Local KTAE and the IDA Pro plugin | Kaspersky official blog
In a previous post, we walked through a practical example of how threat attribution helps in incident investigations. We also introduced the Kaspersky Threat Attribution Engine (KTAE) — our tool for making an educated guess about which specific APT group a malware sample belongs to. To demonstrate it, we used the Kaspersky Threat Intelligence Portal — a cloud-based tool that provides access to KTAE as part of our comprehensive Threat Analysis service, alongside a sandbox and a non-attributing similarity-search tool. The advantages of a cloud service are obvious: clients don’t need to invest in hardware, install anything, or manage any software. However, as real-world experience shows, the cloud version of an attribution tool isn’t for everyone…
First, some organizations are bound by regulatory restrictions that strictly forbid any data from leaving their internal perimeter. For the security analysts at these firms, uploading files to a third-party service is out of the question. Second, some companies employ hardcore threat hunters who need a more flexible toolkit — one that lets them work with their own proprietary research alongside Kaspersky’s threat intelligence. That’s why KTAE is available in two flavors: a cloud-based version and an on-prem deployment.
What are the on-prem KTAE advantages over the cloud version?
First off, the local version of KTAE ensures an investigation stays fully confidential. All the analysis takes place right in the organization’s internal network. The threat intelligence source is a database deployed inside the company perimeter; it is packed with the unique indicators and attribution data of every malicious sample known to our experts; and it also contains the characteristics pertaining to legitimate files to exclude false-positive detections. The database gets regular updates, but it operates one-way: no information ever leaves the client’s network.
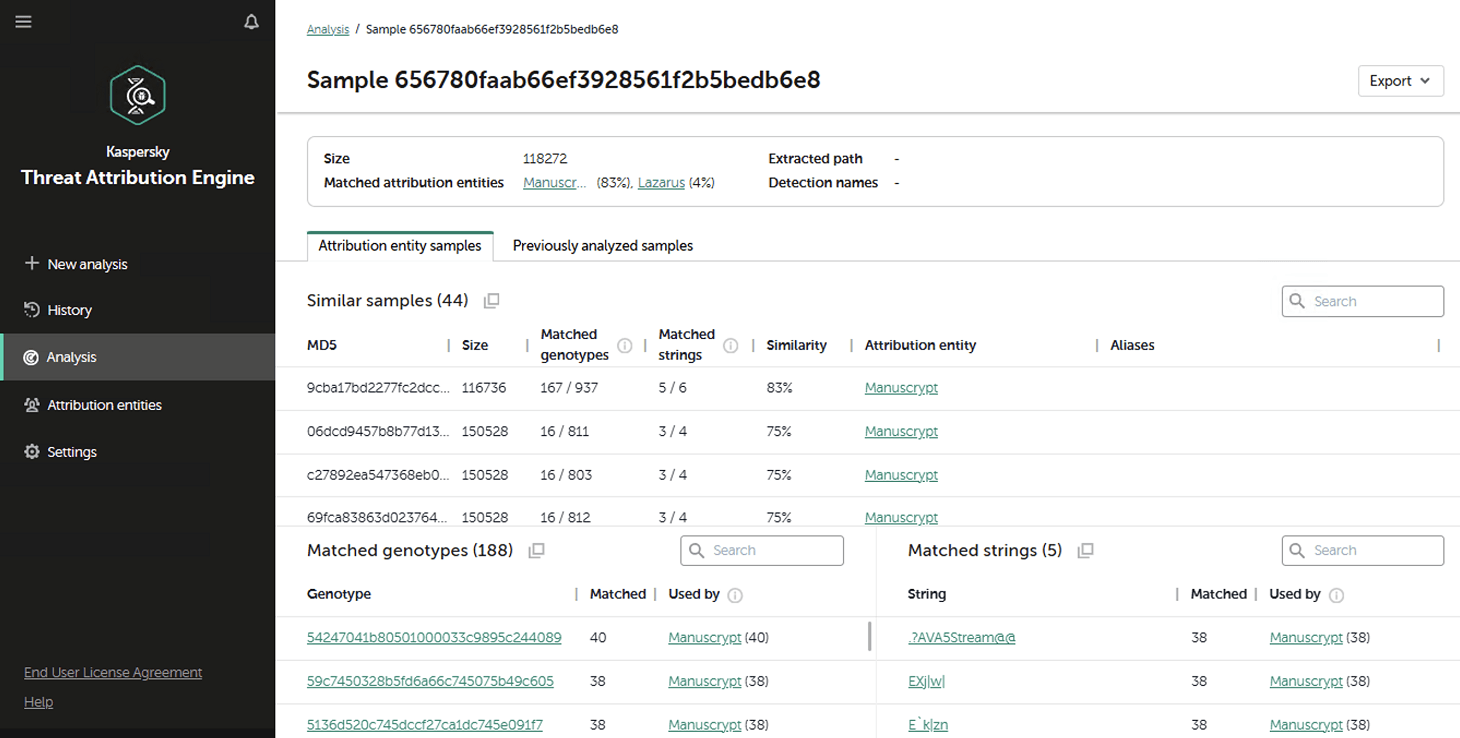
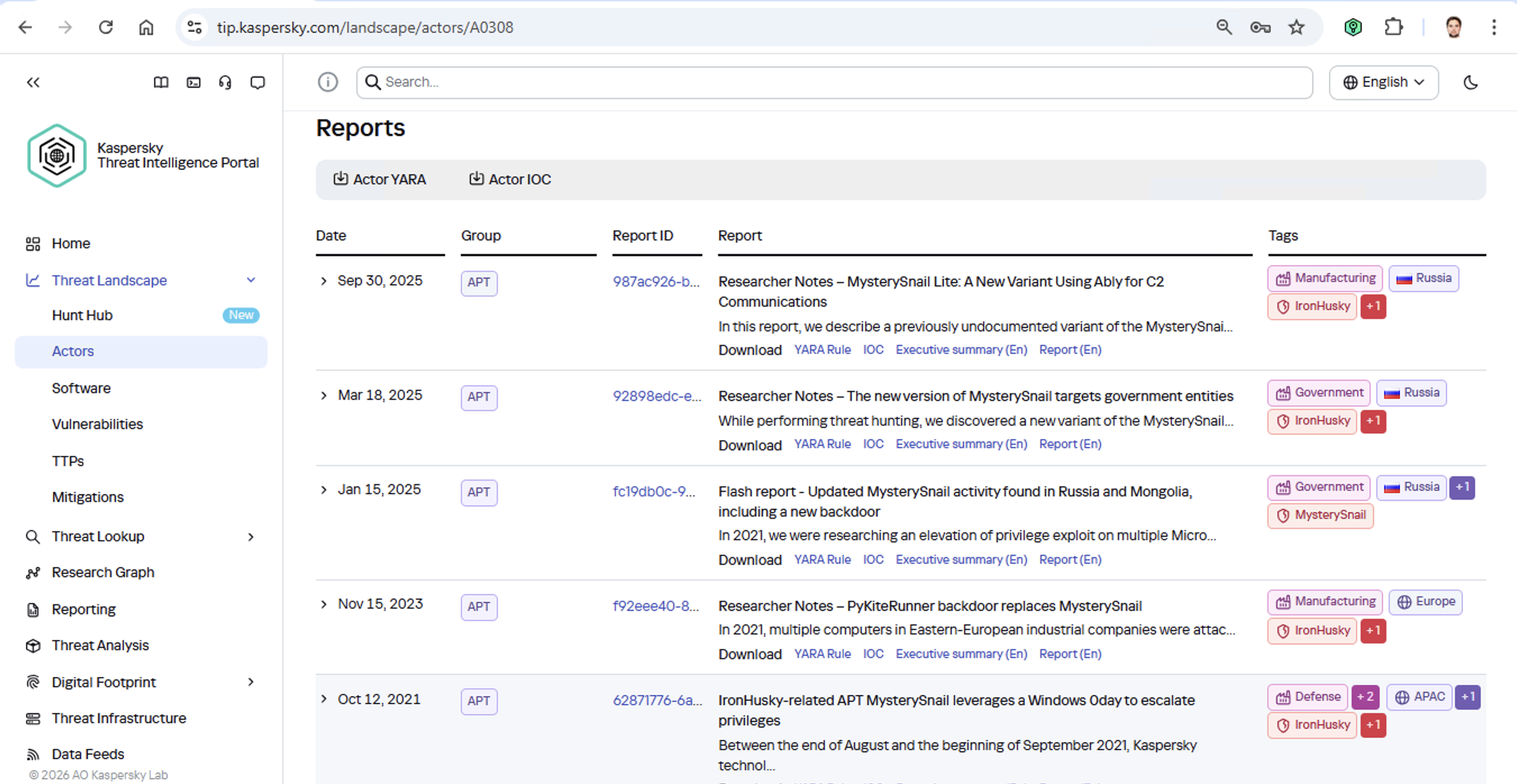
Additionally, the on-prem version of KTAE gives experts the ability to add new threat groups to the database and link them to malware samples they discovered on their own. This means that subsequent attribution of new files will account for the data added by internal researchers. This allows experts to catalog their own unique malware clusters, work with them, and identify similarities.
Here’s another handy expert tool: our team has developed a free plugin for IDA Pro, a popular disassembler, for use with the local version of KTAE.
What’s the purpose of an attribution plugin for a disassembler?
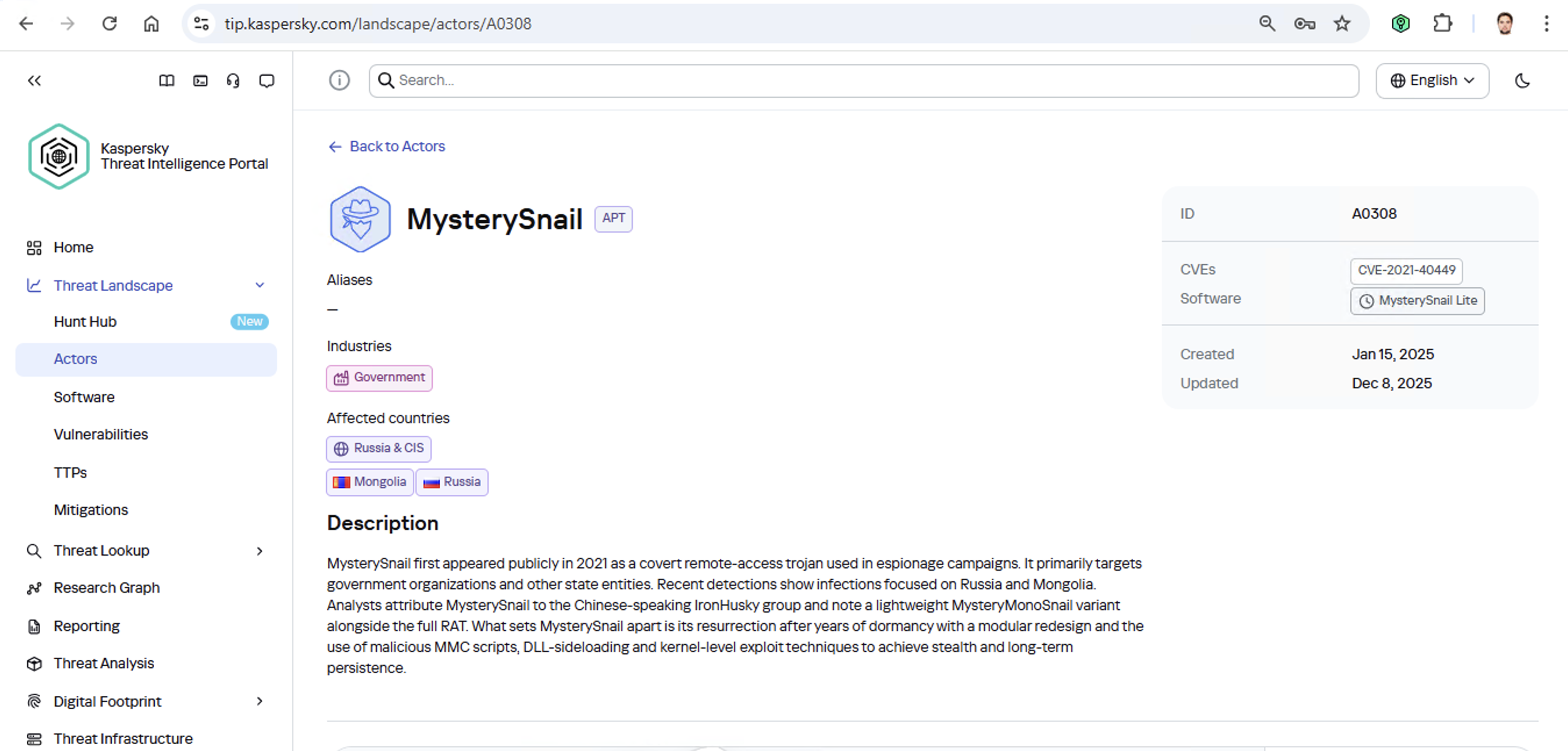
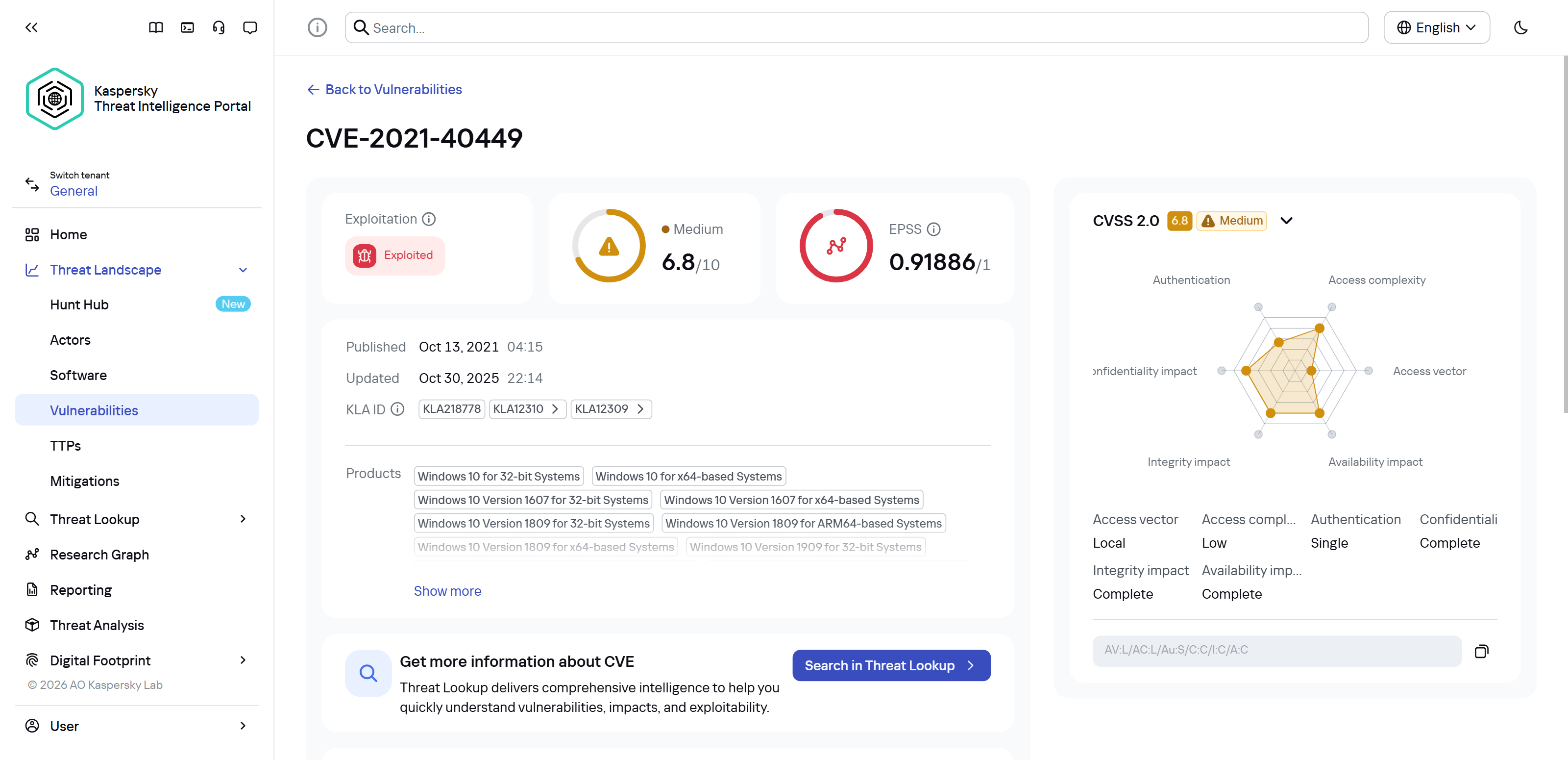
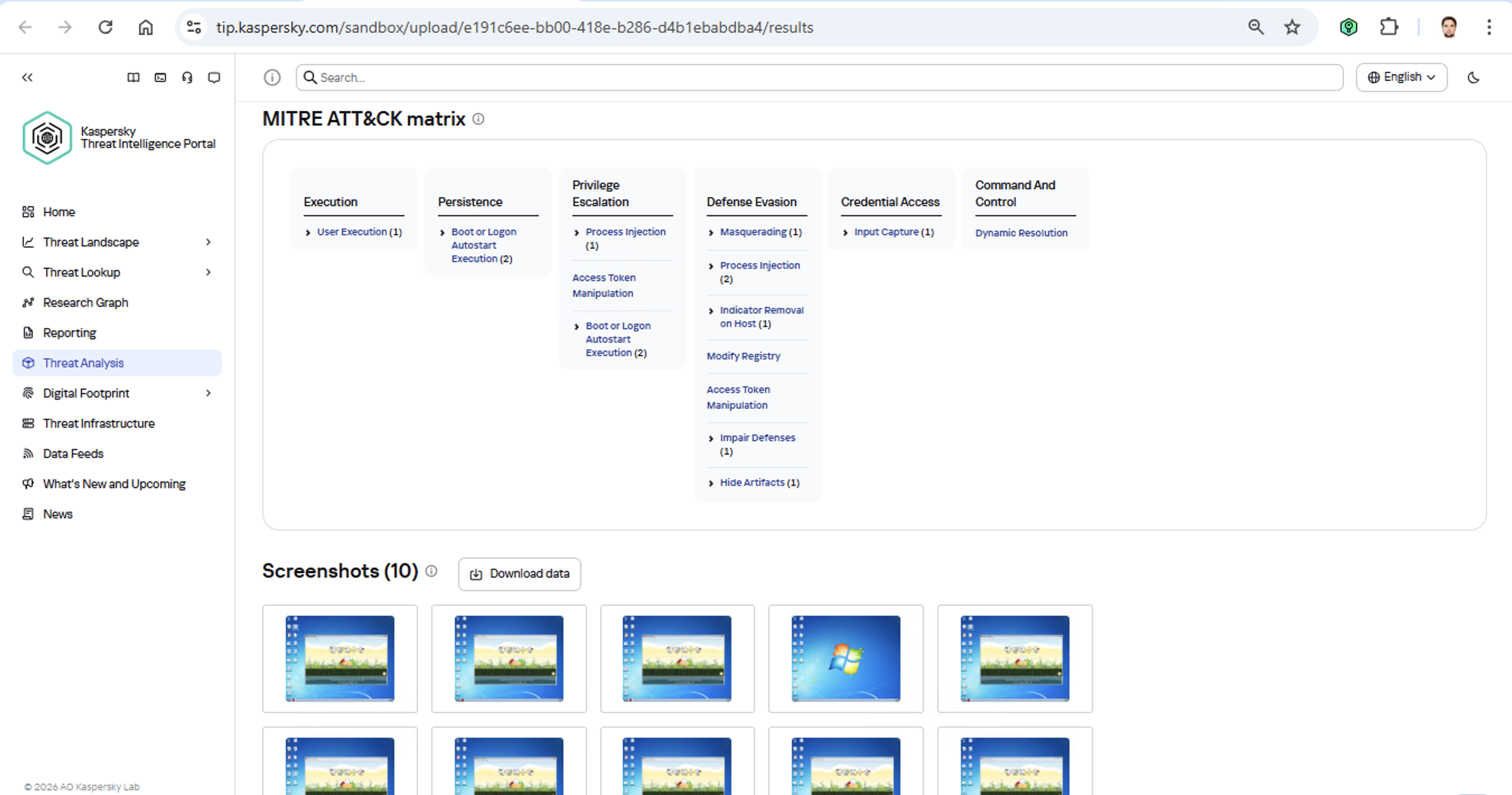
For a SOC analyst on alert triage, attributing a malicious file found in the infrastructure is straightforward: just upload it to KTAE (cloud or on-prem) and get a verdict, like Manuscrypt (83%). That’s sufficient for taking adequate countermeasures against that group’s known toolkit and assessing the overall situation. A threat hunter, however, might not want to take that verdict at face value. Alternatively, they might ask, “Which code fragments are unique across all the malware samples used by this group?” Here an attribution plugin for a disassembler comes in handy.
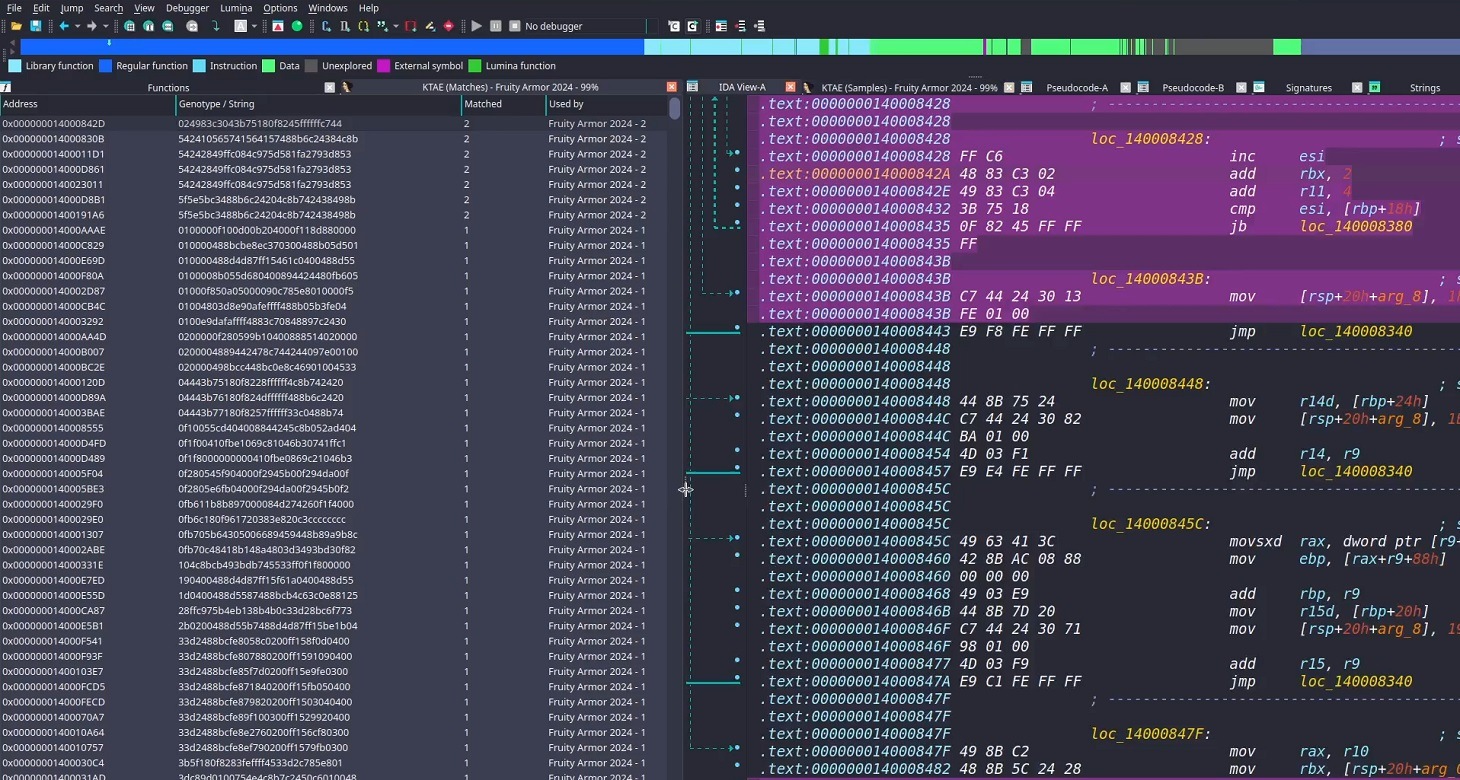
Inside the IDA Pro interface, the plugin highlights the specific disassembled code fragments that triggered the attribution algorithm. This doesn’t just allow for a more expert-level deep dive into new malware samples; it also lets Kaspersky researchers refine attribution rules on the fly. As a result, the algorithm — and KTAE itself — keeps evolving, making attribution more accurate with every run.
How to set up the plugin
The plugin is a script written in Python. To get it up and running you need IDA Pro. Unfortunately, it won’t work in IDA Free, since it lacks support for Python plugins. If you don’t have Python installed yet, you’d need to grab that, set up the dependencies (check the requirements file in our GitHub repository), and make sure IDA Pro environment variables are pointing to the Python libraries.
Next, you’d need to insert the URL for your local KTAE instance into the script body and provide your API token (which is available on a commercial basis) — just like it’s done in the example script described in the KTAE documentation.
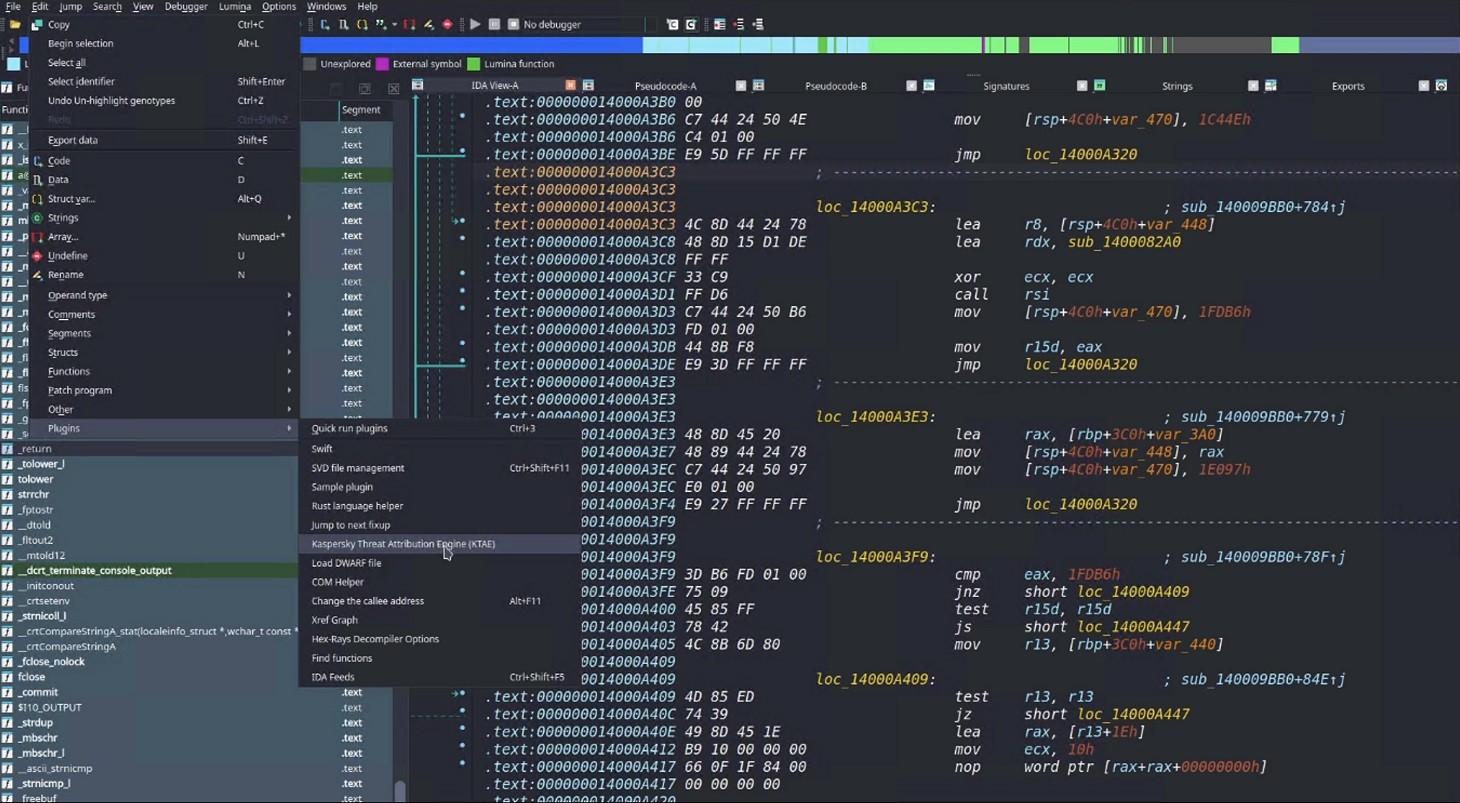
Then you can simply drop the script into your IDA Pro plugins folder and fire up the disassembler. If you’ve done it right, then, after loading and disassembling a sample, you’ll see the option to launch the Kaspersky Threat Attribution Engine (KTAE) plugin under Edit → Plugins:
How to use the plugin
When the plugin is installed, here’s what happens under the hood: the file currently loaded in IDA Pro is sent via API to the locally installed KTAE service, at the URL configured in the script. The service analyzes the file, and the analysis results are piped right back into IDA Pro.
On a local network, the script usually finishes its job in a matter of seconds (the duration depends on the connection to the KTAE server and the size of the analyzed file). Once the plugin wraps up, a researcher can start digging into the highlighted code fragments. A double-click leads straight to the relevant section in the assembly or binary code (Hex view) for analysis. These extra data points make it easy to spot shared code blocks and track changes in a malware toolkit.
To learn more about the Kaspersky Threat Attribution Engine and how to deploy it, check out the official product documentation. And to arrange a demonstration or piloting project, please fill out the form on the Kaspersky website.