GuardDuty Extended Threat Detection uncovers cryptomining campaign on Amazon EC2 and Amazon ECS
Amazon GuardDuty and our automated security monitoring systems identified an ongoing cryptocurrency (crypto) mining campaign beginning on November 2, 2025. The operation uses compromised AWS Identity and Access Management (IAM) credentials to target Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Compute Cloud (Amazon EC2). GuardDuty Extended Threat Detection was able to correlate signals across these data sources to raise a critical severity attack sequence finding. Using the massive, advanced threat intelligence capability and existing detection mechanisms of Amazon Web Services (AWS), GuardDuty proactively identified this ongoing campaign and quickly alerted customers to the threat. AWS is sharing relevant findings and mitigation guidance to help customers take appropriate action on this ongoing campaign.
It’s important to note that these actions don’t take advantage of a vulnerability within an AWS service but rather require valid credentials that an unauthorized user uses in an unintended way. Although these actions occur in the customer domain of the shared responsibility model, AWS recommends steps that customers can use to detect, prevent, or reduce the impact of such activity.
Understanding the crypto mining campaign
The recently detected crypto mining campaign employed a novel persistence technique designed to disrupt incident response and extend mining operations. The ongoing campaign was originally identified when GuardDuty security engineers discovered similar attack techniques being used across multiple AWS customer accounts, indicating a coordinated campaign targeting customers using compromised IAM credentials.
Operating from an external hosting provider, the threat actor quickly enumerated Amazon EC2 service quotas and IAM permissions before deploying crypto mining resources across Amazon EC2 and Amazon ECS. Within 10 minutes of the threat actor gaining initial access, crypto miners were operational.
A key technique observed in this attack was the use of ModifyInstanceAttribute with disable API termination set to true, forcing victims to re-enable API termination before deleting the impacted resources. Disabling instance termination protection adds an additional consideration for incident responders and can disrupt automated remediation controls. The threat actor’s scripted use of multiple compute services, in combination with emerging persistence techniques, represents an advancement in crypto mining persistence methodologies that security teams should be aware of.
The multiple detection capabilities of GuardDuty successfully identified the malicious activity through EC2 domain/IP threat intelligence, anomaly detection, and Extended Threat Detection EC2 attack sequences. GuardDuty Extended Threat Detection was able to correlate signals as an AttackSequence:EC2/CompromisedInstanceGroup finding.
Indicators of compromise (IoCs)
Security teams should monitor for the following indicators to identify this crypto mining campaign. Threat actors frequently modify their tactics and techniques, so these indicators might evolve over time:
- Malicious container image – The Docker Hub image
yenik65958/secret, created on October 29, 2025, with over 100,000 pulls, was used to deploy crypto miners to containerized environments. This malicious image contained a SBRMiner-MULTI binary for crypto mining. This specific image has been taken down from Docker Hub, but threat actors might deploy similar images under different names. - Automation and tooling – AWS SDK for Python (Boto3) user agent patterns indicating Python-based automation scripts were used across the entire attack chain.
- Crypto mining domains:
asia[.]rplant[.]xyz,eu[.]rplant[.]xyz, andna[.]rplant[.]xyz. - Infrastructure naming patterns – Auto scaling groups followed specific naming conventions: SPOT-us-east-1-G*-* for spot instances and OD-us-east-1-G*-* for on-demand instances, where G indicates the group number.
Attack chain analysis
The crypto mining campaign followed a systematic attack progression across multiple phases. Sensitive fields in this post were given fictitious values to protect personally identifiable information (PII).
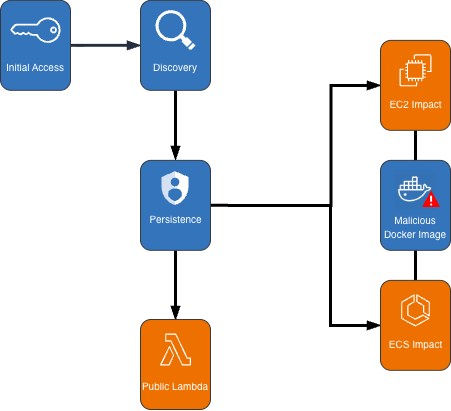
Figure 1: Cryptocurrency mining campaign diagram
Initial access, discovery, and attack preparation
The attack began with compromised IAM user credentials possessing admin-like privileges from an anomalous network and location, triggering GuardDuty anomaly detection findings. During the discovery phase, the attacker systematically probed customer AWS environments to understand what resources they could deploy. They checked Amazon EC2 service quotas (GetServiceQuota) to determine how many instances they could launch, then tested their permissions by calling the RunInstances API multiple times with the DryRun flag enabled.
The DryRun flag was a deliberate reconnaissance tactic that allowed the actor to validate their IAM permissions without actually launching instances, avoiding costs and reducing their detection footprint. This technique demonstrates the threat actor was validating their ability to deploy crypto mining infrastructure before acting. Organizations that don’t typically use DryRun flags in their environments should consider monitoring for this API pattern as an early warning indicator of compromise. AWS CloudTrail logs can be used with Amazon CloudWatch alarms, Amazon EventBridge, or your third-party tooling to alert on these suspicious API patterns.
The threat actor called two APIs to create IAM roles as part of their attack infrastructure: CreateServiceLinkedRole to create a role for auto scaling groups and CreateRole to create a role for AWS Lambda. They then attached the AWSLambdaBasicExecutionRole policy to the Lambda role. These two roles were integral to the impact and persistence stages of the attack.
Amazon ECS impact
The threat actor first created dozens of ECS clusters across the environment, sometimes exceeding 50 ECS clusters in a single attack. They then called RegisterTaskDefinition with a malicious Docker Hub image yenik65958/secret:user. With the same string used for the cluster creation, the actor then created a service, using the task definition to initiate crypto mining on ECS AWS Fargate nodes. The following is an example of API request parameters for RegisterTaskDefinition with a maximum CPU allocation of 16,384 units.
{
"dryrun": false,
"requiresCompatibilities": ["FARGATE"],
"cpu": 16384,
"containerDefinitions": [
{
"name": "a1b2c3d4e5",
"image": "yenik65958/secret:user",
"cpu": 0,
"command": []
}
],
"networkMode": "awsvpc",
"family": "a1b2c3d4e5",
"memory": 32768
}Using this task definition, the threat actor called CreateService to launch ECS Fargate tasks with a desired count of 10.
{
"dryrun": false,
"capacityProviderStrategy": [
{
"capacityProvider": "FARGATE",
"weight": 1,
"base": 0
},
{
"capacityProvider": "FARGATE_SPOT",
"weight": 1,
"base": 0
}
],
"desiredCount": 10
}
Figure 2: Contents of the cryptocurrency mining script within the malicious image
The malicious image (yenik65958/secret:user) was configured to execute run.sh after it has been deployed. run.sh runs randomvirel mining algorithm with the mining pools: asia|eu|na[.]rplant[.]xyz:17155. The flag nproc --all indicates that the script should use all processor cores.
Amazon EC2 impact
The actor created two launch templates (CreateLaunchTemplate) and 14 auto scaling groups (CreateAutoScalingGroup) configured with aggressive scaling parameters, including a maximum size of 999 instances and desired capacity of 20. The following example of request parameters from CreateLaunchTemplate shows the UserData was supplied, instructing the instances to begin crypto mining.
{
"CreateLaunchTemplateRequest": {
"LaunchTemplateName": "T-us-east-1-a1b2",
"LaunchTemplateData": {
"UserData": "<sensitiveDataRemoved>",
"ImageId": "ami-1234567890abcdef0",
"InstanceType": "c6a.4xlarge"
},
"ClientToken": "a1b2c3d4-5678-90ab-cdef-EXAMPLE11111"
}
}The threat actor created auto scaling groups using both Spot and On-Demand Instances to make use of both Amazon EC2 service quotas and maximize resource consumption.
Spot Instance groups:
- Targeted high performance GPU and machine learning (ML) instances (g4dn, g5, g5, p3, p4d, inf1)
- Configured with 0% on-demand allocation and capacity-optimized strategy
- Set to scale from 20 to 999 instances
On-Demand Instance groups:
- Targeted compute, memory, and general-purpose instances (c5, c6i, r5, r5n, m5a, m5, m5n).
- Configured with 100% on-demand allocation
- Also set to scale from 20 to 999 instances
After exhausting auto scaling quotas, the actor directly launched additional EC2 instances using RunInstances to consume the remaining EC2 instance quota.
Persistence
An interesting technique observed in this campaign was the threat actor’s use of ModifyInstanceAttribute across all launched EC2 instances to disable API termination. Although instance termination protection prevents accidental termination of the instance, it adds an additional consideration for incident response capabilities and can disrupt automated remediation controls. The following example shows request parameters for the API ModifyInstanceAttribute.
{
"disableApiTermination": {
"value": true
},
"instanceId": "i-1234567890abcdef0"
}After all mining workloads were deployed, the actor created a Lambda function with a configuration that bypasses IAM authentication and creates a public Lambda endpoint. The threat actor then added a permission to the Lambda function that allows the principal to invoke the function. The following examples show CreateFunctionUrlConfig and AddPermission request parameters.
CreateFunctionUrlConfig:
{
"authType": "NONE",
"functionName": "generate-service-a1b2c3d4"
}AddPermission:
{
"functionName": "generate-service-a1b2c3d4",
"functionUrlAuthType": "NONE",
"principal": "*",
"statementId": "FunctionURLAllowPublicAccess",
"action": "lambda:InvokeFunctionUrl"
}The threat actor concluded the persistence stage by creating an IAM user user-x1x2x3x4 and attaching the IAM policy AmazonSESFullAccess (CreateUser, AttachUserPolicy). They also created an access key and login profile for that user (CreateAccessKey, CreateLoginProfile). Based on the SES role that was attached to the user, it appears the threat actor was attempting Amazon Simple Email Service (Amazon SES) phishing.
To prevent public Lambda URLs from being created, organizations can deploy service control policies (SCPs) that deny creation or updating of Lambda URLs with an AuthType of “NONE”.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Action": [
"lambda:CreateFunctionUrlConfig",
"lambda:UpdateFunctionUrlConfig"
],
"Resource": "arn:aws:lambda:*:*:function/*",
"Condition": {
"StringEquals": {
"lambda:FunctionUrlAuthType": "NONE"
}
}
}
]
}Detection methods using GuardDuty
The multilayered detection approach of GuardDuty proved highly effective in identifying all stages of the attack chain using threat intelligence, anomaly detection, and the recently launched Extended Threat Detection capabilities for EC2 and ECS.
Next, we walk through the details of these features and how you can deploy them to detect attacks such as these. You can enable GuardDuty foundational protection plan to receive alerts on crypto mining campaigns like the one described in this post. To further enhance detection capabilities, we highly recommend enabling GuardDuty Runtime Monitoring, which will extend finding coverage to system-level events on Amazon EC2, Amazon ECS, and Amazon Elastic Kubernetes Service (Amazon EKS).
GuardDuty EC2 findings
Threat intelligence findings for Amazon EC2 are part of the GuardDuty foundational protection plan, which will alert you to suspicious network behaviors involving your instances. These behaviors can include brute force attempts, connections to malicious or crypto domains, and other suspicious behaviors. Using third-party threat intelligence and internal threat intelligence, including active threat defense and MadPot, GuardDuty provides detection over the indicators in this post through the following findings: CryptoCurrency:EC2/BitcoinTool.B and CryptoCurrency:EC2/BitcoinTool.B!DNS.
GuardDuty IAM findings
The IAMUser/AnomalousBehavior findings spanning multiple tactic categories (PrivilegeEscalation, Impact, Discovery) showcase the ML capability of GuardDuty to detect deviations from normal user behavior. In the incident described in this post, the compromised credentials were detected due to the threat actor using them from an anomalous network and location and calling APIs that were unusual for the accounts.
GuardDuty Runtime Monitoring
GuardDuty Runtime Monitoring is an important component for Extended Threat Detection attack sequence correlation. Runtime Monitoring provides host level signals, such as operating system visibility, and extends detection coverage by analyzing system-level logs indicating malicious process execution at the host and container level, including the execution of crypto mining programs on your workloads. The CryptoCurrency:Runtime/BitcoinTool.B!DNS and CryptoCurrency:Runtime/BitcoinTool.B findings detect network connections to crypto-related domains and IPs, while the Impact:Runtime/CryptoMinerExecuted finding detects when a process running is associated with a cryptocurrency mining activity.
GuardDuty Extended Threat Detection
Launched at re:Invent 2025, AttackSequence:EC2/CompromisedInstanceGroup finding represents one of the latest Extended Threat Detection capabilities in GuardDuty. This feature uses AI and ML algorithms to automatically correlate security signals across multiple data sources to detect sophisticated attack patterns of EC2 resource groups. Although AttackSequences for EC2 are included in the GuardDuty foundational protection plan, we strongly recommend enabling Runtime Monitoring. Runtime Monitoring provides key insights and signals from compute environments, enabling detection of suspicious host-level activities and improving correlation of attack sequences. For AttackSequence:ECS/CompromisedCluster attack sequences, Runtime Monitoring is required to correlate container-level activity.
Monitoring and remediation recommendations
To protect against similar crypto mining attacks, AWS customers should prioritize strong identity and access management controls. Implement temporary credentials instead of long-term access keys, enforce multi-factor authentication (MFA) for all users, and apply least privilege to IAM principals limiting access to only required permissions. You can use AWS CloudTrail to log events across AWS services and combine logs into a single account to make them available to your security teams to access and monitor. To learn more, refer to Receiving CloudTrail log files from multiple accounts in the CloudTrail documentation.
Confirm GuardDuty is enabled across all accounts and Regions with Runtime Monitoring enabled for comprehensive coverage. Integrate GuardDuty with AWS Security Hub and Amazon EventBridge or third-party tooling to enable automated response workflows and rapid remediation of high-severity findings. Implement container security controls, including image scanning policies and monitoring for unusual CPU allocation requests in ECS task definitions. Finally, establish specific incident response procedures for crypto mining attacks, including documented steps to handle instances with disabled API termination—a technique used by this attacker to complicate remediation efforts.
If you believe your AWS account has been impacted by a crypto mining campaign, refer to remediation steps in the GuardDuty documentation: Remediating potentially compromised AWS credentials, Remediating a potentially compromised EC2 instance, and Remediating a potentially compromised ECS cluster.
To stay up to date on the latest techniques, visit the Threat Technique Catalog for AWS.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.