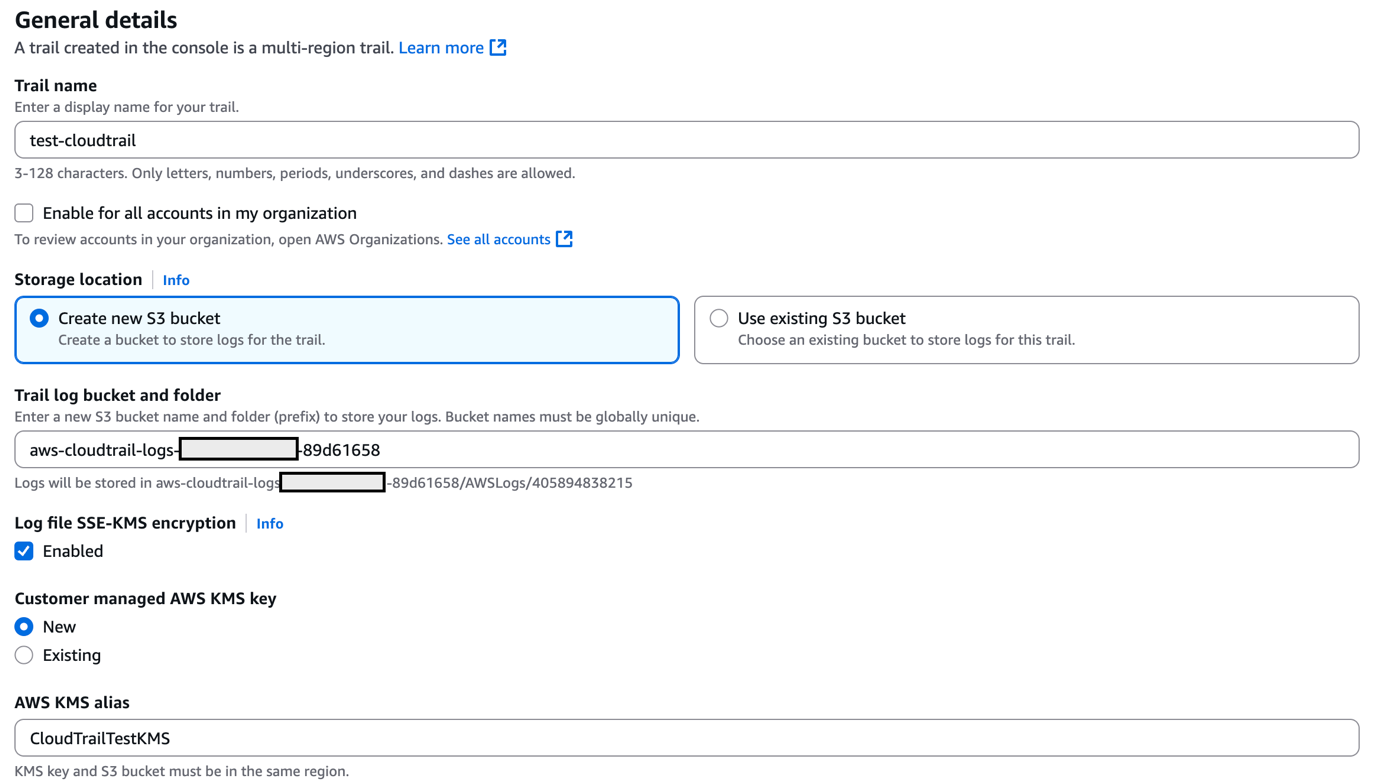
Figure 5: Create a CloudTrail trail
- On the next page, under Management events, select Write-only (to minimize event volume).
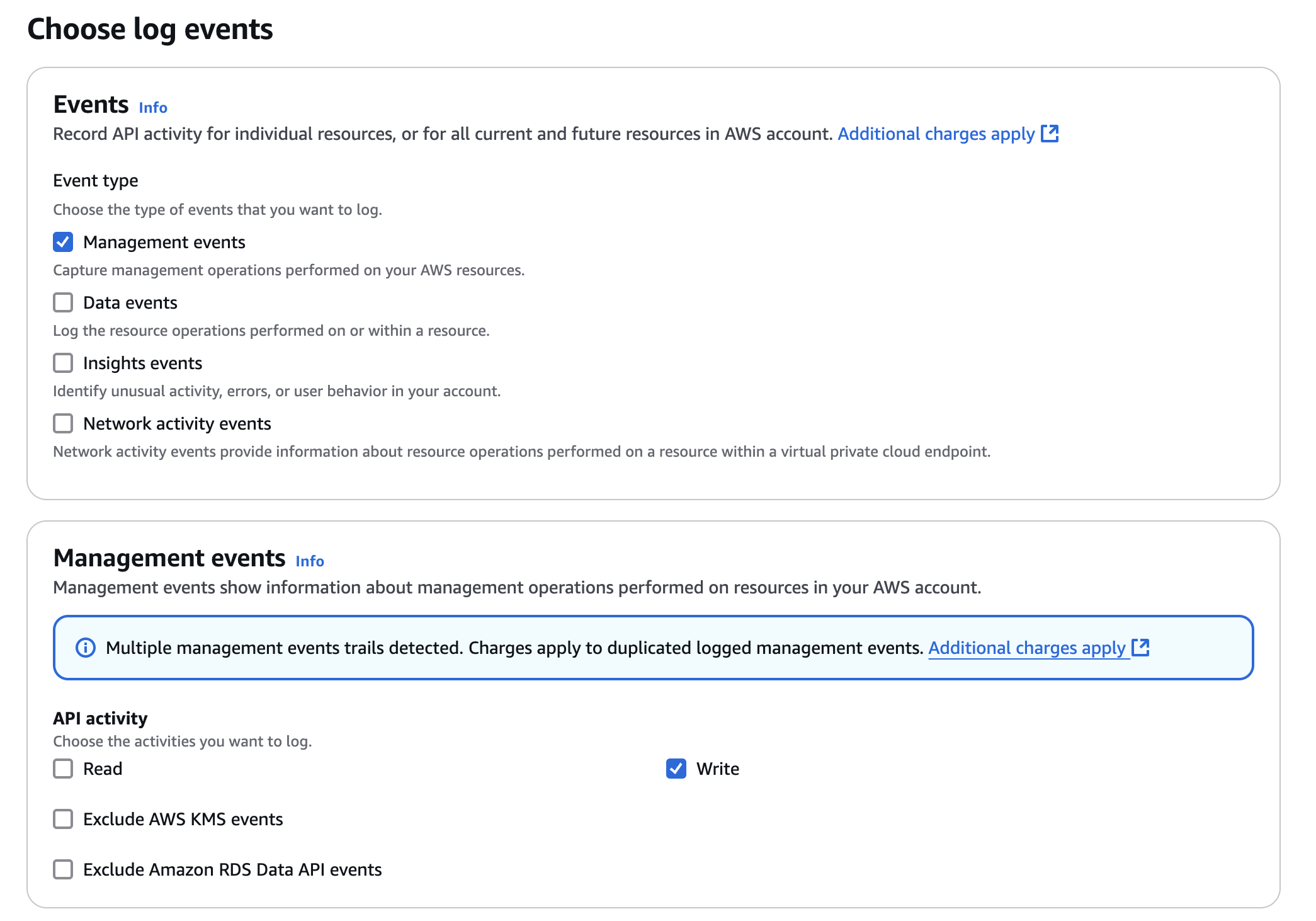
Figure 6: Create a CloudTrail trail
- On the Trails page of the CloudTrail console, verify that the new trail has started. You should see the status as logging, as shown in Figure 7.
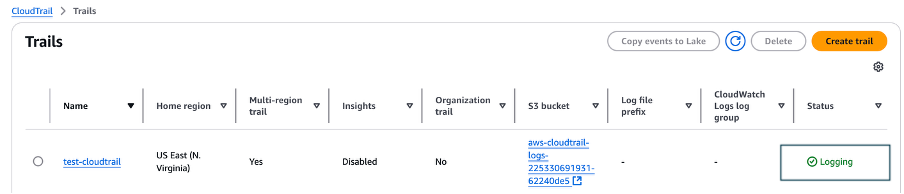
Figure 7: Verify new trail has started
- You’re now ready to act like an unauthorized user trying to cover their tracks. Stop the logging for the trail that you just created:
- Select the new trail name to display its configuration page.
- In the top-right corner, choose the Stop logging button.
- When prompted with a warning dialog box, select Stop logging.
- Verify that the logging has stopped by confirming that the Start logging button now appears in the top right, as shown in Figure 8.
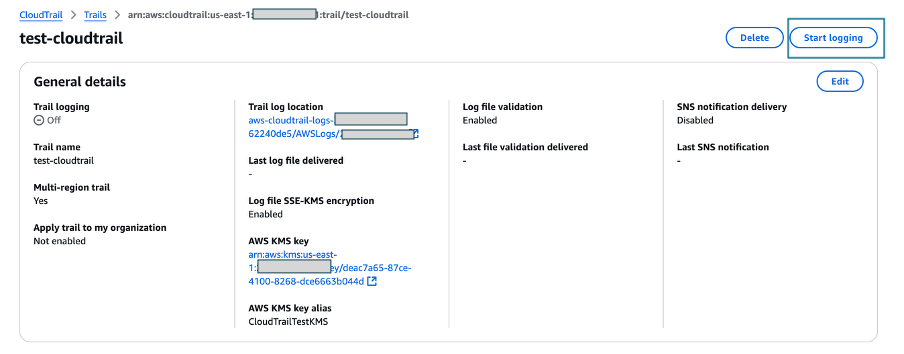
Figure 8: Verify logging switch is off
You have now simulated a security event by disabling logging for one of the trails in the CloudTrail service. Within the next few seconds, the near real-time automated response will detect the stopped trail, restart it, and send an email notification. You can refresh the Trails page of the CloudTrail console to verify through the Stop logging button at the top right corner.
Within the next several minutes, the investigatory automated response will also begin. GuardDuty will detect the action that stopped the trail and enrich the data about the source of unexpected behavior. Security Hub will then ingest that information and optionally correlate with other security events.
Following the steps below, you can monitor findings within Security Hub for the finding type TTPs/Defense Evasion/Stealth:IAMUser-CloudTrailLoggingDisabled to be generated:
- In the AWS Management Console, choose Services > Security Hub.
- In the left pane, select Findings.
- Select the Add filters field, then select Type.
- Select EQUALS, paste TTPs/Defense Evasion/Stealth:IAMUser-CloudTrailLoggingDisabled into the field, then select Apply.
- Refresh your browser periodically until the finding is generated.
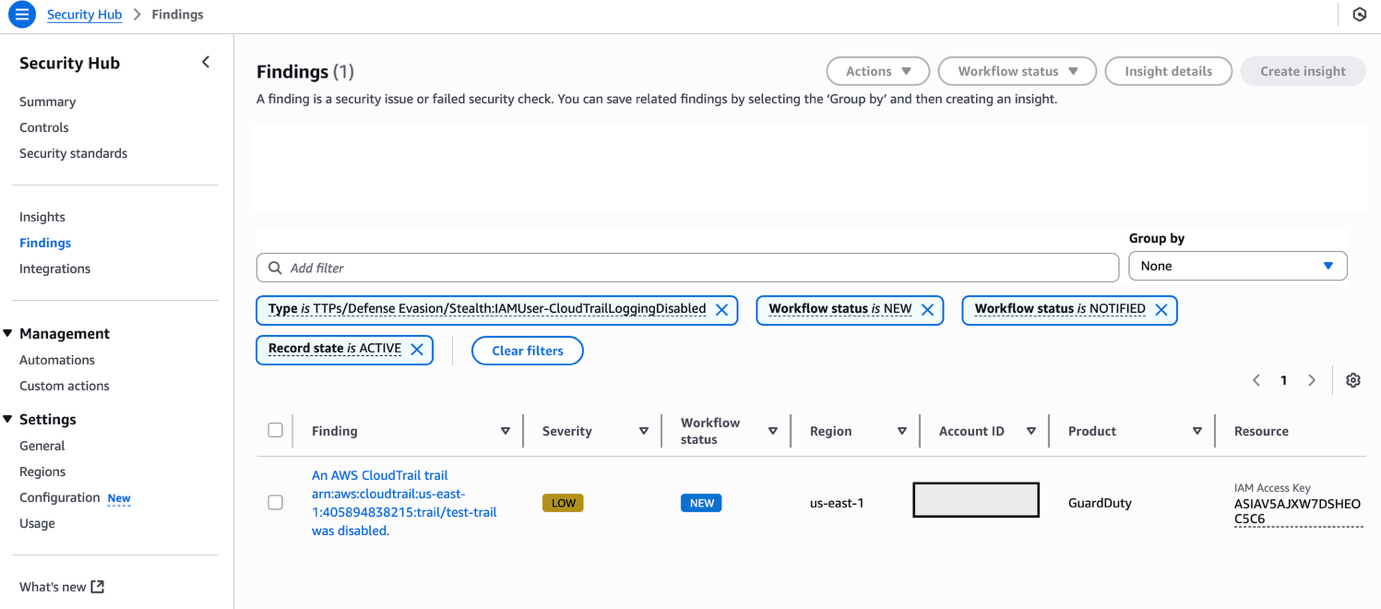
Figure 9: Monitor Security Hub for your finding
- Select the title of the finding to review details. When you’re ready, you can choose to archive the finding by selecting the Archive link. Alternately, you can select a custom action to continue with the response. Custom actions are one of the ways that you can integrate Security Hub with custom partner solutions.
Now that you’ve completed your review of the finding, let’s dig into the components of automation.
How the sample automation works
This example incorporates two automated responses: a near real-time workflow and an investigatory workflow. The near real-time workflow provides a rapid response to an individual event, in this case the stopping of a trail. The goal is to restore the trail to a functioning state and alert security responders as quickly as possible. The investigatory workflow still includes a response to provide defense in depth and uses services that support a more in-depth investigation of the incident.
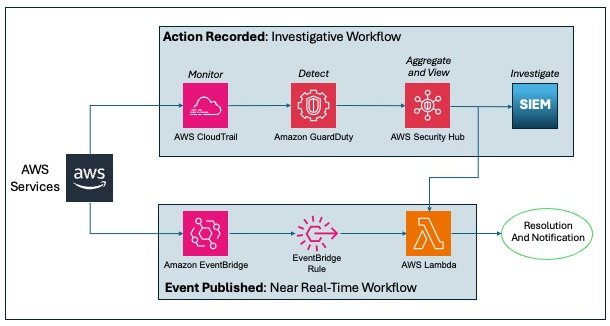
Figure 10: Sample automation workflow
In the near real-time workflow, Amazon EventBridge monitors for the undesired activity.
When a trail is stopped, AWS CloudTrail publishes an event on the EventBridge bus. An EventBridge rule detects the trail-stopping event and invokes a Lambda function to respond to the event by restarting the trail and notifying the security contact via an Amazon Simple Notification Service (SNS) topic.
In the investigative workflow, CloudTrail logs are monitored for undesired activities. For example, if a trail is stopped, there will be a corresponding log record. GuardDuty detects this activity and retrieves additional data points regarding the source IP that executed the API call. Two common examples of those additional data points in GuardDuty findings include whether the API call came from an IP address on a threat list, or whether it came from a network not commonly used in your AWS account. An AWS Lambda function responds by restarting the trail and notifying the security contact. The finding is imported into AWS Security Hub, where it’s aggregated with other findings for analyst viewing. Using EventBridge, you can configure Security Hub to export the finding to partner security orchestration tools, SIEM (security information and event management) systems, and ticketing systems for investigation.
AWS Security Hub imports findings from AWS security services such as GuardDuty, Amazon Macie and Amazon Inspector, plus from third-party product integrations you’ve enabled. Findings are provided to Security Hub in AWS Security Finding Format (ASFF), which minimizes the need for data conversion. Security Hub correlates these findings to help you identify related security events and determine a root cause. Security Hub also publishes its findings to Amazon EventBridge to enable further processing by other AWS services such as AWS Lambda. You can also create custom actions using Security Hub. Custom actions are useful for security analysts working with the Security Hub console who want to send a specific finding, or a small set of findings, to a response or a remediation workflow.
Deeper look into how the “Respond” phase works
Amazon EventBridge and AWS Lambda work together to respond to a security finding.
Amazon EventBridge is a service that provides real-time access to changes in data in AWS services, your own applications, and Software-as-a-Service (SaaS) applications without writing code. In this example, EventBridge identifies a Security Hub finding that requires action and invokes a Lambda function that performs remediation. As shown in Figure 11, the Lambda function both notifies the security operator via SNS and restarts the stopped CloudTrail.
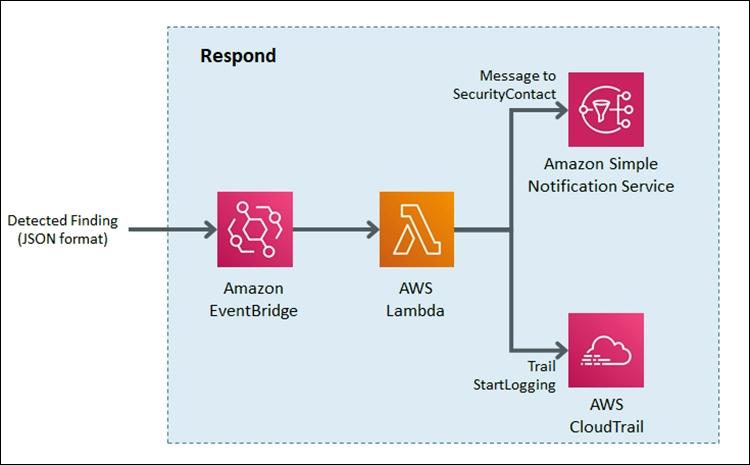
Figure 11: Sample “respond” workflow
To set this response up, we looked for an event to indicate that a trail had stopped or was disabled. We knew that the GuardDuty finding Stealth:IAMUser/CloudTrailLoggingDisabled is raised when CloudTrail logging is disabled. Therefore, we configured the default event bus to look for this event.
You can learn more regarding the available GuardDuty findings in the user guide.
How the code works
When Security Hub publishes a finding to EventBridge, it includes full details of the finding as discovered by GuardDuty. The finding is published in JSON format. If you review the details of the sample finding, note that it has several fields helping you identify the specific events that you’re looking for. Here are some of the relevant details:
{
…
"source":"aws.securityhub",
…
"detail":{
"findings": [{
…
“Types”: [
"TTPs/Defense Evasion/Stealth:IAMUser-CloudTrailLoggingDisabled"
],
…
}]
}
You can build an event pattern using these fields, which an EventBridge filtering rule can then use to identify events and to invoke the remediation Lambda function. Below is a snippet from the CloudFormation template we provided earlier that defines that event pattern for the EventBridge filtering rule:
# pattern matches the nested JSON format of a specific Security Hub finding
EventPattern:
source:
- aws.securityhub
detail-type:
- "Security Hub Findings - Imported"
detail:
findings:
Types:
- "TTPs/Defense Evasion/Stealth:IAMUser-CloudTrailLoggingDisabled"
Once the rule is in place, EventBridge continuously monitors the event bus for events with this pattern.
When EventBridge finds a match, it invokes the remediating Lambda function and passes the full details of the event to the function. The Lambda function then parses the JSON fields in the event so that it can act as shown in this Python code snippet:
# extract trail ARN by parsing the incoming Security Hub finding (in JSON format)
trailARN = event['detail']['findings'][0]['ProductFields']['action/awsApiCallAction/affectedResources/AWS::CloudTrail::Trail']
# description contains useful details to be sent to security operations
description = event['detail']['findings'][0]['Description']
The code also issues a notification to security operators so they can review the findings and insights in Security Hub and other services to better understand the incident and to decide whether further manual actions are warranted. Here’s the code snippet that uses SNS to send out a note to security operators:
#Sending the notification that the AWS CloudTrail has been disabled.
snspublish = snsclient.publish(
TargetArn = snsARN,
Message="Automatically restarting CloudTrail logging. Event description: \"%s\" " %description
)
While notifications to human operators are important, the Lambda function will not wait to take action. It immediately remediates the condition by restarting the stopped trail in CloudTrail. Here’s a code snippet that restarts the trail to reenable logging:
try:
client = boto3.client('cloudtrail')
enablelogging = client.start_logging(Name=trailARN)
logger.debug("Response on enable CloudTrail logging- %s" %enablelogging)
except ClientError as e:
logger.error("An error occured: %s" %e)
After the trail has been restarted, API activity is once again logged and can be audited.
This can help provide relevant data for the remaining steps in the incident response process. The data is especially important for the post-incident phase, when your team analyzes lessons learned to help prevent future incidents. You can also use this phase to identify additional steps to automate in your incident response.
How to Enable Custom Action and build your own Automated Response
Unlike how you set up the notification earlier, you may not want fully automate responses to findings. To set up automation that you can manually trigger it for specific findings, you can use custom actions. A custom action is a Security Hub mechanism for sending selected findings to EventBridge that can be matched by an EventBridge rule. The rule defines a specific action to take when a finding is received that is associated with the custom action ID. Custom actions can be used, for example, to send a specific finding, or a small set of findings, to a response or remediation workflow. You can create up to 50 custom actions.
In this section, we will walk you through how to create a custom action in Security Hub which will trigger an EventBridge rule to execute a Lambda function for the same security finding related to CloudTrail Disabled.
Create a Custom Action in Security Hub
- Open Security Hub. In the left navigation pane, under Management, open the Custom actions page.
- Choose Create custom action.
- Enter an Action Name, Action Description, and Action ID that are representative of an action that you are implementing—for example
Enable CloudTrail Logging.
- Choose Create custom action.
- Copy the custom action ARN that was generated. You will need it in the next steps.
Create Amazon EventBridge Rule to capture the Custom Action
In this section, you will define an EventBridge rule that will match events (findings) coming from Security Hub which were forwarded by the custom action you defined above.
- Navigate to the Amazon EventBridge console.
- On the right side, choose Create rule.
- On the Define rule detail page, give your rule a name and description that represents the rule’s purpose (for example, the same name and description that you used for the custom action). Then choose Next.
- Security Hub findings are sent as events to the AWS default event bus. In the Define pattern section, you can identify filters to take a specific action when matched events appear. For the Build event pattern step, leave the Event source set to AWS events or EventBridge partner events.
- Scroll down to Event pattern. Under Event source, leave it set to AWS Services, and under AWS Service, select Security Hub.
- For the Event Type, choose Security Hub Findings – Custom Action.
- Then select Specific custom action ARN(s) and enter the ARN for the custom action that you created earlier.
- Notice that as you selected these options, the event pattern on the right was updating. Choose Next.
- On the Select target(s) step, from the Select a target dropdown, select Lambda function. Then, from the Function dropdown, select SecurityAutoremediation-CloudTrailStartLoggingLamb-xxxx. This lambda function was created as part of the Cloudformation template.
- Choose Next.
- For the Configure tags step, choose Next.
- For the Review and create step, choose Create rule.
Trigger the automation
As GuardDuty and Security Hub have been enabled, after AWS Cloudtrail logging is enabled, you should see a security finding generated by Amazon GuardDuty and collected in AWS Security Hub.
- Navigate to the Security Hub Findings page.
- In the top corner, from the Actions dropdown menu, select the Enable CloudTrail Logging custom action.
- Verify the CloudTrail configuration by accessing the AWS CloudTrail dashboard.
- Confirm that the trail status displays as Logging, which indicates the successful execution of the remediation Lambda function triggered by the EventBridge rule through the custom action.
How AWS helps customers get started
Many customers look at the task of building automation remediation as daunting. Many operations teams might not have the skills or human scale to take on developing automation scripts. Because many Incident Response scenarios can be mapped to findings in AWS security services, we can begin building tools that respond and are quickly adaptable to your environment.
Automated Security Response (ASR) on AWS is a solution that enables AWS Security Hub customers to remediate findings with a single click using sets of predefined response and remediation actions called Playbooks. The remediations are implemented as AWS Systems Manager automation documents. The solution includes remediations for issues such as unused access keys, open security groups, weak account password policies, VPC flow logging configurations, and public S3 buckets. Remediations can also be configured to trigger automatically when findings appear in AWS Security Hub.
The solution includes the playbook remediations for some of the security controls defined as part of the following standards:
- AWS Foundational Security Best Practices (FSBP) v1.0.0
- Center for Internet Security (CIS) AWS Foundations Benchmark v1.2.0
- Center for Internet Security (CIS) AWS Foundations Benchmark v1.4.0
- Center for Internet Security (CIS) AWS Foundations Benchmark v3.0.0
- Payment Card Industry (PCI) Data Security Standard (DSS) v3.2.1
- National Institute of Standards and Technology (NIST) Special Publication 800-53 Revision 5
A Playbook called Security Control is included that allows operation with AWS Security Hub’s Consolidated Control Findings feature.
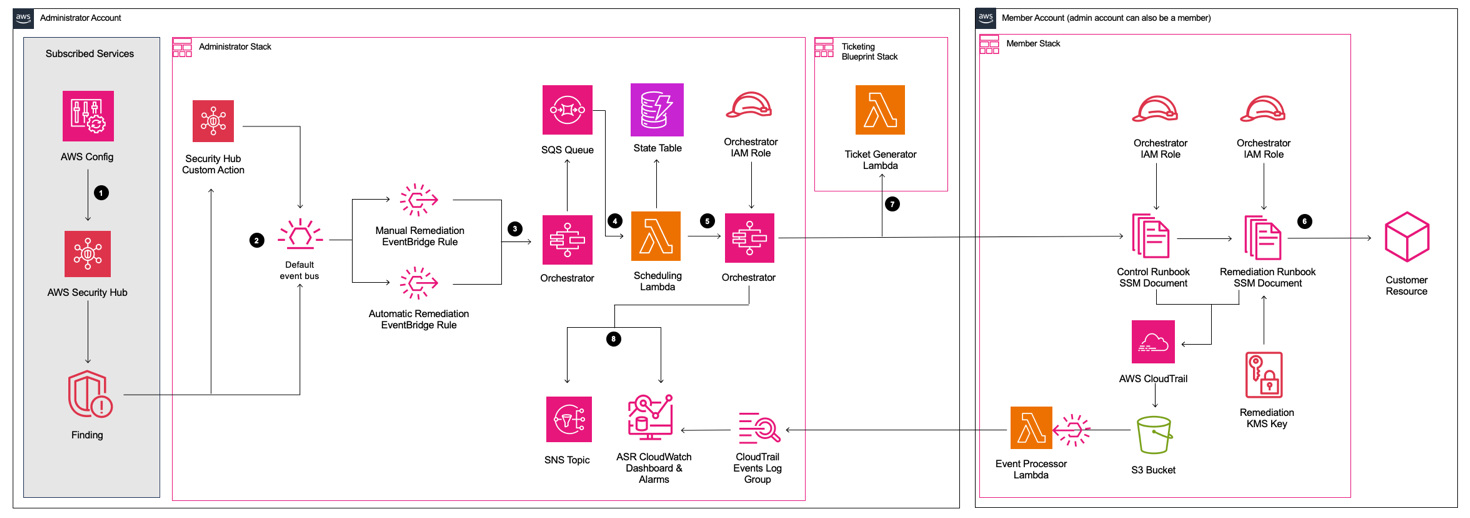
Figure 12: Architecture of the Automated Security Solution
Additionally, the library includes instructions in the Implementation Guide on how to create new automations in an existing Playbook.
You can use and deploy this library into your accounts at no additional cost, however there are costs associated with the services that it consumes.
Clean up
After you’ve completed the sample security response automation, we recommend that you remove the resources created in this walkthrough example from your account in order to minimize the charges associated with the trail in CloudTrail and data stored in S3.
Important: Deleting resources in your account can negatively impact the applications running in your AWS account. Verify that applications and AWS account security do not depend on the resources you’re about to delete.
Here are the clean-up steps:
Summary
You’ve learned the basic concepts and considerations behind security response automation on AWS and how to use Amazon EventBridge, Amazon GuardDuty and AWS Security Hub to automatically re-enable AWS CloudTrail when it becomes disabled unexpectedly. Additionally you got a chance to learn about the AWS Automated Security Response library and how it can help you rapidly get started with automations through Security Hub. As a next step, you may want to start building your own custom response automations and dive deeper into the AWS Security Incident Response Guide, NIST Cybersecurity Framework (CSF) or the AWS Cloud Adoption Framework (CAF) Security Perspective. You can explore additional automatic remediation solutions on the AWS Solution Library. You can find the code used in this example on GitHub.
If you have feedback about this blog post, submit them in the Comments section below. If you have questions about using this solution, start a thread in the
EventBridge, GuardDuty or Security Hub forums, or contact AWS Support.