Torq Raises $140 Million at $1.2 Billion Valuation
The company will use the investment to accelerate platform adoption and expansion into the federal market.
The post Torq Raises $140 Million at $1.2 Billion Valuation appeared first on SecurityWeek.
The company will use the investment to accelerate platform adoption and expansion into the federal market.
The post Torq Raises $140 Million at $1.2 Billion Valuation appeared first on SecurityWeek.
You read the “AI-ready SOC pillars” blog, but you still see a lot of this:

How do we do better?
Let’s go through all 5 pillars aka readiness dimensions and see what we can actually do to make your SOC AI-ready.
#1 SOC Data Foundations
As I said before, this one is my absolute favorite and is at the center of most “AI in SOC” (as you recall, I want AI in my SOC, but I dislike the “AI SOC” concept) successes (if done well) and failures (if not done at all).
Reminder: pillar #1 is “security context and data are available and can be queried by machines (API, Model Context Protocol (MCP), etc) in a scalable and reliable manner.” Put simply, for the AI to work for you, it needs your data. As our friends say here, “Context engineering focuses on what information the AI has available. […] For security operations, this distinction is critical. Get the context wrong, and even the most sophisticated model will arrive at inaccurate conclusions.”
Readiness check: Security context and data are available and can be queried by machines in a scalable and reliable manner. This is very easy to check, yet not easy to achieve for many types of data.
For example, “give AI access to past incidents” is very easy in theory (“ah, just give it old tickets”) yet often very hard in reality (“what tickets?” “aren’t some too sensitive?”, “wait…this ticket didn’t record what happened afterwards and it totally changed the outcome”, “well, these tickets are in another system”, etc, etc)
Steps to get ready:
Where you arrive: your AI component, AI-powered tool or AI agent can get the data it needs nearly every time. The cases where it cannot become visible, and obvious immediately.
#2 SOC Process Framework and Maturity
Reminder: pillar #2 is “Common SOC workflows do NOT rely on human-to-human communication are essential for AI success.” As somebody called it, you need “machine-intelligible processes.”
Readiness check: SOC workflows are defined as machine-intelligible processes that can be queried programmatically, and explicit, structured handoff criteria are established for all Human-in-the-Loop (HITL) processes, clearly delineating what is handled by the agent versus the person. Examples for handoff to human may include high decision uncertainty, lack of context to make a call (see pillar #1), extra-sensitive systems, etc.
Common investigation and response workflows do not rely on ad-hoc, human-to-human communication or “tribal knowledge,” such knowledge is discovered and brought to surface.
Steps to get ready:
Where you arrive: The “tribal knowledge” that previously drove your SOC is recorded for machine-readable workflows. Explicit, structured handoff points are established for all Human-in-the-Loop processes, and the system uses human grading to continuously refine its logic and improve its ‘recipe’ over time. This does not mean that everything is rigid; “Visio diagram or death” SOC should stay in the 1990s. Recorded and explicit beats rigid and unchanging.
#3 SOC Human Element and Skills
Reminder: pillar #3 is “Cultivating a culture of augmentation, redefining analyst roles, providing training for human-AI collaboration, and embracing a leadership mindset that accepts probabilistic outcomes.” You say “fluffy management crap”? Well, I say “ignore this and your SOC is dead.”
Readiness check: Leaders have secured formal CISO sign-off on a quantified “AI Error Budget,” defining an acceptable, measured, probabilistic error rate for autonomously closed alerts (that is definitely not zero, BTW). The team is evolving to actively review, grade, and edit AI-generated logic and detection output.
Steps to get ready:
Where you arrive: well, you arrive at a practical realization that you have “AI in SOC” (and not AI SOC). The tools augment people (and in some cases, do the work end to end too). No pro- (“AI SOC means all humans can go home”) or contra-AI (“it makes mistakes and this means we cannot use it”) crazies nearby.
#4 Modern SOC Technology Stack
Reminder: pillar #4 is “Modern SOC Technology Stack.” If your tools lack APIs, take them and go back to the 1990s from whence you came! Destroy your time machine when you arrive, don’t come back to 2026!
Readiness check: The security stack is modern, fast (“no multi-hour data queries”) interoperable and supports new AI capabilities to integrate seamlessly, tools can communicate without a human acting as a manual bridge and can handle agentic AI request volumes.
Steps to get ready:
Where you arrive: this sounds like a perfect quote from Captain Obvious but you arrive at the SOC powered by tools that work with automation, and not with “human bridge” or “swivel chair.”
#5 SOC Metrics and Feedback Loop
Reminder: pillar #5 is “You are ready for AI if you can, after adding AI, answer the “what got better?” question. You need metrics and a feedback loop to get better.”
Readiness check: Hard baseline metrics (MTTR, MTTD, false positive rates) are established before AI deployment, and the team has a way to quantify the value and improvements resulting from AI. When things get better, you will know it.
Steps to get ready:
Where you arrive: you have a fact-based visual that shows your SOC becoming better in ways important to your mission after you add AI (in fact, you SOC will get better even before AI but after you do the prep-work from this document)
As a result, we can hopefully get to this instead:

The path to an AI-ready SOC isn’t paved with new tools; it’s paved with better data, cleaner processes, and a fundamental shift in how we think about human-machine collaboration. If you ignore these pillars, your AI journey will be a series of expensive lessons in why “magic” isn’t a strategy.
But if you get these right? You move from a SOC that is constantly drowning in alerts to a SOC that operates truly 10X effectiveness.

P.S. Anton, you said “10X”, so how does this relate to ASO and “engineering-led” D&R? I am glad you asked. The five pillars we outlined are not just steps for AI; they are the also steps on the road to ASO (see original 2021 paper which is still “the future” for many).
ASO is the vision for a 10X transformation of the SOC, driven by an adaptive, agile, and highly automated approach to threats. The focus on codified, machine-intelligible workflows, a modern stack supporting Detection-as-Code, and reskilling analysts as “Agent Supervisors” directly supports the core of engineering-led D&R. So focusing on these five readiness dimensions, you move from a traditional operations room (lots of “O” for operations) to a scalable, engineering-centric D&R function (where “E” for engineering dominates).
So, which pillar is your SOC’s current ‘weakest link’? Let’s discuss in the comments and on socials!
Related blogs and podcasts:
Beyond “Is Your SOC AI Ready?” Plan the Journey! was originally published in Anton on Security on Medium, where people are continuing the conversation by highlighting and responding to this story.

A SIEM is a complex system offering broad and flexible threat detection capabilities. Due to its complexity, its effectiveness heavily depends on how it is configured and what data sources are connected to it. A one-time SIEM setup during implementation is not enough: both the organization’s infrastructure and attackers’ techniques evolve over time. To operate effectively, the SIEM system must reflect the current state of affairs.
We provide customers with services to assess SIEM effectiveness, helping to identify issues and offering options for system optimization. In this article, we examine typical SIEM operational pitfalls and how to address them. For each case, we also include methods for independent verification.
This material is based on an assessment of Kaspersky SIEM effectiveness; therefore, all specific examples, commands, and field names are taken from that solution. However, the assessment methodology, issues we identified, and ways to enhance system effectiveness can easily be extrapolated to any other SIEM.
The primary audience for the effectiveness assessment report comprises the SIEM support and operation teams within an organization. The main goal is to analyze how well the usage of SIEM aligns with its objectives. Consequently, the scope of checks can vary depending on the stated goals. A standard assessment is conducted across the following areas:
At the same time, these areas are examined not only in isolation but also in terms of their potential influence on one another. Here are a couple of examples illustrating this interdependence:
deviceCustomString1 not contains <string> triggers a large number of alerts. The detection logic itself is correct: the specific event and the specific field it targets should not generate a large volume of data matching the condition. Our review revealed the issue was in the data ingested by the SIEM, where incorrect encoding caused the string targeted by the rule to be transformed into a different one. Consequently, all events matched the condition and generated alerts.The effectiveness assessment consists of several stages:
The assessment produces a list of recommendations. Some of these can be implemented almost immediately, while others require more comprehensive changes driven by process optimization or a transition to a more structured approach to system use.
The problems we identify during a SIEM effectiveness assessment can be divided into three groups:
When building the inventory of event sources for a SIEM, we follow the principle of layered monitoring: the system should have information about all detectable stages of an attack. This principle enables the detection of attacks even if individual malicious actions have gone unnoticed, and allows for retrospective reconstruction of the full attack chain, starting from the attackers’ point of entry.
Problem: During effectiveness assessments, we frequently find that the inventory of connected source types is not updated when the infrastructure changes. In some cases, it has not been updated since the initial SIEM deployment, which limits incident detection capabilities. Consequently, certain types of sources remain completely invisible to the system.
We have also encountered non-standard cases of incomplete source inventory. For example, an infrastructure contains hosts running both Windows and Linux, but monitoring is configured for only one family of operating systems.
How to detect: To identify the problems described above, determine the list of source types connected to the SIEM and compare it against what actually exists in the infrastructure. Identifying the presence of specific systems in the infrastructure requires an audit. However, this task is one of the most critical for many areas of cybersecurity, and we recommend running it on a periodic basis.
We have compiled a reference sheet of system types commonly found in most organizations. Depending on the organization type, infrastructure, and threat model, we may rearrange priorities. However, a good starting point is as follows:
Regardless of how good the detection logic is, it cannot function without telemetry from the data sources.
Problem: The SIEM core is not receiving events from specific sources or collectors. Based on all assessments conducted, the average proportion of collectors that are configured with sources but are not transmitting events is 38%. Correlation rules may exist for these sources, but they will, of course, never trigger. It is also important to remember that a single collector can serve hundreds of sources (such as workstations), so the loss of data flow from even one collector can mean losing monitoring visibility for a significant portion of the infrastructure.
How to detect: The process of locating sources that are not transmitting data can be broken down into two components.
Offline, Stopped, Disabled, and so on.SELECT count(ID), CollectorID, CollectorName FROM `events` GROUP BY CollectorID, CollectorName ORDER BY count(ID)It is essential to specify an optimal time range for collecting these statistics. Too large a range can increase the load on the SIEM, while too small a range may provide inaccurate information for a one-time check – especially for sources that transmit telemetry relatively infrequently, say, once a week. Therefore, it is advisable to choose a smaller time window, such as 2–4 days, but run several queries for different periods in the past.
Additionally, for a more comprehensive approach, it is recommended to use built-in functionality or custom logic implemented via correlation rules and lists to monitor event flow. This will help automate the process of detecting problems with sources.
Problem: The system is not receiving events from all sources of a particular type that exist in the infrastructure. For example, the company uses workstations and servers running Windows. During SIEM deployment, workstations are immediately connected for monitoring, while the server segment is postponed for one reason or another. As a result, the SIEM receives events from Windows systems, the flow is normalized, and correlation rules work, but an incident in the unmonitored server segment would go unnoticed.
How to detect: Below are query variations that can be used to search for unconnected sources.
SELECT count(distinct, DeviceAddress), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)SELECT count(distinct, DeviceHostName), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)We have split the query into two variations because, depending on the source and the DNS integration settings, some events may contain either a DeviceAddress or DeviceHostName field.
These queries will help determine the number of unique data sources sending logs of a specific type. This count must be compared against the actual number of sources of that type, obtained from the system owners.
Raw data can be useful for developing custom normalizers or for storing events not used in correlation that might be needed during incident investigation. However, careless use of this setting can cause significantly more harm than good.
Problem: Enabling the Keep raw event option effectively doubles the event size in the database, as it stores two copies: the original and the normalized version. This is particularly critical for high-volume collectors receiving events from sources like NetFlow, DNS, firewalls, and others. It is worth noting that this option is typically used for testing a normalizer but is often forgotten and left enabled after its configuration is complete.
How to detect: This option is applied at the normalizer level. Therefore, it is necessary to review all active normalizers and determine whether retaining raw data is required for their operation.
As with the absence of events from sources, normalization issues lead to detection logic failing, as this logic relies on finding specific information in a specific event field.
Problem: Several issues related to normalization can be identified:
syslog_headers, placing the entire event body into a single field, this field most often being Message.How to detect: Identifying normalization issues is more challenging than spotting source problems due to the high volume of telemetry and variety of parsers. Here are several approaches to narrowing the search:
Linux audit and iptables syslog v2 for Kaspersky SIEM. The new normalizer completely reworks and optimizes the normalization schema for events from this source.SELECT count(ID), DeviceProduct, DeviceVendor, CollectorName FROM `events` GROUP BY DeviceProduct, DeviceVendor, CollectorName ORDER BY count(ID)This query gathers statistics on events from each collector, broken down by the DeviceVendor and DeviceProduct fields. While these fields are not mandatory, they are present in almost any normalization schema. Therefore, their complete absence or empty values may indicate normalization issues. We recommend including these fields when developing custom normalizers.
To simplify the identification of normalization problems when developing custom normalizers, you can implement the following mechanism. For each successfully normalized event, add a Name field, populated from a constant or the event itself. For a final catch-all normalizer that processes all unparsed events, set the constant value: Name = unparsed event. This will later allow you to identify non-normalized events through a simple search on this field.
Collected events alone are, in most cases, only useful for investigating an incident that has already been identified. For a SIEM to operate to its full potential, it requires detection logic to be developed to uncover probable security incidents.
Problem: The mean correlation rule coverage of sources, determined across all our assessments, is 43%. While this figure is only a ballpark figure – as different source types provide different information – to calculate it, we defined “coverage” as the presence of at least one correlation rule for a source. This means that for more than half of the connected sources, the SIEM is not actively detecting. Meanwhile, effort and SIEM resources are spent on connecting, maintaining, and configuring these sources. In some cases, this is formally justified, for instance, if logs are only needed for regulatory compliance. However, this is an exception rather than the rule.
We do not recommend solving this problem by simply not connecting sources to the SIEM. On the contrary, sources should be connected, but this should be done concurrently with the development of corresponding detection logic. Otherwise, it can be forgotten or postponed indefinitely, while the source pointlessly consumes system resources.
How to detect: This brings us back to auditing, a process that can be greatly aided by creating and maintaining a register of developed detection logic. Given that not every detection logic rule explicitly states the source type from which it expects telemetry, its description should be added to this register during the development phase.
If descriptions of the correlation rules are not available, you can refer to the following:
DeviceVendor, DeviceProduct (another argument for including these fields in the normalizer), Name, DeviceAction, DeviceEventCategory, DeviceEventClassID, and others. These can help identify the actual source.One criterion for correlation rules effectiveness is a low false positive rate.
Problem: Detection logic generates an abnormally high number of alerts that are physically impossible to process, regardless of the size of the SOC team.
How to detect: First and foremost, detection logic should be tested during development and refined to achieve an acceptable false positive rate. However, even a well-tuned correlation rule can start producing excessive alerts due to changes in the event flow or connected infrastructure. To identify these rules, we recommend periodically running the following query:
SELECT count(ID), Name FROM `events` WHERE Type = 3 GROUP BY Name ORDER BY count(ID)
In Kaspersky SIEM, a value of 3 in the Type field indicates a correlation event.
Subsequently, for each identified rule with an anomalous alert count, verify the correctness of the logic it uses and the integrity of the event stream on which it triggered.
Depending on the issue you identify, the solution may involve modifying the detection logic, adding exceptions (for example, it is often the case that 99% of the spam originates from just 1–5 specific objects, such as an IP address, a command parameter, or a URL), or adjusting event collection and normalization.
SIEM integrations with other systems are generally a critical part of both event processing and alert enrichment. In at least one specific case, their presence directly impacts detection performance: integration with technical Threat Intelligence data or IoCs (indicators of compromise).
A SIEM allows conveniently checking objects against various reputation databases or blocklists. Furthermore, there are numerous sources of this data that are ready to integrate natively with a SIEM or require minimal effort to incorporate.
Problem: There is no integration with TI data.
How to detect: Generally, IoCs are integrated into a SIEM at the system configuration level during deployment or subsequent optimization. The use of TI within a SIEM can be implemented at various levels:
Furthermore, TI data does not appear in a SIEM out of thin air. It is either provided by external suppliers (commercially or in an open format) or is part of the built-in functionality of the security tools in use. For instance, various NGFW systems can additionally check the reputation of external IP addresses or domains that users are accessing. Therefore, the first step is to determine whether you are receiving information about indicators of compromise and in what form (whether external providers’ feeds have been integrated and/or the deployed security tools have this capability). It is worth noting that receiving TI data only at the security tool level does not always cover all types of IoCs.
If data is being received in some form, the next step is to verify that the SIEM is utilizing it. For TI-related events coming from security tools, the SIEM needs a correlation rule developed to generate alerts. Thus, checking integration in this case involves determining the capabilities of the security tools, searching for the corresponding events in the SIEM, and identifying whether there is detection logic associated with these events. If events from the security tools are absent, the source audit configuration should be assessed to see if the telemetry type in question is being forwarded to the SIEM at all. If normalization is the issue, you should assess parsing accuracy and reconfigure the normalizer.
If TI data comes from external providers, determine how it is processed within the organization. Is there a centralized system for aggregating and managing threat data (such as CyberTrace), or is the information stored in, say, CSV files?
In the former case (there is a threat data aggregation and management system) you must check if it is integrated with the SIEM. For Kaspersky SIEM and CyberTrace, this integration is handled through the SIEM interface. Following this, SIEM event flows are directed to the threat data aggregation and management system, where matches are identified and alerts are generated, and then both are sent back to the SIEM. Therefore, checking the integration involves ensuring that all collectors receiving events that may contain IoCs are forwarding those events to the threat data aggregation and management system. We also recommend checking if the SIEM has a correlation rule that generates an alert based on matching detected objects with IoCs.
In the latter case (threat information is stored in files), you must confirm that the SIEM has a collector and normalizer configured to load this data into the system as events. Also, verify that logic is configured for storing this data within the SIEM for use in correlation. This is typically done with the help of lists that contain the obtained IoCs. Finally, check if a correlation rule exists that compares the event flow against these IoC lists.
As the examples illustrate, integration with TI in standard scenarios ultimately boils down to developing a final correlation rule that triggers an alert upon detecting a match with known IoCs. Given the variety of integration methods, creating and providing a universal out-of-the-box rule is difficult. Therefore, in most cases, to ensure IoCs are connected to the SIEM, you need to determine if the company has developed that rule (the existence of the rule) and if it has been correctly configured. If no correlation rule exists in the system, we recommend creating one based on the TI integration methods implemented in your infrastructure. If a rule does exist, its functionality must be verified: if there are no alerts from it, analyze its trigger conditions against the event data visible in the SIEM and adjust it accordingly.
For a SIEM to run effectively, it must contain current data about the infrastructure it monitors and the threats it’s meant to detect. Both elements change over time: new systems and software, users, security policies, and processes are introduced into the infrastructure, while attackers develop new techniques and tools. It is safe to assume that a perfectly configured and deployed SIEM system will no longer be able to fully see the altered infrastructure or the new threats after five years of running without additional configuration. Therefore, practically all components – event collection, detection, additional integrations for contextual information, and exclusions – must be maintained and kept up to date.
Furthermore, it is important to acknowledge that it is impossible to cover 100% of all threats. Continuous research into attacks, development of detection methods, and configuration of corresponding rules are a necessity. The SOC itself also evolves. As it reaches certain maturity levels, new growth opportunities open up for the team, requiring the utilization of new capabilities.
Problem: The SIEM has not evolved since its initial deployment.
How to detect: Compare the original statement of work or other deployment documentation against the current state of the system. If there have been no changes, or only minimal ones, it is highly likely that your SIEM has areas for growth and optimization. Any infrastructure is dynamic and requires continuous adaptation.
In this article, we have outlined the primary problems we identify during SIEM effectiveness assessments, but this list is not exhaustive. We also frequently encounter:
[dev] test_Add user to admin group_final2.Generally, most issues with SIEM effectiveness stem from the natural degradation (accumulation of errors) of the processes implemented within the system. Therefore, in most cases, maintaining effectiveness involves structuring these processes, monitoring the quality of SIEM engagement at all stages (source onboarding, correlation rule development, normalization, and so on), and conducting regular reviews of all system components and resources.
A SIEM is a powerful tool for monitoring and detecting threats, capable of identifying attacks at various stages across nearly any point in an organization’s infrastructure. However, if improperly configured and operated, it can become ineffective or even useless while still consuming significant resources. Therefore, it is crucial to periodically audit the SIEM’s components, settings, detection rules, and data sources.
If a SOC is overloaded or otherwise unable to independently identify operational issues with its SIEM, we offer Kaspersky SIEM platform users a service to assess its operation. Following the assessment, we provide a list of recommendations to address the issues we identify. That being said, it is important to clarify that these are not strict, prescriptive instructions, but rather highlight areas that warrant attention and analysis to improve the product’s performance, enhance threat detection accuracy, and enable more efficient SIEM utilization.




A SIEM is a complex system offering broad and flexible threat detection capabilities. Due to its complexity, its effectiveness heavily depends on how it is configured and what data sources are connected to it. A one-time SIEM setup during implementation is not enough: both the organization’s infrastructure and attackers’ techniques evolve over time. To operate effectively, the SIEM system must reflect the current state of affairs.
We provide customers with services to assess SIEM effectiveness, helping to identify issues and offering options for system optimization. In this article, we examine typical SIEM operational pitfalls and how to address them. For each case, we also include methods for independent verification.
This material is based on an assessment of Kaspersky SIEM effectiveness; therefore, all specific examples, commands, and field names are taken from that solution. However, the assessment methodology, issues we identified, and ways to enhance system effectiveness can easily be extrapolated to any other SIEM.
The primary audience for the effectiveness assessment report comprises the SIEM support and operation teams within an organization. The main goal is to analyze how well the usage of SIEM aligns with its objectives. Consequently, the scope of checks can vary depending on the stated goals. A standard assessment is conducted across the following areas:
At the same time, these areas are examined not only in isolation but also in terms of their potential influence on one another. Here are a couple of examples illustrating this interdependence:
deviceCustomString1 not contains <string> triggers a large number of alerts. The detection logic itself is correct: the specific event and the specific field it targets should not generate a large volume of data matching the condition. Our review revealed the issue was in the data ingested by the SIEM, where incorrect encoding caused the string targeted by the rule to be transformed into a different one. Consequently, all events matched the condition and generated alerts.The effectiveness assessment consists of several stages:
The assessment produces a list of recommendations. Some of these can be implemented almost immediately, while others require more comprehensive changes driven by process optimization or a transition to a more structured approach to system use.
The problems we identify during a SIEM effectiveness assessment can be divided into three groups:
When building the inventory of event sources for a SIEM, we follow the principle of layered monitoring: the system should have information about all detectable stages of an attack. This principle enables the detection of attacks even if individual malicious actions have gone unnoticed, and allows for retrospective reconstruction of the full attack chain, starting from the attackers’ point of entry.
Problem: During effectiveness assessments, we frequently find that the inventory of connected source types is not updated when the infrastructure changes. In some cases, it has not been updated since the initial SIEM deployment, which limits incident detection capabilities. Consequently, certain types of sources remain completely invisible to the system.
We have also encountered non-standard cases of incomplete source inventory. For example, an infrastructure contains hosts running both Windows and Linux, but monitoring is configured for only one family of operating systems.
How to detect: To identify the problems described above, determine the list of source types connected to the SIEM and compare it against what actually exists in the infrastructure. Identifying the presence of specific systems in the infrastructure requires an audit. However, this task is one of the most critical for many areas of cybersecurity, and we recommend running it on a periodic basis.
We have compiled a reference sheet of system types commonly found in most organizations. Depending on the organization type, infrastructure, and threat model, we may rearrange priorities. However, a good starting point is as follows:
Regardless of how good the detection logic is, it cannot function without telemetry from the data sources.
Problem: The SIEM core is not receiving events from specific sources or collectors. Based on all assessments conducted, the average proportion of collectors that are configured with sources but are not transmitting events is 38%. Correlation rules may exist for these sources, but they will, of course, never trigger. It is also important to remember that a single collector can serve hundreds of sources (such as workstations), so the loss of data flow from even one collector can mean losing monitoring visibility for a significant portion of the infrastructure.
How to detect: The process of locating sources that are not transmitting data can be broken down into two components.
Offline, Stopped, Disabled, and so on.SELECT count(ID), CollectorID, CollectorName FROM `events` GROUP BY CollectorID, CollectorName ORDER BY count(ID)It is essential to specify an optimal time range for collecting these statistics. Too large a range can increase the load on the SIEM, while too small a range may provide inaccurate information for a one-time check – especially for sources that transmit telemetry relatively infrequently, say, once a week. Therefore, it is advisable to choose a smaller time window, such as 2–4 days, but run several queries for different periods in the past.
Additionally, for a more comprehensive approach, it is recommended to use built-in functionality or custom logic implemented via correlation rules and lists to monitor event flow. This will help automate the process of detecting problems with sources.
Problem: The system is not receiving events from all sources of a particular type that exist in the infrastructure. For example, the company uses workstations and servers running Windows. During SIEM deployment, workstations are immediately connected for monitoring, while the server segment is postponed for one reason or another. As a result, the SIEM receives events from Windows systems, the flow is normalized, and correlation rules work, but an incident in the unmonitored server segment would go unnoticed.
How to detect: Below are query variations that can be used to search for unconnected sources.
SELECT count(distinct, DeviceAddress), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)SELECT count(distinct, DeviceHostName), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)We have split the query into two variations because, depending on the source and the DNS integration settings, some events may contain either a DeviceAddress or DeviceHostName field.
These queries will help determine the number of unique data sources sending logs of a specific type. This count must be compared against the actual number of sources of that type, obtained from the system owners.
Raw data can be useful for developing custom normalizers or for storing events not used in correlation that might be needed during incident investigation. However, careless use of this setting can cause significantly more harm than good.
Problem: Enabling the Keep raw event option effectively doubles the event size in the database, as it stores two copies: the original and the normalized version. This is particularly critical for high-volume collectors receiving events from sources like NetFlow, DNS, firewalls, and others. It is worth noting that this option is typically used for testing a normalizer but is often forgotten and left enabled after its configuration is complete.
How to detect: This option is applied at the normalizer level. Therefore, it is necessary to review all active normalizers and determine whether retaining raw data is required for their operation.
As with the absence of events from sources, normalization issues lead to detection logic failing, as this logic relies on finding specific information in a specific event field.
Problem: Several issues related to normalization can be identified:
syslog_headers, placing the entire event body into a single field, this field most often being Message.How to detect: Identifying normalization issues is more challenging than spotting source problems due to the high volume of telemetry and variety of parsers. Here are several approaches to narrowing the search:
Linux audit and iptables syslog v2 for Kaspersky SIEM. The new normalizer completely reworks and optimizes the normalization schema for events from this source.SELECT count(ID), DeviceProduct, DeviceVendor, CollectorName FROM `events` GROUP BY DeviceProduct, DeviceVendor, CollectorName ORDER BY count(ID)This query gathers statistics on events from each collector, broken down by the DeviceVendor and DeviceProduct fields. While these fields are not mandatory, they are present in almost any normalization schema. Therefore, their complete absence or empty values may indicate normalization issues. We recommend including these fields when developing custom normalizers.
To simplify the identification of normalization problems when developing custom normalizers, you can implement the following mechanism. For each successfully normalized event, add a Name field, populated from a constant or the event itself. For a final catch-all normalizer that processes all unparsed events, set the constant value: Name = unparsed event. This will later allow you to identify non-normalized events through a simple search on this field.
Collected events alone are, in most cases, only useful for investigating an incident that has already been identified. For a SIEM to operate to its full potential, it requires detection logic to be developed to uncover probable security incidents.
Problem: The mean correlation rule coverage of sources, determined across all our assessments, is 43%. While this figure is only a ballpark figure – as different source types provide different information – to calculate it, we defined “coverage” as the presence of at least one correlation rule for a source. This means that for more than half of the connected sources, the SIEM is not actively detecting. Meanwhile, effort and SIEM resources are spent on connecting, maintaining, and configuring these sources. In some cases, this is formally justified, for instance, if logs are only needed for regulatory compliance. However, this is an exception rather than the rule.
We do not recommend solving this problem by simply not connecting sources to the SIEM. On the contrary, sources should be connected, but this should be done concurrently with the development of corresponding detection logic. Otherwise, it can be forgotten or postponed indefinitely, while the source pointlessly consumes system resources.
How to detect: This brings us back to auditing, a process that can be greatly aided by creating and maintaining a register of developed detection logic. Given that not every detection logic rule explicitly states the source type from which it expects telemetry, its description should be added to this register during the development phase.
If descriptions of the correlation rules are not available, you can refer to the following:
DeviceVendor, DeviceProduct (another argument for including these fields in the normalizer), Name, DeviceAction, DeviceEventCategory, DeviceEventClassID, and others. These can help identify the actual source.One criterion for correlation rules effectiveness is a low false positive rate.
Problem: Detection logic generates an abnormally high number of alerts that are physically impossible to process, regardless of the size of the SOC team.
How to detect: First and foremost, detection logic should be tested during development and refined to achieve an acceptable false positive rate. However, even a well-tuned correlation rule can start producing excessive alerts due to changes in the event flow or connected infrastructure. To identify these rules, we recommend periodically running the following query:
SELECT count(ID), Name FROM `events` WHERE Type = 3 GROUP BY Name ORDER BY count(ID)
In Kaspersky SIEM, a value of 3 in the Type field indicates a correlation event.
Subsequently, for each identified rule with an anomalous alert count, verify the correctness of the logic it uses and the integrity of the event stream on which it triggered.
Depending on the issue you identify, the solution may involve modifying the detection logic, adding exceptions (for example, it is often the case that 99% of the spam originates from just 1–5 specific objects, such as an IP address, a command parameter, or a URL), or adjusting event collection and normalization.
SIEM integrations with other systems are generally a critical part of both event processing and alert enrichment. In at least one specific case, their presence directly impacts detection performance: integration with technical Threat Intelligence data or IoCs (indicators of compromise).
A SIEM allows conveniently checking objects against various reputation databases or blocklists. Furthermore, there are numerous sources of this data that are ready to integrate natively with a SIEM or require minimal effort to incorporate.
Problem: There is no integration with TI data.
How to detect: Generally, IoCs are integrated into a SIEM at the system configuration level during deployment or subsequent optimization. The use of TI within a SIEM can be implemented at various levels:
Furthermore, TI data does not appear in a SIEM out of thin air. It is either provided by external suppliers (commercially or in an open format) or is part of the built-in functionality of the security tools in use. For instance, various NGFW systems can additionally check the reputation of external IP addresses or domains that users are accessing. Therefore, the first step is to determine whether you are receiving information about indicators of compromise and in what form (whether external providers’ feeds have been integrated and/or the deployed security tools have this capability). It is worth noting that receiving TI data only at the security tool level does not always cover all types of IoCs.
If data is being received in some form, the next step is to verify that the SIEM is utilizing it. For TI-related events coming from security tools, the SIEM needs a correlation rule developed to generate alerts. Thus, checking integration in this case involves determining the capabilities of the security tools, searching for the corresponding events in the SIEM, and identifying whether there is detection logic associated with these events. If events from the security tools are absent, the source audit configuration should be assessed to see if the telemetry type in question is being forwarded to the SIEM at all. If normalization is the issue, you should assess parsing accuracy and reconfigure the normalizer.
If TI data comes from external providers, determine how it is processed within the organization. Is there a centralized system for aggregating and managing threat data (such as CyberTrace), or is the information stored in, say, CSV files?
In the former case (there is a threat data aggregation and management system) you must check if it is integrated with the SIEM. For Kaspersky SIEM and CyberTrace, this integration is handled through the SIEM interface. Following this, SIEM event flows are directed to the threat data aggregation and management system, where matches are identified and alerts are generated, and then both are sent back to the SIEM. Therefore, checking the integration involves ensuring that all collectors receiving events that may contain IoCs are forwarding those events to the threat data aggregation and management system. We also recommend checking if the SIEM has a correlation rule that generates an alert based on matching detected objects with IoCs.
In the latter case (threat information is stored in files), you must confirm that the SIEM has a collector and normalizer configured to load this data into the system as events. Also, verify that logic is configured for storing this data within the SIEM for use in correlation. This is typically done with the help of lists that contain the obtained IoCs. Finally, check if a correlation rule exists that compares the event flow against these IoC lists.
As the examples illustrate, integration with TI in standard scenarios ultimately boils down to developing a final correlation rule that triggers an alert upon detecting a match with known IoCs. Given the variety of integration methods, creating and providing a universal out-of-the-box rule is difficult. Therefore, in most cases, to ensure IoCs are connected to the SIEM, you need to determine if the company has developed that rule (the existence of the rule) and if it has been correctly configured. If no correlation rule exists in the system, we recommend creating one based on the TI integration methods implemented in your infrastructure. If a rule does exist, its functionality must be verified: if there are no alerts from it, analyze its trigger conditions against the event data visible in the SIEM and adjust it accordingly.
For a SIEM to run effectively, it must contain current data about the infrastructure it monitors and the threats it’s meant to detect. Both elements change over time: new systems and software, users, security policies, and processes are introduced into the infrastructure, while attackers develop new techniques and tools. It is safe to assume that a perfectly configured and deployed SIEM system will no longer be able to fully see the altered infrastructure or the new threats after five years of running without additional configuration. Therefore, practically all components – event collection, detection, additional integrations for contextual information, and exclusions – must be maintained and kept up to date.
Furthermore, it is important to acknowledge that it is impossible to cover 100% of all threats. Continuous research into attacks, development of detection methods, and configuration of corresponding rules are a necessity. The SOC itself also evolves. As it reaches certain maturity levels, new growth opportunities open up for the team, requiring the utilization of new capabilities.
Problem: The SIEM has not evolved since its initial deployment.
How to detect: Compare the original statement of work or other deployment documentation against the current state of the system. If there have been no changes, or only minimal ones, it is highly likely that your SIEM has areas for growth and optimization. Any infrastructure is dynamic and requires continuous adaptation.
In this article, we have outlined the primary problems we identify during SIEM effectiveness assessments, but this list is not exhaustive. We also frequently encounter:
[dev] test_Add user to admin group_final2.Generally, most issues with SIEM effectiveness stem from the natural degradation (accumulation of errors) of the processes implemented within the system. Therefore, in most cases, maintaining effectiveness involves structuring these processes, monitoring the quality of SIEM engagement at all stages (source onboarding, correlation rule development, normalization, and so on), and conducting regular reviews of all system components and resources.
A SIEM is a powerful tool for monitoring and detecting threats, capable of identifying attacks at various stages across nearly any point in an organization’s infrastructure. However, if improperly configured and operated, it can become ineffective or even useless while still consuming significant resources. Therefore, it is crucial to periodically audit the SIEM’s components, settings, detection rules, and data sources.
If a SOC is overloaded or otherwise unable to independently identify operational issues with its SIEM, we offer Kaspersky SIEM platform users a service to assess its operation. Following the assessment, we provide a list of recommendations to address the issues we identify. That being said, it is important to clarify that these are not strict, prescriptive instructions, but rather highlight areas that warrant attention and analysis to improve the product’s performance, enhance threat detection accuracy, and enable more efficient SIEM utilization.
I recently participated in a security leader roundtable hosted by Cybersecurity Tribe. During this session, I got to hear firsthand from security leaders at major organizations including BNP Paribas, the NFL, ION Group, and half a dozen other global enterprises.
Across industries and maturity levels, their priorities were remarkably consistent. When it comes to AI-powered SOC platforms, these are the seven capabilities every CISO is asking for.
If there was one theme that came up more than anything else, it was trust. Security leaders don’t want “mysterious” AI. They want transparency.
They repeatedly insisted that AI outputs must be auditable, explainable, and reproducible.
They need to show the work, for compliance auditors, for internal governance boards, and increasingly to address emerging legal and regulatory risk.
Black-box decisions won’t cut it. AI must generate evidence, not just conclusions.
Every leader I spoke with is wrestling with alert overload. Even mature SOCs are drowning in low-value notifications and pseudo-incidents.
A measurable reduction in alerts escalated to humans is now a top KPI for evaluating AI platforms. Leaders want an environment where analysts spend their time on exploitable, high-impact threats, not noise.
If AI can remove repetitive triage work, that’s not just helpful, it’s transformational.
No one wants yet another dashboard that nags them about high CVSS scores on systems nobody actually cares about.
CISOs want AI that can fuse:
The goal is prioritization that reflects real organizational risk, not arbitrary severity scores.
They want AI to tell them: “This is the one alert that actually matters today and here’s why.”
Get your editable copy of the one deck you need to pitch your board for 2026 AI SOC budget.

Most leaders are open to selective autonomous remediation, but only in narrow, well-defined, high-confidence scenarios.
For example:
But for broader or higher-impact actions, CISOs still want human review. The tone was clear:
AI should move fast where appropriate, but never at the expense of control.
Every leader emphasized that an AI platform is only as good as the data it can consume.
The must-have list included:
They don’t want a magical AI that promises answers without good data.
They want a connected system that can see across the entire environment.
CISOs aren’t implementing AI in a vacuum. Their boards and executive leadership teams are pressuring them from two very different angles:
To navigate this dynamic, CISOs need clear, defensible ROI:
AI without measurable value is no longer acceptable.
They need something they can put in front of the board and say, “Here’s the impact.”
Before enterprises allow AI to autonomously take security actions, CISOs need a fundamental question answered:
“Who is accountable when the AI acts?”
This isn’t just a theoretical concern. It’s a gating requirement for adoption.
Until there is clear guidance on liability, responsibility, and governance, many organizations will keep AI on a tight leash.
Across all of these conversations, the message was consistent:
AI in the SOC is inevitable, but it must be safe, transparent, integrated, and measurable.
CISOs aren’t looking for science fiction. They’re looking for credible, operational AI that enhances their teams, strengthens their defenses, and aligns with business realities.
Read about why the best LLMs are not enough for the AI SOC.
The post The 7 CISO requirements for AI SOC in 2026 appeared first on Intezer.
By Troy Wojewoda During a recent Breach Assessment engagement, BHIS discovered a highly stealthy and persistent intrusion technique utilized by a threat actor to maintain Command-and-Control (C2) within the client’s […]
The post The Curious Case of the Comburglar appeared first on Black Hills Information Security, Inc..

What happens when you ditch the tiered ticket queues and replace them with collaboration, agility, and real-time response? In this interview, Hayden Covington takes us behind the scenes of the BHIS Security Operations Center, which is where analysts don’t escalate tickets, they solve them.
The post Inside the BHIS SOC: A Conversation with Hayden Covington appeared first on Black Hills Information Security, Inc..
The Security Operations Center (SOC) has always been the heart of enterprise defense, but in 2026, it’s evolving faster than ever.
The rise of AI-driven SOC platforms, often referred to as Agentic AI SOCs, is redefining how enterprises detect, investigate, and respond to threats.
For years, security teams relied on a mix of SIEM, EDR, and MDR vendors to stay ahead of attacks. But these stacks often created their own problems: endless alert noise, long investigation times, and an overworked analyst team stuck in repetitive triage.
The new generation of AI SOC platforms changes that. They leverage large language models (LLMs), enabling SOCs to automatically triage and investigate every alert in minutes, not hours.
In this guide, we’ll break down the Top 15 AI SOC platforms to watch in 2026, ranked by how they balance speed, accuracy, explainability, and coverage across modern enterprise environments.
“Agentic” AI refers to systems that don’t just respond, they act. In cybersecurity, an Agentic AI SOC is capable of performing end-to-end investigations, drawing conclusions, and recommending (or executing) responses based on forensic evidence and reasoning.
These platforms are trained not only to summarize alerts but to understand their context, correlating data across endpoints, identities, networks, and cloud systems.
The best AI SOCs of 2026 are explainable, autonomous, and fast, providing the confidence enterprises need to trust machine-led decision-making.
| Platform | Best for | Key strength |
|---|---|---|
| Intezer (Forensic AI SOC) | Large Enterprises | Forensic-level, explainable investigations |
| 7AI | Enterprises exploring multi-agent automation | Multi-agent orchestration |
| AiStrike | Mid-market SOCs | Affordable automated triage |
| SentinelOne (Purple AI) | Enterprises using SentinelOne EDR | Integrated SOC automation |
| CrowdStrike (Charlotte AI) | Falcon ecosystem users | Generative AI for summaries |
| BlinkOps | Security automation teams | Playbook-based automation |
| Bricklayer AI | Startups | Lightweight triage and reporting |
| Conifers.ai | Cloud-native companies | Cloud-first visibility |
| Vectra AI | Mature SOCs | Network threat detection |
| Dropzone AI | SOC automation innovators | Human-in-the-loop design |
| Exaforce | Minimizing SIEM Cost | Alert routing and prioritization |
| Legion Security | SOCs with expert analysts | Workflow management |
| Prophet.ai | Predictive threat modeling | Proactive threat detection |
| Qevlar AI | LLM-driven SOCs | AI triage experiments |
| Radiant Security | Mid-market enterprises | Response recommendations |
Best for: Large enterprises that prioritize speed, accuracy, and complete alert coverage.
Intezer AI SOC is built for enterprise and MSSPs, trusted by global brands including NVIDIA, Salesforce, MGM Resorts, Equifax, and Ferguson.
Intezer investigates 100% of alerts in under two minutes with 98% accuracy.
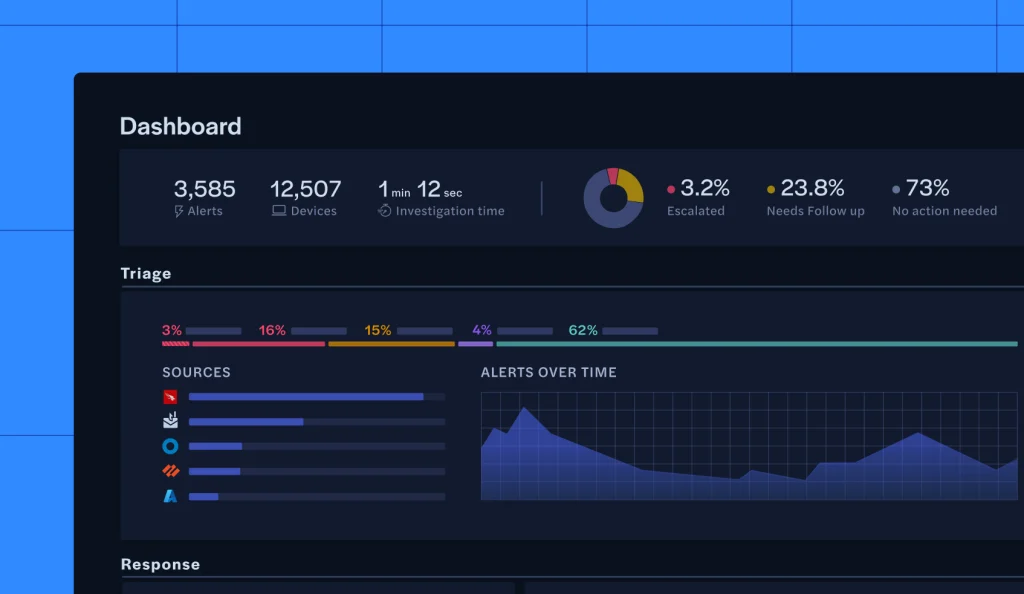
Unlike other platforms that rely solely on LLM-generated heuristics, Intezer fuses human-like reasoning with multiple AI models and deterministic forensic methods, including code analysis, sandboxing, reverse engineering, and memory forensics.
The result is evidence-backed, explainable verdicts that eliminate the guesswork for SOC analysts.
For enterprises managing millions of alerts across SIEM, EDR, cloud, and identity systems, Intezer delivers full alert coverage and eliminates the low-severity blind spots that MDRs often ignore.
With endpoint-based pricing, Intezer removes the “alert tax” of data-ingest models and helps SOC leaders prove ROI to their boards, without expanding headcount.
Why enterprises choose Intezer
Experience Intezer in action with a custom demo.
7AI is one of the most experimental platforms in the 2026 AI SOC space. It focuses on multi-agent orchestration, where separate AI agents collaborate to triage, enrich, and investigate alerts across different domains.
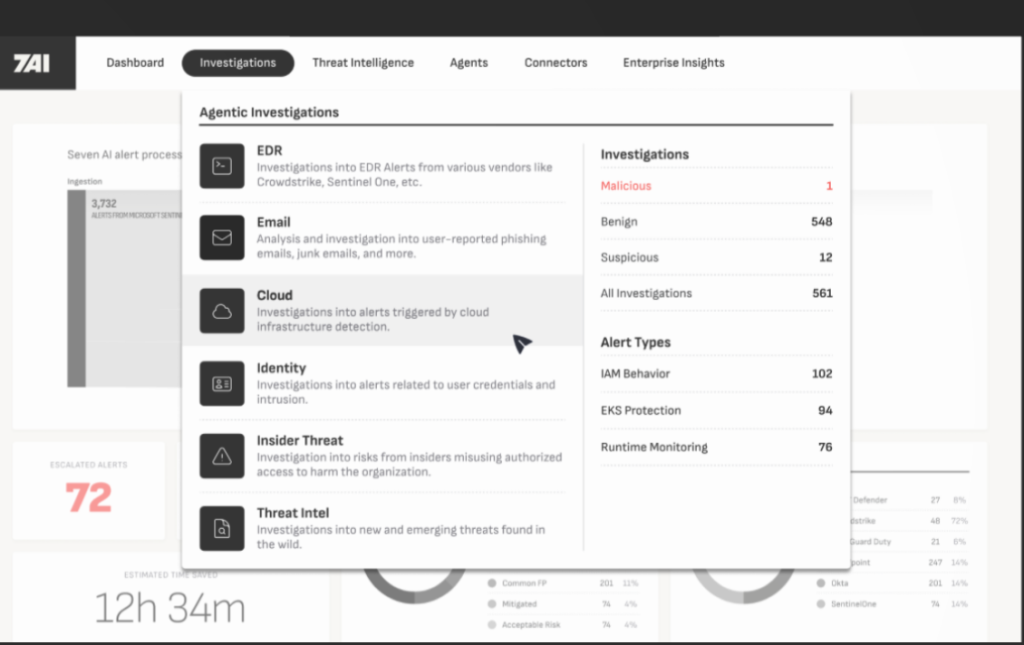
While its architecture is impressive, 7AI is best suited for innovation-driven security teams that have strong engineering capacity and want to customize workflows. It performs well in large-scale EDR and cloud environments but requires fine-tuning for reliability.
Best for: Enterprises exploring multi-agent SOC architectures.
AiStrike targets the mid-market segment with a focus on cost-effective AI triage. It offers a simple, clean dashboard that connects with EDR and SIEM tools to automatically prioritize alerts. While its forensic depth is limited compared to enterprise-grade solutions, AiStrike delivers solid speed and automation for smaller SOCs.

Best for: Mid-market SOCs that want affordable, plug-and-play AI investigations.
SentinelOne’s Purple AI brings native AI investigation and response into the SentinelOne platform. It’s tightly integrated with SentinelOne’s EDR and XDR stack, which makes it a strong option for organizations already using the SentinelOne’s stack.
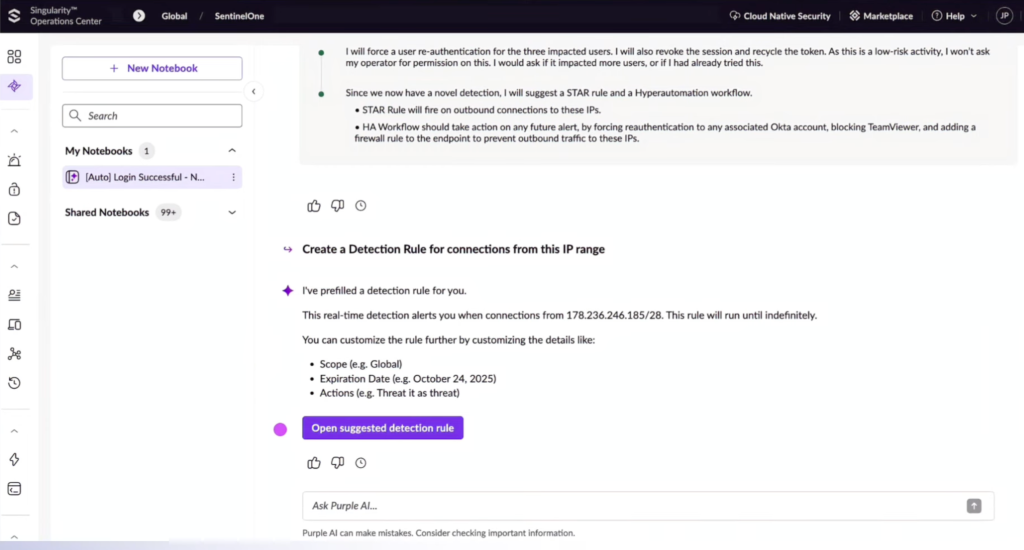
While Purple AI provides quick, summarized threat analysis and remediation recommendations, it focuses heavily on endpoints rather than full enterprise coverage.
Best for: Enterprises deeply invested in SentinelOne’s ecosystem that want integrated AI triage.
CrowdStrike’s Charlotte AI is the generative assistant within the Falcon platform, built to help analysts ask natural-language questions and interpret alerts faster.

While not a fully autonomous SOC, Charlotte AI improves analyst experience and productivity by summarizing incidents and surfacing relevant insights. It’s ideal for teams that want to augment analysts rather than automate full investigations.
Best for: Enterprises using the CrowdStrike Falcon suite that want faster analyst assistance.
BlinkOps focuses on workflow automation, not investigations per se. It enables security teams to build playbooks and automation pipelines that connect multiple tools (SIEM, EDR, IAM, etc.).

While it doesn’t deliver forensic-level verdicts, BlinkOps is popular among DevSecOps teams that want custom automation flexibility.
Best for: Security engineers looking to automate existing SOC workflows.
Bricklayer AI provides lightweight alert triage and reporting capabilities. It’s built for smaller organizations that want to reduce alert fatigue without complex integrations. Its simplicity and affordability make it a solid entry point for teams without mature SOC processes.
Best for: Startups building early SOC capabilities on a budget.
Conifers.ai specializes in cloud-first security visibility across AWS, Azure, and Google Cloud. Its AI models excel at correlating identity, network, and workload activity to flag potential breaches.

It’s not a full SOC replacement, but it significantly enhances cloud investigation and response.
Best for: Cloud-first organizations seeking AI-enhanced detection and context.
Vectra AI has long been a leader in AI-driven network detection and response (NDR). Its platform now extends into AI SOC territory, combining real-time detection with contextual identity analysis.
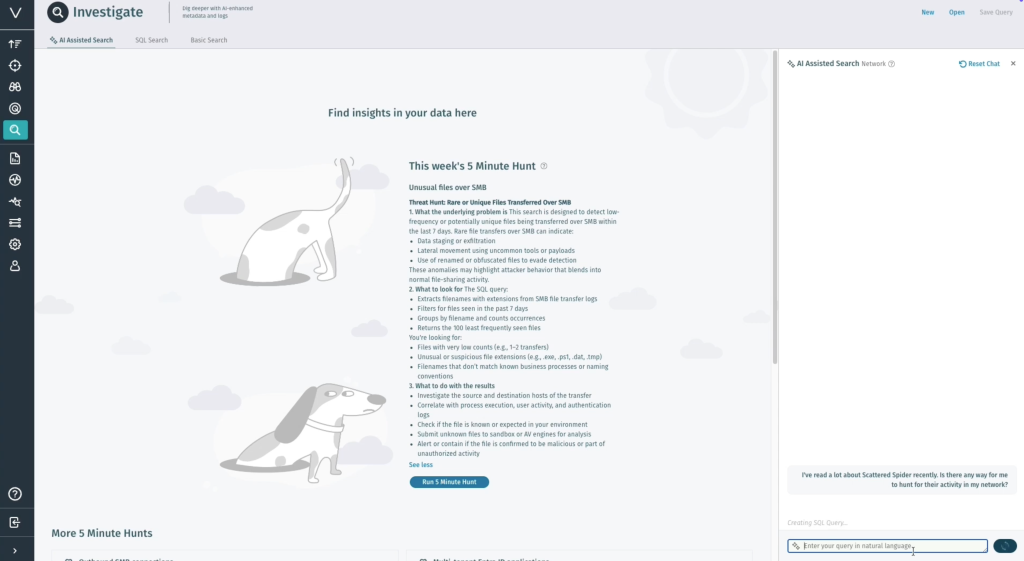
Vectra is strong in hybrid environments but remains specialized in network telemetry rather than full-stack coverage.
Best for: Enterprises prioritizing network and identity visibility.
Dropzone AI represents the new wave of human-in-the-loop SOC automation. It allows analysts to supervise and approve actions initiated by AI, blending human expertise with autonomous investigation.
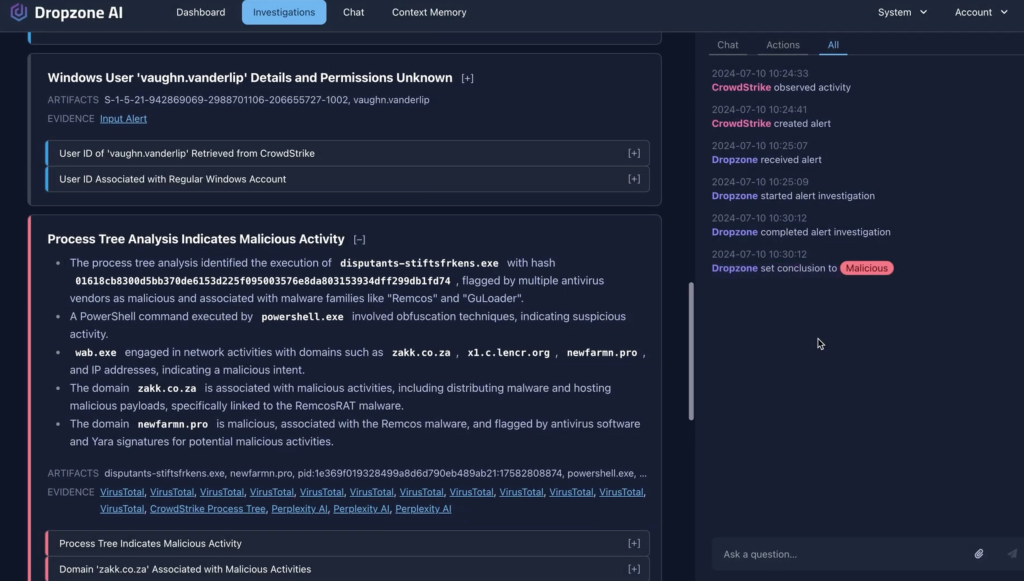
While not as proven in large enterprises as Intezer, Dropzone’s agentic architecture makes it an intriguing option for forward-thinking SOCs.
Best for: SOCs experimenting with supervised AI autonomy.
Read about what CISOs are looking for in an AI SOC platform
Exaforce uses a multi-model AI engine to reduce alert overload, accelerate investigations, and expand detection coverage without relying on a traditional SIEM. Its AI stack, combining data-ingestion models, behavioral machine learning, and large language models, analyzes real-time telemetry while cutting SIEM-related storage and licensing costs.

The platform adapts quickly through feedback loops and natural-language business context, continuously refining accuracy and reducing false positives. With investigative graph visualizations and flexible deployment options, Exaforce helps streamline complex investigations.
Best for: Companies struggling with excessive SIEM spend.
Legion automates SOC investigations by capturing and operationalizing real analyst decision-making. Its browser-based agent records every step of an analyst’s workflow such as data reviewed, actions taken, judgments made and then creating reusable investigative logic.
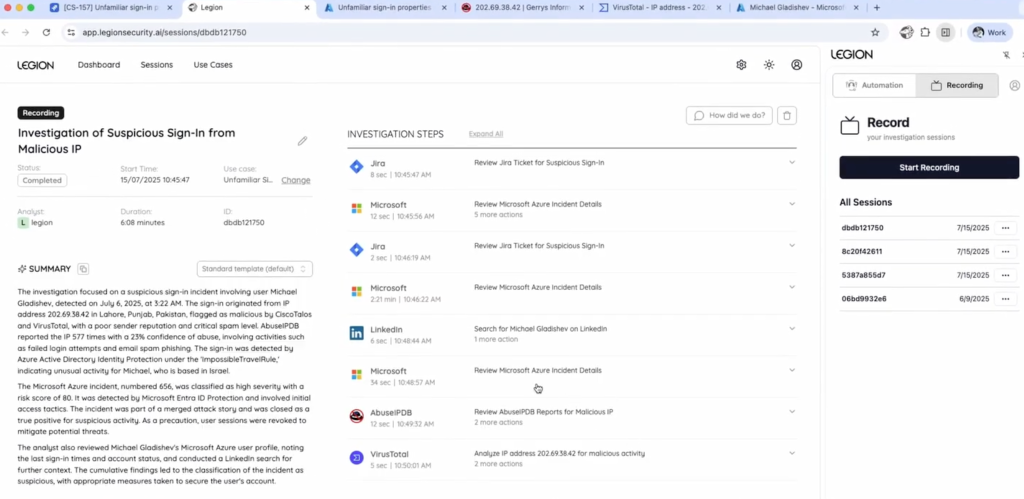
These recordings evolve into living agents that can be replayed, tested, refined, and re-executed across new alerts. Legion offers flexible deployment options including cloud, hybrid, or customer-hosted to support diverse security and compliance requirements.
Best for: Organizations with expert human analysts, looking to create custom AI agents that can mirror their in-house best practices and knowledge.
Prophet focuses on automated alert resolution using agentic reasoning that mirrors how experienced analysts assess user behavior, asset context, and threat indicators. It enriches alerts with data from endpoints, cloud systems, identity platforms, and threat intelligence to deliver high-confidence dispositions without relying on static rules. The platform supports flexible automation, from fully automated closure of benign alerts to analyst-in-the-loop escalation, and includes a copilot-style natural language interface for deeper investigation and threat hunting.
Best for: Enterprises investing in predictive threat modeling and trend forecasting.
Qevlar is an AI-powered investigation co-pilot that enhances analyst workflows by replicating the reasoning and research steps of human investigators. It ingests alerts from various tools and produces structured, evidence-backed reports with clear verdicts, confidence levels, and referenced data sources. Instead of suppressing or prioritizing alerts, Qevlar enriches and interprets them while preserving full analyst oversight. It also offers an automated documentation engine and support for on-prem deployment.
Best for: SOCs experimenting with AI-based triage prototypes.
Radiant Security positions itself as an AI SOC for the mid-market and differentiates itself with claims of adaptive AI that can learn how to handle never-seen-before alerts as well as a built-in, affordable logging solution leveraging customers’ own archive storage.
Best for: Mid-market companies looking to eliminate expensive SIEM costs.
The next evolution of SOC automation goes beyond alert management. In 2026 and beyond, Agentic AI SOCs will not only investigate but also take verified actions, quarantining hosts, isolating sessions, and orchestrating containment based on evidence and policy.
This shift demands trust, explainability, and speed. Enterprises can no longer afford “black-box” AI that delivers vague suggestions. They need platforms capable of forensic reasoning, auditability, and full coverage, exactly what Intezer Forensic AI SOC delivers.
SOC leaders who adopt these systems early will gain measurable efficiency, lower operational risk, and stronger security posture, without expanding headcount.
AI SOC platforms are transforming how enterprises defend against modern threats.
While each platform on this list has unique strengths, Intezer stands out as the clear enterprise choice for those who demand accuracy, speed, and complete visibility.
See how Fortune 500 SOCs cut through the noise, reduce risk, and reclaim their time with Intezer.
Book a demo to experience Intezer in action.
The post Top 15 AI SOC Tools for 2026: SOC Automation Compared appeared first on Intezer.
Modern SOC teams face some real challenges. They are drowning in alert volume, short on experienced analysts, and facing a new generation of AI-driven attacks that operate faster than humans can respond. This combination is eroding SOC effectiveness, slowing response times, and creating blind spots where real threats hide in low-severity alerts that teams no longer have the time or capacity to investigate.
To meet this moment, Intezer is proud to unveil Intezer Forensic AI SOC, the only AI SOC platform battle-tested inside some of the world’s most targeted and security-mature organizations. Already trusted by more than 150 enterprises, including 15 of the Fortune 500, the platform brings forensic-grade accuracy, full alert coverage, and sub-minute triage to modern security operations.
As attack surfaces grow, many organizations turn to MDR providers for 24/7 alert triage. But MDRs often operate as black boxes with inconsistent quality, high escalation rates, and limited visibility, leaving low-severity alerts unaddressed and creating gaps adversaries can exploit.
Most “AI SOC” tools depend entirely on AI agents for alert triage and investigation. This leads to surface-level results, slower performance, and higher compute usage, limiting their ability to process large alert volumes, especially low-severity signals where threats frequently hide.
The way forward requires an approach that removes SOC bottlenecks while delivering stronger, more reliable security outcomes.
The recent Anthropic AI espionage report marks a turning point. Threat actors are now weaponizing AI agents to automate full intrusion chains at machine speed.
These attacks often leave behind subtle, low-severity breadcrumbs that traditional SOCs and MDRs overlook. Without full alert coverage and forensic-grade triage, organizations cannot detect or contain AI-driven campaigns before they escalate.
This is precisely the gap Intezer’s Forensic AI SOC was built to close.
Watch session on how security leaders prepare for the new era of AI-orchestrated cyber attacks.
Intezer Forensic AI SOC flips the AI SOC model on its head. Instead of solely relying on AI Agents and LLMs, our platform combines AI agents and automated orchestration of deterministic forensic tools, to mimic the triage and investigation methods used by elite responders and perform deep, accurate investigations at speed and scale.
Every alert is examined through a forensic lens using Intezer’s battle-tested capabilities, including endpoint forensics, reverse engineering, network artifact analysis, sandboxing, and other proprietary methods. These are paired with the adaptive research and reasoning of multiple LLMs to ensure both depth and flexibility in every investigation.
Intezer Forensic AI delivers:
Enterprises get both the intelligence of AI and the rigor of forensics, without sacrificing speed, cost, or accuracy.
Intezer supports over 150 enterprises, including 15 of the Fortune 500, across verticals such as finance, tech, pharma, critical infrastructure, hospitality and more. These organizations operate some of the most complex and heavily targeted environments in the world and rely on Intezer to keep their businesses secure.
“Intezer’s AI-driven triage has been transformative for our SOC. It integrates seamlessly with our existing systems and delivers analyst-level investigations at scale, giving our team the confidence that every alert is handled with forensic accuracy.”
Branden Newman, CTO, MGM Resorts International
Enterprise SOCs must respond not only to rising alert volume, but also to increasing business pressure for speed, consistency, and measurable risk reduction. Companies using Intezer Forensic AI SOC enjoy:
Intezer was founded and shaped by world-class SecOps leaders, security researchers and incident responders who have spent their careers defending some of the most targeted organizations and building foundational cybersecurity technologies.
Our leadership team includes pioneers who helped create and scale major cybersecurity companies. This firsthand experience responding to advanced threats, operating high-pressure SOC environments, and building products used by thousands of security teams worldwide directly informs how Intezer designs its technology.
We understand what analysts need, speed, accuracy, transparency, and trustworthy automation, because we’ve lived those challenges ourselves.
Intezer Forensic AI SOC reflects that operational DNA with a platform built not by generic AI engineers, but by practitioners who have spent years reverse engineering malware, hunting nation-state adversaries, leading global IR engagements, and building tools that analysts rely on every day.
The SOC is entering a new era. Machine-scaled attacks demand an approach grounded in both forensic rigor and adaptive AI enabling consistent, accurate investigations to defend the enterprise.
The post Introducing Intezer Forensic AI SOC appeared first on Intezer.
tl;dr Greater productivity ≠ greater security outcomes. Kinda like why being able to accelerate from 0-60 MPH doesn’t help when the ice is cracking under your wheels.
And now, the full version.
AI SOC shouldn’t just “augment workflows”, that’s a productivity-locked perspective. The goal and the delivery capability that exists right now is to deliver full-scale enterprise triage of 100% of alerts with forensicly-accurate verdicts. That looks like streamlined triage, explainable verdicts, measurable accuracy, and operational resilience. There’s already an AI SOC platform that has operationalized what Gartner calls “emerging”.
While recent Gartner reports on “AI SOC Agents” and “SecOps Workflow Augmentation” succeed in elevating the conversation, they also reveal how incomplete that conversation still is. Both documents frame AI in the SOC as a promising but premature experiment, a toolset meant to make analysts more productive, not organizations more secure. That framing misses the point. AI isn’t about automation for automation’s sake; it’s about turning expert knowledge, data, context, and expertise into repeatable, scalable decision-making that covers every alert with confidence and context.
Gartner’s reports argue that AI SOC agents should be treated as “workflow augmentation tools” to reduce analyst fatigue and improve response efficiency. They recommend cautious adoption, structured pilots, and human-in-the-loop validation. Pragmatic? When LLMs are relied upon solely, sure. But the underlying assumption that enterprise-proven AI is not yet mature enough to deliver reliable outcomes is outdated.
In practice, this mindset anchors the market in productivity metrics, not security performance. It evaluates how efficiently teams work, not how effectively they defend. The focus stays on “mean time to detect” and “mean time to respond,” rather than the more critical questions:
That’s where the emerging class of true AI SOC platforms breaks away from the Gartner lens.
The distinction matters. Augmentation is an operational improvement; outcomes are a security transformation. Most vendors today build tools that accelerate investigation but still depend on human oversight for every meaningful decision. Those are SOAR 2.0 platforms: automation-centric, workflow-obsessed, and still fundamentally enrichment, not triage.
A true AI SOC, by contrast, triages every alert across the stack autonomously, determines a verdict with auditable reasoning, and escalates only when necessary, typically less than four percent of the time. This isn’t a co-pilot; it’s a teammate that already performs at the level of a seasoned analyst and identifies the needles without the haystack. This is incredible for the SOC analysts that are focused on looking at real alerts.
Security outcome execution is the critical requirement any true AI SOC should provide:
This isn’t augmentation; it’s execution.
Read more about properly framing the AI SOC conversation.
Gartner describes AI SOC agents as an “emerging technology” that promises to evolve beyond playbook-driven automation. The irony is that enterprise SOCs are already running on these systems today. Fortune 10 environments and thousands of organizations worldwide are triaging every single alert, not just the critical and high-severity ones, through AI that emulates human reasoning at scale.
These systems don’t “pilot” AI; they operationalize it. They deliver 24/7 SOC capability, instant triage, and consistent decision-making grounded in explainable logic, not black-box inference. They prove that an AI SOC is no longer a future-state concept. It’s production-grade infrastructure that’s rewriting what operational maturity means, and has been for years now.
The difference between Gartner’s caution and what’s happening in practice is simple: proof.
The reports fixate on efficiency → MTTD, MTTR, analyst satisfaction, but those metrics only tell half the story especially for antiquated SOCs. The next generation of AI SOCs defines success through security outcome metrics, including:
When you measure what truly matters, accuracy, coverage, trust, the difference between AI that “helps” and AI that defends becomes obvious.
The reports conflate two very different things. An “AI SOC agent” is a single use case, an assistant. An “AI SOC platform” is a full operating model: triage, investigation, and response fused into a continuous feedback loop back to detection engineering. One optimizes efficiency; the other drives security transformation.
That’s the real inflection point the industry is standing at. SOCs that treat AI as a productivity booster will get marginal gains, which is a great thing for the industry. SOCs that rebuild around AI as a core operating principle will experience exponential gains with real risk reduction.
In other words: this isn’t about speeding up analysts, it’s about scaling their expertise across the entire alert surface.
The challenge now isn’t technology, it’s perception. The AI SOC has already proven it can outperform legacy models built on manual triage and brittle playbooks. It has shown that full alert coverage, explainable verdicts, and continuous learning can coexist with human oversight and compliance.
The industry doesn’t need another year of pilots to “validate the promise.” It needs a new standard of performance.
The next evolution of the SOC will be measured not by how well it augments workflows, but by how confidently it can:
That’s the AI SOC outcome model, here today.
Gartner’s perspective is valuable for shaping the taxonomy of an emerging market. But the reality on the ground has already overtaken the research. The world doesn’t need another whitepaper on “potential.” It needs proof of performance, and it exists.
The future SOC isn’t augmented.
It’s autonomous, accurate, and accountable for strategic security outcomes that CISOs and leaders require, either now or in the next few months with the executive leadership push to operationalize AI.
The world’s largest enterprises today already benefit from the real market-defining traits of a forensic AI SOC.
To learn more about Intezer’s Forensic AI SOC platform, schedule a demo today!
The post Why the “AI SOC Agent” narrative misses the point: The future is about security outcomes, not workflow augmentation appeared first on Intezer.
For a while now, the security community has been aware that threat actors are using AI. We’ve seen evidence of it for everything from generating phishing content to optimizing malware. The recent report from Anthropic on an “AI-orchestrated cyber espionage campaign”, however, marks a significant milestone.
This is the first time we have a public, detailed report of a campaign where AI was used at this scale and with this level of sophistication, moving the threat from a collection of AI-assisted tasks to a largely autonomous, orchestrated operation.
This report is a significant new benchmark for our industry. It’s not a reason to panic – it’s a reason to prepare. It provides the first detailed case study of a state-sponsored attack with three critical distinctions:
Together, these distinctions show why this case matters. A high-level, autonomous, and successful AI-driven attack is no longer a future theory. It is a documented, current-day reality.
For those who haven’t read the full report (or the summary blog post), here are the key facts.
The attack (designated GTG-1002) was a “highly sophisticated cyber espionage operation” detected in mid-September 2025.

Source: https://www.anthropic.com/news/disrupting-AI-espionage
To have a credible discussion, we must also look at what wasn’t new. This attack wasn’t about secret, magical weapons.
The report is clear that the attack’s sophistication came from orchestration, not novelty.
This matters because defenders often look for new exploit types or malware indicators. But the shift here is operational, not technical. The attackers didn’t invent a new weapon, they built a far more effective way to use the ones we already know.
So, if the tools aren’t new, what is? The execution model. And we must assume this new model is here to stay.
This new attack method is a natural evolution of technology. We should not expect it to be “stopped” at the source for two main reasons:
The attack surface is not necessarily growing, but the attacker’s execution engine is accelerating.
While the techniques were familiar, their execution creates a different kind of detection challenge. An AI-driven attack doesn’t generate one “smoking gun” alert, like a unique malware hash or a known-bad IP. Instead, it generates a storm of low-fidelity signals. The key is to hunt for the patterns within this noise:
The detection patterns listed above create the central challenge of defending against AI-orchestrated attacks. The problem isn’t just alert volume, it’s that these attacks generate a massive volume of low-fidelity alerts.
This new execution model creates critical blind spots:
When the attack is autonomous, the defense must also have autonomous capabilities.
We cannot hire our way out of this speed and scale problem. The security operations model must shift. The goal of autonomous triage is not just to add context, but to handle the entire investigation process for every single alert, especially the thousands of low-severity signals that AI-driven attacks create.
An autonomous system can automatically investigate these signals at machine speed, determine which ones are irrelevant noise, and suppress them.
This is the true value: the system escalates only the high-confidence, confirmed incidents that actually matter. This frees your human analysts from chasing noise and allows them to focus on real, complex threats.
This is exactly the type of challenge autonomous triage systems like the one we’ve built at Intezer were designed to solve. As Anthropic’s own report concludes, “Security teams should experiment with applying AI for defense in areas like SOC automation, threat detection… and incident response“.
To defend against this threat, we must be able to test our defenses against it. All offensive security activities, internal red teams, external penetration tests, and attack simulations, must evolve.
It is no longer enough for offensive security teams to manually simulate attacks. To truly test your defenses, your red teams or external pentesters must adopt agentic AI frameworks themselves.
The new mandate is to simulate the speed, scale, and orchestration of an AI-driven attack, similar to the one detailed in the Anthropic report. Only then can you validate whether your defensive systems and automated processes can withstand this new class of automated onslaught. Naturally, all such simulations must be done safely and ethically to prevent any real-world risk.
The Anthropic report doesn’t introduce a new magic exploit. It introduces a new execution model that we now need to design our defenses around.
Let’s summarize the key, practical takeaways:
This report is a clear signal. The threat model has officially changed. Your security architecture, processes, and playbooks must change with it. The same applies if you rely on an MSSP, verify they’re evolving their detection and triage capabilities for this new model. This shift isn’t hype, it’s a practical change in execution speed. With the right adjustments and automation, defenders can meet this challenge.
To learn more, you can read the Anthropic blog post here and the full technical report here.
The post What the Anthropic report on AI espionage means for security leaders appeared first on Intezer.
Gartner’s recent Innovation Insight: AI SOC Agents report is an encouraging signal that the concept of an “AI-powered SOC” has reached mainstream awareness. The report recognizes the potential of AI technologies to transform how security operations centers function, especially in augmenting analysts through automation and intelligent workflows.
Yet, while Gartner’s analysis succeeds in capturing the momentum of this space, it falls short in clarifying how and where AI actually fits within the security operations stack. By treating “AI SOC” as a monolithic, undifferentiated category, the report overlooks the crucial distinctions between detection, triage and response, each of which requires a very different kind of AI capability and delivers very different value.
Gartner’s report provides a valuable overview of how AI SOC can assist with detection, alert investigation, and even response recommendation. We wholeheartedly agree with Gartner’s advice that CISOs should evaluate which security activities are “volumetric, troublesome, or low-performing, and which would benefit the most from augmentation with the application of AI”. However, presenting all of the AI SOC functions (and vendors) as part of a single undifferentiated security ecosystem, can be confusing.
This broad framing misses the fact that an AI model designed to improve SIEM detection logic operates on entirely different data, architecture, and feedback loops than one built to support analyst decision-making or response automation. The result is a flattening of a nuanced market into one monolithic category, useful for taxonomy, but not for decision-making.
For CISOs, this lack of segmentation makes it hard to answer the key strategic question: Where should we apply AI first to get tangible operational value?
By contrast, our view is that organizations should start by identifying which part of their operations needs augmentation most, then evaluate AI solutions purpose-built for that domain.
To understand where AI truly fits in and how it can deliver measurable outcomes, it helps to zoom out and look at the broader security operations stack. As we described in a previous blog post, “Making sense of the AI SOC market”, we see three main layers where AI can add value:
Detection (SIEM, XDR)
The first layer converts raw telemetry into actionable alerts. Here, AI can strengthen correlation logic, improve detection models, and reduce false positives. This is largely about data pattern recognition and automation of repetitive analysis.
Triage and Investigation (SOC / MDR)
The middle layer is where human analysts determine which alerts are real incidents worth escalating. This is where AI can truly emulate analyst reasoning, gathering context, cross-referencing intelligence, and presenting likely root causes. Done well, AI here acts as a co-analyst, not a replacement.
Response and Case Management (SOAR)
The final layer coordinates remediation and manages incident workflows. AI can accelerate playbook creation, automate routine case handling, and improve overall response time through dynamic decision logic.
Each layer offers opportunities for AI—but they are fundamentally different problems to solve. When vendors use the term “AI SOC” without specifying which layer they’re addressing, it creates confusion and unrealistic expectations.
To move the conversation forward, we recommend a more structured approach to evaluating AI SOC solutions.
Step 1: Identify your target layer
Ask: Which layer of our operations needs the most improvement. Is it detection (SIEM/XDR/Cloud), triage (SOC/MDR), or response (SOAR)?
This helps narrow the field to the right class of solutions rather than chasing the broad “AI SOC” label.
Step 2: Define measurable outcomes
Especially for alert triage and investigation (which is usually handled by an internal SOC or external MDR), establish metrics to compare performance, such as:
These metrics allow organizations to compare vendors on tangible outcomes, not vague AI promises.
Step 3: Evaluate transparency and integration
An effective AI SOC solution should clearly explain its reasoning, integrate easily with your existing tools, and allow human oversight. The goal is augmentation, not opacity.
Read more about why the “AI SOC agent” narrative misses the point.
Gartner deserves credit for bringing visibility to an emerging market, but their analysis underscores how early and fluid this space still is. The future of the AI SOC isn’t one product category. It’s a set of AI capabilities applied intelligently across the detection–triage–response continuum.
Organizations that treat AI as a modular capability rather than a monolithic product will see the most success. The key is knowing your operational priorities and matching them to the layer where AI can have the greatest impact.
AI is not a magic “SOC-in-a-box.” It’s a set of technologies that, when properly targeted, can transform specific parts of security operations. Gartner’s latest report captures the enthusiasm, but not yet the structure, of this market.
At Intezer, we believe the path forward starts with clarity. Understanding the distinct layers of the SOC, the role AI plays in each, and the outcomes that matter most. Only then can organizations cut through the noise and choose the right AI SOC partner for their needs.
Explore how Intezer delivers complete peace of mind for your security operations!
The post Properly framing the AI SOC conversation appeared first on Intezer.
There’s been an explosion of buzz around the AI SOC market. More than 40 vendors are now claiming to do something in this space, but as with many emerging technology categories, the result is a lot of excitement and a lot of confusion.
In this video and in the article below it, I want to provide some clarity. What exactly is “AI SOC”? Where did this category come from? And how can security teams cut through the noise to find real value?
The rise of the AI SOC stems from two converging forces. A very old problem and a very new technology.
The old problem is the persistent talent shortage in cybersecurity combined with the overwhelming volume of security alerts. Security teams have been drowning in these alerts for years, struggling to keep up with investigation and response.
The new technology is AI, especially large language models (LLMs) and adjacent innovations, which open up an opportunity to finally address that shortage by automating some of the human decision-making process.
To understand where AI fits in and how it can help, let’s zoom out and look at the broader security operations stack.
There are three main layers:
Detection (SIEM, XDR) is the first level which handles converting raw logs and other telemetry data into actionable alerts.
Triage and investigation (SOC) is the middle layer where human analysts determine which alerts are real incidents worth escalating.
Response and case management (SOAR) is the final layer that manages incident remediation with case assignment, and workflow automation.
Each layer presents opportunities for AI. For example, in SIEM/XDR, AI can improve detection logic and reduce false positives. For SOC, AI can simulate the investigative reasoning of human analysts. And when applied to SOAR, AI can accelerate workflow creation and automate routine case handling.
In each of these areas, vendors are loosely using the term AI SOC to describe what they are doing. And that is why it’s important to know what problem you are trying to solve and which ‘AI SOC” solution is appropriate for you.
Read about how AI is redefining detection engineering.
All that said, when people refer to AI SOC, they’re usually talking about that middle layer. The part focused on automated alert triage, investigation, and escalation.
That’s where Intezer focuses: providing 24/7 managed alert triage, investigation, and response powered by a decade of deep forensic analysis tooling combined with flexible and adaptable LLMs.
Our system automatically investigates alerts, surfaces only what truly requires attention, and escalates only up to 4% of alerts to human analysts.
This is where the market’s energy, and customer need, are currently concentrated. Teams want to scale their response capabilities without adding headcount, and AI SOCs make that possible.
With so many vendors entering the field, it’s important to evaluate them based on clear, measurable criteria. Some of the key metrics that I’m hearing from our customers and prospect that they consider, include:
For more on this, see our guide to evaluate AI SOC tools (with questions to ask vendors).
AI SOC is one of the most exciting and fast-evolving categories in cybersecurity. It’s also one of the messiest, but that’s often a sign of real innovation happening.
For years, the industry has been searching for a way to truly solve the alert overload and talent shortage problem. With the arrival of AI-driven investigation technology, we’re finally seeing that vision come to life.
A recent SACR market analysis report examined these metrics across leading AI SOC vendors which can be very helpful for evaluating which solution is right for you. And I definitely recommend reading about Intezer in the report 🙂.
At Intezer, we’re proud to help security teams reduce noise, focus on real threats, and scale their operations intelligently.
If you’re exploring this space, we’d love to be your partner in building a smarter SOC.
The post Making sense of the AI SOC market appeared first on Intezer.
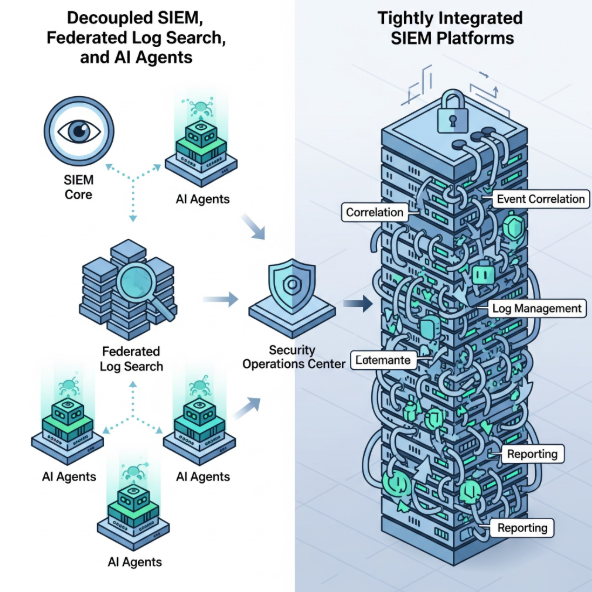
In the world of security operations, there is a growing fascination with the concept of a “decoupled SIEM,” where detection, reporting, workflows, data storage, parsing (sometimes) and collection are separated into distinct components, some sold by different vendors.
Closely related to this is the idea of federated log search, which allows data to be queried on demand from various locations without first centralizing it in a single system.
When you combine these two trends with the emergence of AI agents and the “AI SOC,” a compelling vision appears — one where many of security operations’ biggest troubles are solved in an elegant and highly automated fashion. Magic!
(Is my math mathing? Cheap + good + fast + AI powered … pick any …ehh… I digress!)
However, a look at the market reveals a conflicting — dare I saw opposite — trend. Many organizations are actively choosing the very opposite approach: tightly integrated platforms where search, dashboards, detection, data collection, and AI capabilities are bundled together — and additional things are added on top (such as EDR).
Let’s call this “EDR-ized SIEM” or “SIEM with XDR-inspired elements” (for those who think they can define XDR) or “supercoupled SIEM” (but this last one is a bit of a mouthful..)
While some suggest this is a split between large enterprises choosing disaggregated stacks and smaller companies opting for closer integration, this doesn’t fully capture the success rates of these different models (one is successful and another is, well, also successful but at a very small number of extra-large, engineering-heavy organizations)
If one were to take a contrarian view (as I will in this post!), it might be that the decoupled and federated approach, with or without AI agents, is destined to be a secondary, auxiliary path in the evolution of SIEM.
Log Centralization: The End Is Nigh?
This isn’t a nostalgic vote for outdated, 1990s-era ideas (“gimme a 1U SIEM appliance with MySQL embedded!”), but rather a realistic assessment based on past lessons, such as the niche fascination with security data science.
Many years ago (2012), while at Gartner, I wrote a notorious “Big Analytics for Security: A Harbinger or An Outlier?” (archive, repost), and it is now very clear that late 2000s-early 2010s security data science “successes” remained a tiny, micro minority examples. A trend can be emergent, growing tenfold from a tiny base of 0.01% of companies, yet still only reach 0.1% of the market — making it an outlier, not a harbinger of the mainstream future.
Ultimately, the evidence suggests that a decoupled, federated architecture will not form the basis of the typical SIEM of 2027. Instead, the centralized platform model, enhanced and supercharged by AI, will reign supreme (and, yes, it will also include some auxiliary decentralized elements as needed, think of it as “90% centralized / 10% federated SIEM” — a better model for the future).
My conclusion:
Put another way:
The Romantic Ideal: The theory is that scalable data platforms and specialized threat analysis are dramatically different, so they should be handled by specialists, and modern APIs should make connecting them “easy.” Magic!
The Real Reality: A natively designed, single-vendor, integrated SIEM is inherently simpler and easier to manage and support than a multi-component stack you have to assemble “at home.” It is also faster! AI integrated inside it just works better. With decoupling, also lose the benefit of having a “single face to scream at” when things break. Reality!
Here is my “decoupled SIEM reading list” (all fun reads, obviously not all I agree with):
Please argue on socials (X or LinkedIn) or in comments!
Related posts:
Decoupled SIEM: Where I Think We Are Now? was originally published in Anton on Security on Medium, where people are continuing the conversation by highlighting and responding to this story.
I will be really, really honest with you — I have been totally “writer-blocked” and so I decided to release it anyway today … given the date.
So abit of history first. So, my “SOC visibility triad” was released on August 4, 2015 as a Gartner blog (it then appeared in quite a few papers, and kinda became a thing). It stated that to have good SOC visibility you need to monitor logs (L), endpoint (E) sources and network (N) sources. So, L+E+N was the original triad of 2015. Note that this covers monitoring mechanisms, not domains of security (more on this later; this matters!)
5 years later, in 2020, I revisited the triad, and after some agonizing thinking (shown at the above link), I kept it a triad. Not a quad, not a pentagram, not a freakin’ hex.
So, here in 2025, I am going to agonize much more .. and then make a call (hint: blog title has a spoiler!)
How do we change my triad?
First, should we …
Let’s look at whether the three original pillars should still be here in 2025. We are, of course, talking about endpoint visibility, network visibility and logs.

My 2020 analysis concluded that the triad is still very relevant, but potential for a fourth pillar is emerging. Before we commit to this possibly being a SOC visibility quad — that is, dangerously close to a quadrant — let’s check if any of the original pillars need to be removed.
Many organizations have evolved quite a bit since 2015 (duh!). At the same time, there are many organizations where IT processes seemingly have not evolved all that much since the 1990s (oops!).
First, I would venture a guess that, given that EDR business is booming, the endpoint visibility is still key to most security operations teams. A recent debate of Sysmon versus EDR is a reflection of that. Admittedly, EDR-centric SOCs peaked perhaps in 2021, and XDR fortunately died since that time, but endpoints still matter.
Similarly, while the importance of sniffing the traffic has been slowly decreasing due to encryption and bandwidth growth, cloud native environments and more distributed work, network monitoring (now officially called NDR) is still quite relevant at many companies. You may say that “tcpdump was created in 1988” and that “1980s are so over”, but people still sniff. Packets, that is.
The third pillar of the original triad — logs — needs no defense. Log analysis is very much a booming business and the arrival of modern IT infrastructure and practices, cloud DevOps and others have only bolstered the importance of logs (and of course their volume). A small nit appears here: are eBPF traces logs? Let’s defer this question, we don’t need this answer to reassert the dominance of logs for detection and response.
At this point, I consider the original three legs of a triad to be well defended. They are still relevant, even though it is very clear that for true cloud native environments, the role of E (endpoint) and N (network) has decreased in relative terms, while importance of logs increased (logs became more load bearing? Yes!)
Second, should we …
Now for the additions I’ve had a few recent discussions with people about this, and I’m happy to go through a few candidates.
First, let’s tackle cloud. There are some arguments that cloud represents a new visibility pillar. The arguments in favor include the fact that cloud environments are different and that cloud visibility is critical. However, to me, a strong counterpoint is that cloud visibility In many cases, is provided by endpoint, network, and logs, as well as a few things. We will touch these “few things” in a moment.
YES?
NO?
Verdict:
The second candidate to be added is, of course, identity. Here we have a much stronger case that identity needs to be added as a pillar. So perhaps we would have an endpoint, network, logs and identity as our model. Let’s review some pros and cons for identity as a visibility pillar.
YES?
NO?
Verdict:
Still, I don’t want to say that identity is merely just about logs, because “baby … bathwater.” Some of the emerging ITDR solutions are not simply relying on logs. I don’t think that identity is necessarily a new pillar, but there are strong arguments that perhaps it should be…
What do you think — should identity be a new visibility pillar?
Hold on here, Anton, we need more data!
Here:

and

Now let’s tackle the final candidate, the one I considered in 2020 to be the fourth leg of a three legged stool. There is, of course, application visibility, powered by increased popularity of observability data, eBPF, etc. Application visibility is not really covered by endpoint orgs and definitely not by EDR observation. Similarly, application visibility is very hard to deduce from network traffic data.
YES?
NO?
Verdict:
So, we have a winner. Anton’s SOC visibility QUAD of 2025

Are you ready? … Ready or not, HERE WE GOOOO!
Related blogs:
SOC Visibility Triad is Now A Quad — SOC Visibility Quad 2025 was originally published in Anton on Security on Medium, where people are continuing the conversation by highlighting and responding to this story.

This webcast was originally published on November 8, 2024. In this video, Hayden Covington discusses the detection engineering process and how to apply the scientific method to improve the quality […]
The post The Detection Engineering Process appeared first on Black Hills Information Security, Inc..

By Ray Van Hoose, Wade Wells, and Edna Jonsson || Guest Authors This post is comprised of 3 articles that were originally published in the second edition of the InfoSec […]
The post Pentesting, Threat Hunting, and SOC: An Overview appeared first on Black Hills Information Security, Inc..

A lot of emphasis and focus is put on the investigative part of SOC work, with the documentation and less glamorous side of things brushed under the rug. One such […]
The post Clear, Concise, and Comprehensive: The Formula for Great SOC Tickets appeared first on Black Hills Information Security, Inc..

Recently in the SOC, we were notified by a partner that they had a potential business email compromise, or BEC. We commonly catch these by identifying suspicious email forwarding rules, […]
The post Monitoring High Risk Azure Logins appeared first on Black Hills Information Security, Inc..