Six mistakes in ERC-4337 smart accounts
Account abstraction transforms fixed “private key can do anything” models into programmable systems that enable batching, recovery and spending limits, and flexible gas payment. But that programmability introduces risks: a single bug can be as catastrophic as leaking a private key.
After auditing dozens of ERC‑4337 smart accounts, we’ve identified six vulnerability patterns that frequently appear. By the end of this post, you’ll be able to spot these issues and understand how to prevent them.
How ERC-4337 works
Before we jump into the common vulnerabilities that we often encounter when auditing smart accounts, here’s the quick mental model of how ERC-4337 works. There are two kinds of accounts on Ethereum: externally owned accounts (EOAs) and contract accounts.
-
EOAs are simple key-authorized accounts that can’t run custom logic. For example, common flows like token interactions require two steps (approve/permit, then execute), which fragments transactions and confuses users.
-
Contract accounts are smart contracts that can enforce rules, but cannot initiate transactions on their own.
Before account abstraction, if you wanted wallet logic like spending limits, multi-sig, or recovery, you’d deploy a smart contract wallet like Safe. The problem was that an EOA still had to kick off every transaction and pay gas in ETH, so in practice, you were juggling two accounts: one to sign and one to hold funds.
ERC-4337 removes that dependency. The smart account itself becomes the primary account. A shared EntryPoint contract and off-chain bundlers replace the EOA’s role, and paymasters let you sponsor gas or pay in tokens instead of ETH.
Here’s how ERC-4337 works:
-
Step 1: The user constructs and signs a
UserOperationoff-chain. This includes the intended action (callData), a nonce, gas parameters, an optional paymaster address, and the user’s signature over the entire message. -
Step 2: The signed
UserOperationis sent to a bundler (think of it as a specialized relayer). The bundler simulates it locally to check it won’t fail, then batches it with other operations and submits the bundle on-chain to theEntryPointviahandleOps. -
Step 3: The
EntryPointcontract callsvalidateUserOpon the smart account, which verifies the signature is valid and that the account can cover the gas cost. If a paymaster is involved, theEntryPointalso validates that the paymaster agrees to sponsor the fees. -
Step 4: Once validation passes, the
EntryPointcalls back into the smart account to execute the actual operation. The following figure shows theEntryPointflow diagram from ERC-4337:
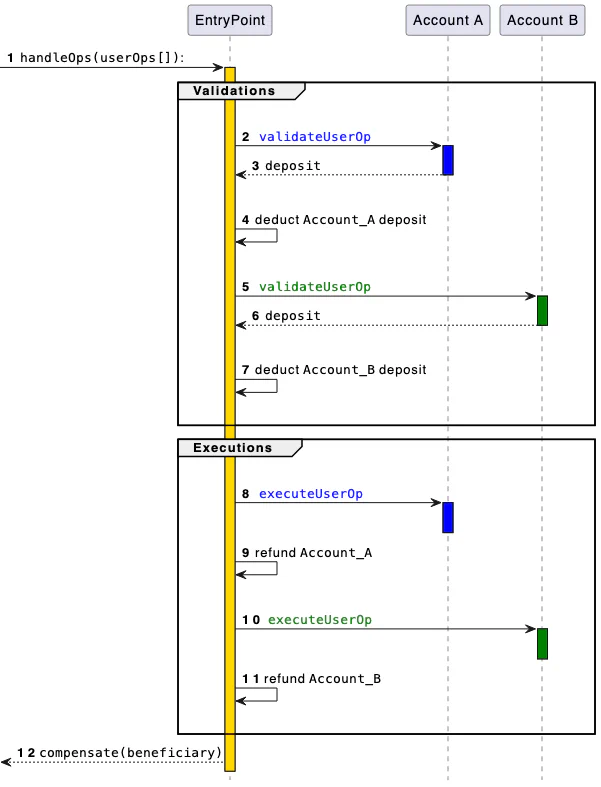
If you’re not already familiar with ERC-4337 or want to dig into the details we’re glossing over here, it’s worth reading through the full EIP. The rest of this post assumes you’re comfortable with the basics.
Now that we’ve covered the ERC-4337 attack surface, let’s explore the common vulnerability patterns we encounter in our audits.
1. Incorrect access control
If anyone can call your account’s execute function (or anything that moves funds) directly, they can do anything with your wallet. Only the EntryPoint contract should be allowed to trigger privileged paths, or a vetted executor module in ERC-7579.
A vulnerable implementation allows anyone to drain the wallet:
function execute(address target, uint256 value, bytes calldata data) external {
(bool ok,) = target.call{value: value}(data);
require(ok, "exec failed");
}While in a safe implementation, the execute function is callable only by entryPoint:
address public immutable entryPoint;
function execute(address target, uint256 value, bytes calldata data)
external
{
require(msg.sender == entryPoint, "not entryPoint");
(bool ok,) = target.call{value: value}(data);
require(ok, "exec failed");
}Here are some important considerations for access control:
-
For each
externalorpublicfunction, ensure that the proper access controls are set. -
In addition to the
EntryPointaccess control, some functions need to restrict access to the account itself. This is because you may frequently want to call functions on your contract to perform administrative tasks like module installation/uninstallation, validator modifications, and upgrades.
2. Incomplete signature validation (specifically the gas fields)
A common and serious vulnerability arises when a smart account verifies only the intended action (for example, the callData) but omits the gas-related fields:
-
preVerificationGas -
verificationGasLimit -
callGasLimit -
maxFeePerGas -
maxPriorityFeePerGas
All of these values are part of the payload and must be signed and checked by the validator. Since the EntryPoint contract computes and settles fees using these parameters, any field that is not cryptographically bound to the signature and not sanity-checked can be altered by a bundler or a frontrunner in transit.
By inflating these values (for example, preVerificationGas, which directly reimburses calldata/overhead), an attacker can cause the account to overpay and drain ETH. preVerificationGas is the portion meant to compensate the bundler for work outside validateUserOp, primarily calldata size costs and fixed inclusion overhead.
We use preVerificationGas as the example because it’s the easiest lever to extract ETH: if it isn’t signed or strictly validated/capped, someone can simply bump that single number and get paid more, directly draining the account.
Robust implementations must bind the full UserOperation, including all gas fields, into the signature, and so enforce conservative caps and consistency checks during validation.
Here’s an example of an unsafe validateUserOp function:
function validateUserOp(UserOperation calldata op, bytes32 /*hash*/, uint256 /*missingFunds*/)
external
returns (uint256 validationData)
{
// Only checks that the calldata is “approved”
require(_isApprovedCall(op.callData, op.signature), "bad sig");
return 0;
}And here’s an example of a safe validateUserOp function:
function validateUserOp(UserOperation calldata op, bytes32 userOpHash, uint256 /*missingFunds*/)
external
returns (uint256 validationData)
{
require(_isApprovedCall(userOpHash, op.signature), "bad sig");
return 0;
}Here are some additional considerations:
-
Ideally, use the
userOpHashsent by theEntrypointcontract, which includes the gas fields by spec. -
If you must allow flexibility, enforce strict caps and reasonability checks on each gas field.
3. State modification during validation
Writing state in validateUserOp and then using it during execution is dangerous since the EntryPoint contract validates all ops in a bundle before executing any of them. For example, if you cache the recovered signer in storage during validation and later use that value in execute, another op’s validation can overwrite it before yours runs.
contract VulnerableAccount {
address public immutable entryPoint;
address public owner1;
address public owner2;
address public pendingSigner;
modifier onlyEntryPoint() { require(msg.sender == entryPoint, "not EP"); _; }
function validateUserOp(UserOperation calldata op, bytes32 userOpHash, uint256)
external
returns (uint256)
{
address signer = recover(userOpHash, op.signature);
require(signer == owner1 || signer == owner2, "unauthorized");
// DANGEROUS: persists signer; can be clobbered by another validation
pendingSigner = signer;
return 0;
}
// Later: appends signer into the call; may use the WRONG (overwritten) signer
function executeWithSigner(address target, uint256 value, bytes calldata data) external onlyEntryPoint {
bytes memory payload = abi.encodePacked(data, pendingSigner);
(bool ok,) = target.call{value: value}(payload);
require(ok, "exec failed");
}
}In Figure 6, one of the two owners can validate a function, but use the other owner’s address in the execute function. Depending on how the execute function is supposed to work in that case, it can be an attack vector.
Here are some important considerations for state modification:
-
Avoid modifying the state of the account during the validation phase.
-
Remember batch semantics: all validations run before any execution, so any “approval” written in validation can be overwritten by a later op’s validation.
-
Use a mapping keyed by
userOpHashto persist temporary data, and delete it deterministically after use, but prefer not persisting anything at all.
4. ERC‑1271 replay signature attack
ERC‑1271 is a standard interface for contracts to validate signatures so that other contracts can ask a smart account, via isValidSignature(bytes32 hash, bytes signature), whether a particular hash has been approved.
A recurring pitfall, highlighted by security researcher curiousapple (read the post-mortem here), is to verify that the owner signed a hash without binding the signature to the specific smart account and the chain. If the same owner controls multiple smart accounts, or if the same account exists across chains, a signature created for account A can be replayed against account B or on a different chain.
The remedy is to use EIP‑712 typed data so the signature is domain‑separated by both the smart account address (as verifyingContract) and the chainId.
At a minimum, the signed payload must include the account and chain so that a signature cannot be transplanted across accounts or networks. A robust pattern is to wrap whatever needs authorizing inside an EIP‑712 struct and recover against the domain; this automatically binds the signature to the correct account and chain.
function isValidSignature(bytes32 hash, bytes calldata sig)
external
view
returns (bytes4)
{
// Replay issue: recovers over a raw hash,
// not bound to this contract or chainId.
return ECDSA.recover(hash, sig) == owner ? MAGIC : 0xffffffff;
}function isValidSignature(bytes32 hash, bytes calldata sig)
external
view
returns (bytes4)
{
bytes32 structHash = keccak256(abi.encode(TYPEHASH, hash));
bytes32 digest = _hashTypedDataV4(structHash);
return ECDSA.recover(digest, sig) == owner ? MAGIC : 0xffffffff;
}Here are some considerations for ERC-1271 signature validations:
-
Always verify EIP‑712 typed data so the domain binds signatures to
chainIdand the smart account address. -
Enforce exact ERC‑1271 magic value return (
0x1626ba7e) on success; anything else is failure. -
Test negative cases explicitly: same signature on a different account, same signature on a different chain, and same signature after nonce/owner changes.
5. Reverts don’t save you in ERC‑4337
In ERC-4337, once validateUserOp succeeds, the bundler gets paid regardless of whether execution later reverts. This is the same model as normal Ethereum transactions, where miners collect fees even on failed txs, so planning to “revert later” is not a safety net. The success of validateUserOp commits you to paying for gas.
This has a subtle consequence: if your validation is too permissive and accepts operations that will inevitably fail during execution, a malicious bundler can submit those operations repeatedly, each time collecting gas fees from your account without anything useful happening.
A related issue we’ve seen in audits involves paymasters that pay the EntryPoint from a shared pool during validateUserOp, then try to charge the individual user back in postOp. The problem is that postOp can revert (bad state, arithmetic errors, risky external calls), and a revert in postOp does not undo the payment that already happened during validation. An attacker can exploit this by repeatedly passing validation while forcing postOp failures by withdrawing his ETH from the pool during the execution of the userOp, for example, and draining the shared pool.
The robust approach is to never rely on postOp for core invariants. Debit fees from a per-user escrow or deposit during validation, so the money is secured before execution even begins. Treat postOp as best-effort bookkeeping: keep it minimal, bounded, and designed to never revert.
Here are some important considerations for ERC-4337:
-
Make
postOpminimal and non-reverting: avoid external calls and complex logic, and instead treat it as best-effort bookkeeping. -
Test both success and revert paths. Consider that once the
validateUserOpfunction returns a success, the account will pay for the gas.
6. Old ERC‑4337 accounts vs ERC‑7702
ERC‑7702 allows an EOA to temporarily act as a smart account by activating code for the duration of a single transaction, which effectively runs your wallet implementation in the EOA’s context. This is powerful, but it opens an initialization race. If your logic expects an initialize(owner) call, an attacker who spots the 7702 delegation can frontrun with their own initialization transaction and set themselves as the owner. The straightforward mitigation is to permit initialization only when the account is executing as itself in that 7702‑powered call. In practice, require msg.sender == address(this) during initialization.
function initialize(address newOwner) external {
// Only callable when the account executes as itself (e.g., under 7702)
require(msg.sender == address(this), "init: only self");
require(owner == address(0), "already inited");
owner = newOwner;
}This works because, during the 7702 transaction, calls executed by the EOA‑as‑contract have msg.sender == address(this), while a random external transaction cannot satisfy that condition.
Here are some important considerations for ERC-7702:
-
Require
msg.sender == address(this)andowner == address(0)in initialize; make it single‑use and impossible for external callers. -
Create separate smart accounts for ERC‑7702–enabled EOAs and non‑7702 accounts to isolate initialization and management flows.
Quick security checks before you ship
Use this condensed list as a pre-merge gate for every smart account change. These checks block some common AA failures we see in audits and production incidents. Run them across all account variants, paymaster paths, and gas configurations before you ship.
-
Use the
EntryPoint’suserOpHashfor validation. -
Restrict
execute/privileged functions toEntryPoint(and self where needed). -
Keep
validateUserOpstateless: don’t write to storage. -
Force EIP‑712 for ERC‑1271 and other signed messages.
-
Make
postOpminimal, bounded, and non‑reverting. -
For ERC‑7702, allow init only when
msg.sender == address(this), once. -
Add multiple end-to-end tests on success and revert paths.
If you need help securely implementing smart accounts, contact us for an audit.