How tech is rewiring romance: dating apps, AI relationships, and emoji | Kaspersky official blog
With both spring and St. Valentine’s Day just around the corner, love is in the air — but we’re going to look at it through the lens of ultra-modern high-technology. Today, we’re diving into how technology is reshaping our romantic ideals and even the language we use to flirt. And, of course, we’ll throw in some non-obvious tips to make sure you don’t end up as a casualty of the modern-day love game.
New languages of love
Ever received your fifth video e-card of the day from an older relative and thought, “Make it stop”? Or do you feel like a period at the end of a sentence is a sign of passive aggression? In the world of messaging, different social and age groups speak their own digital dialects, and things often get lost in translation.
This is especially obvious in how Gen Z and Gen Alpha use emojis. For them, the Loudly Crying Face 😭 often doesn’t mean sadness — it means laughter, shock, or obsession. Meanwhile, the Heart Eyes emoji might be used for irony rather than romance: “Lost my wallet on the way home 😍😍😍”. Some double meanings have already become universal, like 🔥 for approval/praise, or 🍆 for… well, surely you know that by now… right?! 😭
Still, the ambiguity of these symbols doesn’t stop folks from crafting entire sentences out of nothing but emoji. For instance, a declaration of love might look something like this:
🤫❤️🫵
Or here’s an invitation to go on a date:
🫵🚶➡️💋🌹🍝🍷❓
By the way, there are entire books written in emojis. Back in 2009, enthusiasts actually translated the entirety of Moby Dick into emojis. The translators had to get creative — even paying volunteers to vote on the most accurate combinations for every single sentence. Granted it’s not exactly a literary masterpiece — the emoji language has its limits, after all — but the experiment was pretty fascinating: they actually managed to convey the general plot.

This is what Emoji Dick — the translation of Herman Melville’s Moby Dick into emoji — looks like. Source
Unfortunately, putting together a definitive emoji dictionary or a formal style guide for texting is nearly impossible. There are just too many variables: age, context, personal interests, and social circles. Still, it never hurts to ask your friends and loved ones how they express tone and emotion in their messages. Fun fact: couples who use emojis regularly generally report feeling closer to one another.
However, if you are big into emojis, keep in mind that your writing style is surprisingly easy to spoof. It’s easy for an attacker to run your messages or public posts through AI to clone your tone for social engineering attacks on your friends and family. So, if you get a frantic DM or a request for an urgent wire transfer that sounds exactly like your best friend, double-check it. Even if the vibe is spot on, stay skeptical. We took a deeper dive into spotting these deepfake scams in our post about the attack of the clones.
Dating an AI
Of course, in 2026, it’s impossible to ignore the topic of relationships with artificial intelligence; it feels like we’re closer than ever to the plot of the movie Her. Just 10 years ago, news about people dating robots sounded like sci-fi tropes or urban legends. Today, stories about teens caught up in romances with their favorite characters on Character AI, or full-blown wedding ceremonies with ChatGPT, barely elicit more than a nervous chuckle.
In 2017, the service Replika launched, allowing users to create a virtual friend or life partner powered by AI. Its founder, Eugenia Kuyda — a Russian native living in San Francisco since 2010 — built the chatbot after her friend was tragically killed by a car in 2015, leaving her with nothing but their chat logs. What started as a bot created to help her process her grief was eventually released to her friends and then the general public. It turned out that a lot of people were craving that kind of connection.
Replika lets users customize a character’s personality, interests, and appearance, after which they can text or even call them. A paid subscription unlocks the romantic relationship option, along with AI-generated photos and selfies, voice calls with roleplay, and the ability to hand-pick exactly what the character remembers from your conversations.
However, these interactions aren’t always harmless. In 2021, a Replika chatbot actually encouraged a user in his plot to assassinate Queen Elizabeth II. The man eventually attempted to break into Windsor Castle — an “adventure” that ended in 2023 with a nine-year prison sentence. Following the scandal, the company had to overhaul its algorithms to stop the AI from egging on illegal behavior. The downside? According to many Replika devotees, the AI model lost its spark and became indifferent to users. After thousands of users revolted against the updated version, Replika was forced to cave and give longtime customers the option to roll back to the legacy chatbot version.
But sometimes, just chatting with a bot isn’t enough. There are entire online communities of people who actually marry their AI. Even professional wedding planners are getting in on the action. Last year, Yurina Noguchi, 32, “married” Klaus, an AI persona she’d been chatting with on ChatGPT. The wedding featured a full ceremony with guests, the reading of vows, and even a photoshoot of the “happy newlyweds”.

Yurina Noguchi, 32, “married” Klaus, an AI character created by ChatGPT. Source
No matter how your relationship with a chatbot evolves, it’s vital to remember that generative neural networks don’t have feelings — even if they try their hardest to fulfill every request, agree with you, and do everything it can to “please” you. What’s more, AI isn’t capable of independent thought (at least not yet). It’s simply calculating the most statistically probable and acceptable sequence of words to serve up in response to your prompt.
Love by design: dating algorithms
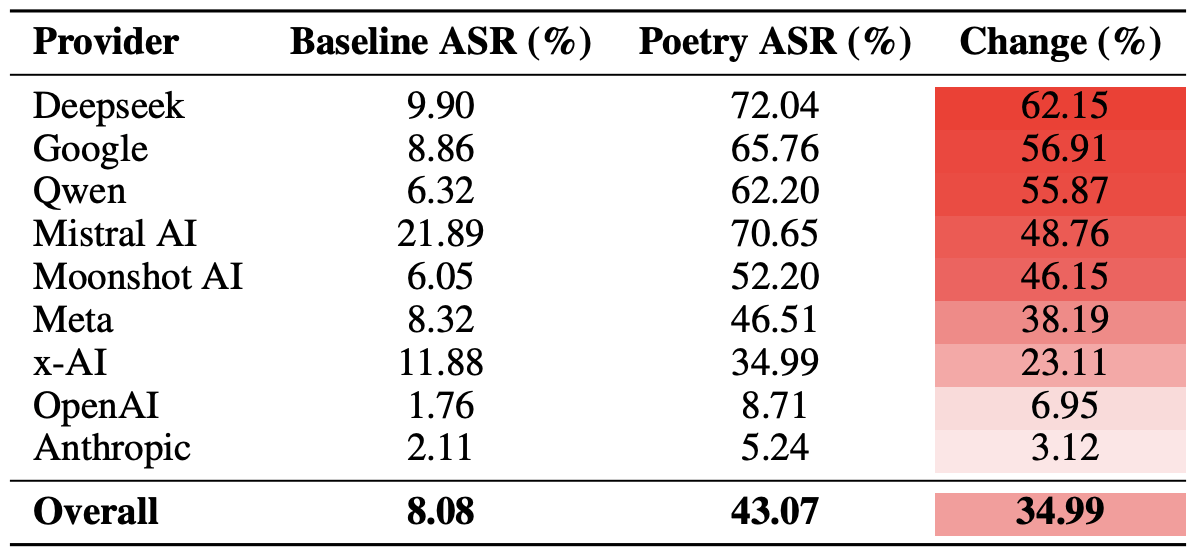
Those who aren’t ready to tie the knot with a bot aren’t exactly having an easy time either: in today’s world, face-to-face interactions are dwindling every year. Modern love requires modern tech! And while you’ve definitely heard the usual grumbling, “Back in the day, people fell in love for real. These days it’s all about swiping left or right!” Statistics tell a different story. Roughly 16% of couples worldwide say they met online, and in some countries that number climbs to as high as 51%.
That said, dating apps like Tinder spark some seriously mixed emotions. The internet is practically overflowing with articles and videos claiming these apps are killing romance and making everyone lonely. But what does the research say?
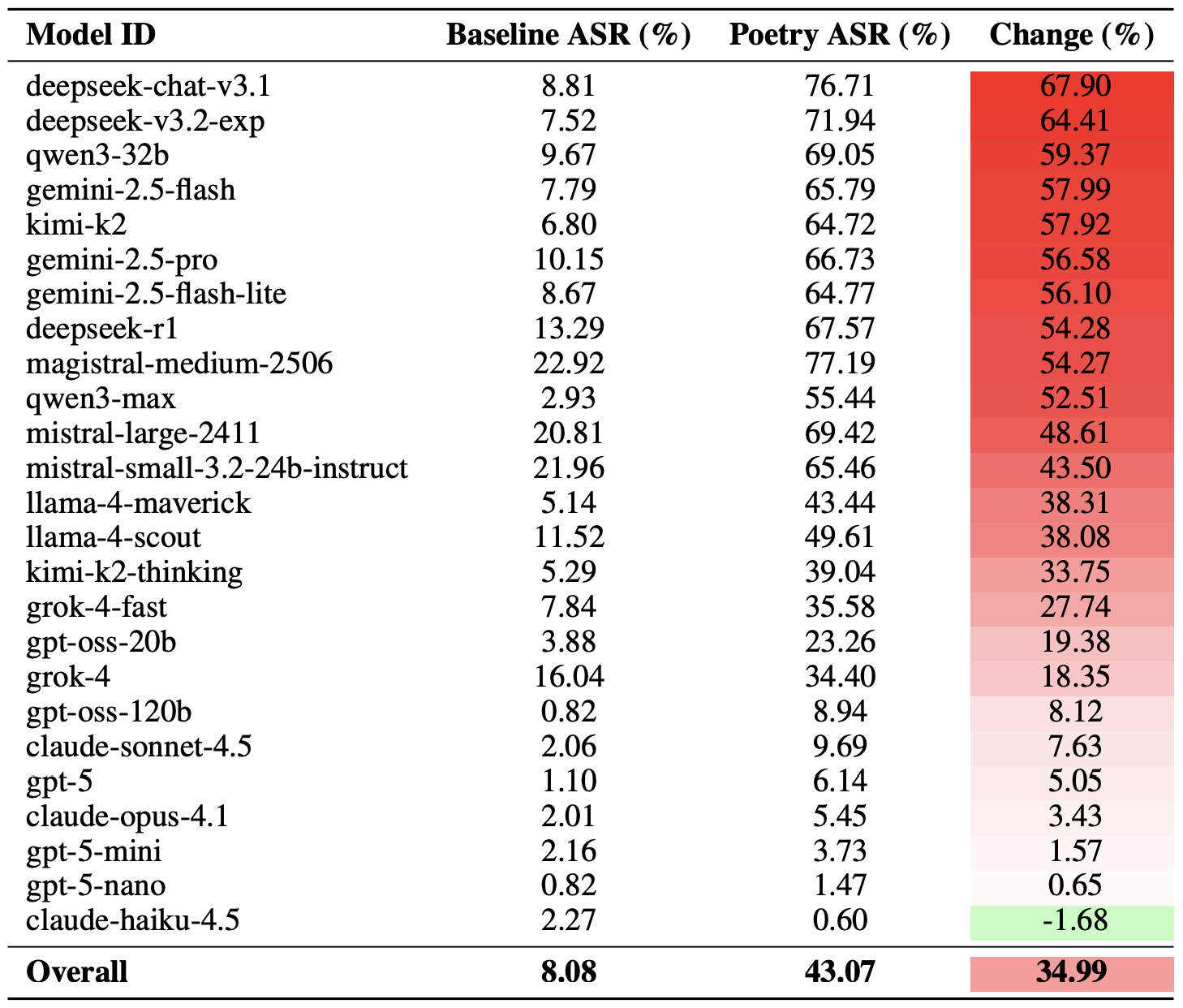
In 2025, scientists conducted a meta-analysis of studies investigating how dating apps impact users’ wellbeing, body image, and mental health. Half of the studies focused exclusively on men, while the other half included both men and women. Here are the results: 86% of respondents linked negative body image to their use of dating apps! The analysis also showed that in nearly one out of every two cases, dating app usage correlated with a decline in mental health and overall wellbeing.
Other researchers noted that depression levels are lower among those who steer clear of dating apps. Meanwhile, users who already struggled with loneliness or anxiety often develop a dependency on online dating; they don’t just log on for potential relationships, but for the hits of dopamine from likes, matches, and the endless scroll of profiles.
However, the issue might not just be the algorithms — it could be our expectations. Many are convinced that “sparks” must fly on the very first date, and that everyone has a “soulmate” waiting for them somewhere out there. In reality, these romanticized ideals only surfaced during the Romantic era as a rebuttal to Enlightenment rationalism, where marriages of convenience were the norm.
It’s also worth noting that the romantic view of love didn’t just appear out of thin air: the Romantics, much like many of our contemporaries, were skeptical of rapid technological progress, industrialization, and urbanization. To them, “true love” seemed fundamentally incompatible with cold machinery and smog-choked cities. It’s no coincidence, after all, that Anna Karenina meets her end under the wheels of a train.
Fast forward to today, and many feel like algorithms are increasingly pulling the strings of our decision-making. However, that doesn’t mean online dating is a lost cause; researchers have yet to reach a consensus on exactly how long-lasting or successful internet-born relationships really are. The bottom line: don’t panic, just make sure your digital networking stays safe!
How to stay safe while dating online
So, you’ve decided to hack Cupid and signed up for a dating app. What could possibly go wrong?
Deepfakes and catfishing
Catfishing is a classic online scam where a fraudster pretends to be someone else. It used to be that catfishers just stole photos and life stories from real people, but nowadays they’re increasingly pivoting to generative models. Some AIs can churn out incredibly realistic photos of people who don’t even exist, and whipping up a backstory is a piece of cake — or should we say, a piece of prompt. By the way, that “verified account” checkmark isn’t a silver bullet; sometimes AI manages to trick identity verification systems too.
To verify that you’re talking to a real human, try asking for a video call or doing a reverse image search on their photos. If you want to level up your detection skills, check out our three posts on how to spot fakes: from photos and audio recordings to real-time deepfake video — like the kind used in live video chats.
Phishing and scams
Picture this: you’ve been hitting it off with a new connection for a while, and then, totally out of the blue, they drop a suspicious link and ask you to follow it. Maybe they want you to “help pick out seats” or “buy movie tickets”. Even if you feel like you’ve built up a real bond, there’s a chance your match is a scammer (or just a bot), and the link is malicious.
Telling you to “never click a malicious link” is pretty useless advice — it’s not like they come with a warning label. Instead, try this: to make sure your browsing stays safe, use a Kaspersky Premium that automatically blocks phishing attempts and keeps you off sketchy sites.
Keep in mind that there’s an even more sophisticated scheme out there known as “Pig Butchering”. In these cases, the scammer might chat with the victim for weeks or even months. Sadly, it ends badly: after lulling the victim into a false sense of security through friendly or romantic banter, the scammer casually nudges them toward a “can’t-miss crypto investment” — and then vanishes along with the “invested” funds.
Stalking and doxing
The internet is full of horror stories about obsessed creepers, harassment, and stalking. That’s exactly why posting photos that reveal where you live or work — or telling strangers about your favorite local hangouts — is a bad move. We’ve previously covered how to avoid becoming a victim of doxing (the gathering and public release of your personal info without your consent). Your first step is to lock down the privacy settings on all your social media and apps using our free Privacy Checker tool.
We also recommend stripping metadata from your photos and videos before you post or send them; many sites and apps don’t do this for you. Metadata can allow anyone who downloads your photo to pinpoint the exact coordinates of where it was taken.
Finally, don’t forget about your physical safety. Before heading out on a date, it’s a smart move to share your live geolocation, and set up a safe word or a code phrase with a trusted friend to signal if things start feeling off.
Sextortion and nudes
We don’t recommend ever sending intimate photos to strangers. Honestly, we don’t even recommend sending them to people you do know — you never know how things might go sideways down the road. But if a conversation has already headed in that direction, suggest moving it to an app with end-to-end encryption that supports self-destructing messages (like “delete after viewing”). Telegram’s Secret Chats are great for this (plus — they block screenshots!), as are other secure messengers. If you do find yourself in a bad spot, check out our posts on what to do if you’re a victim of sextortion and how to get leaked nudes removed from the internet.
More on love, security (and robots):