Beyond “Is Your SOC AI Ready?” Plan the Journey!
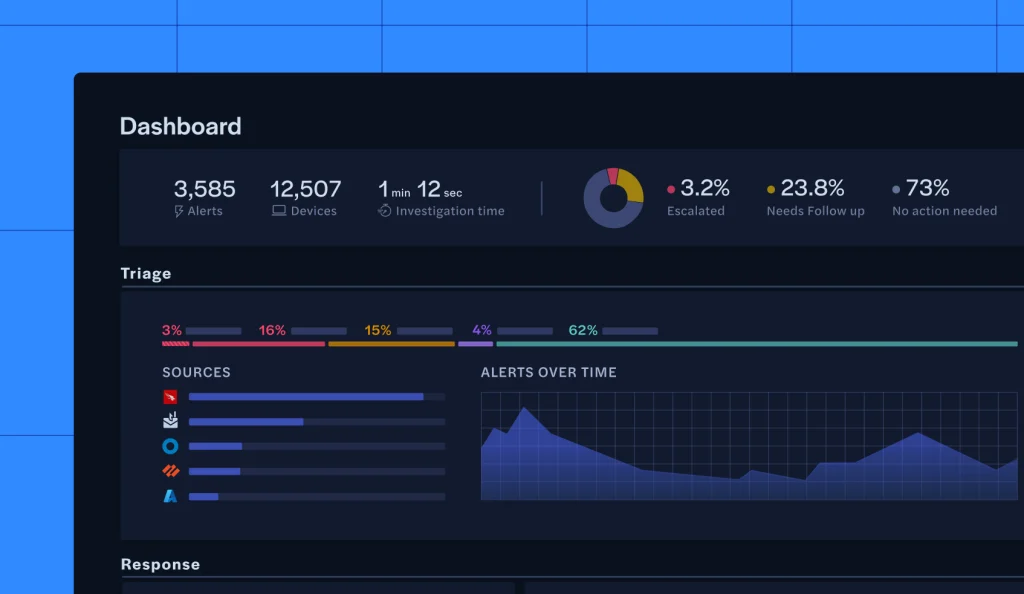
You read the “AI-ready SOC pillars” blog, but you still see a lot of this:
How do we do better?
Let’s go through all 5 pillars aka readiness dimensions and see what we can actually do to make your SOC AI-ready.
#1 SOC Data Foundations
As I said before, this one is my absolute favorite and is at the center of most “AI in SOC” (as you recall, I want AI in my SOC, but I dislike the “AI SOC” concept) successes (if done well) and failures (if not done at all).
Reminder: pillar #1 is “security context and data are available and can be queried by machines (API, Model Context Protocol (MCP), etc) in a scalable and reliable manner.” Put simply, for the AI to work for you, it needs your data. As our friends say here, “Context engineering focuses on what information the AI has available. […] For security operations, this distinction is critical. Get the context wrong, and even the most sophisticated model will arrive at inaccurate conclusions.”
Readiness check: Security context and data are available and can be queried by machines in a scalable and reliable manner. This is very easy to check, yet not easy to achieve for many types of data.
For example, “give AI access to past incidents” is very easy in theory (“ah, just give it old tickets”) yet often very hard in reality (“what tickets?” “aren’t some too sensitive?”, “wait…this ticket didn’t record what happened afterwards and it totally changed the outcome”, “well, these tickets are in another system”, etc, etc)
Steps to get ready:
- Conduct an “API or Die” data access audit to inventory critical data sources (telemetry and context) and stress-test their APIs (or other access methods) under load to ensure they can handle frequent queries from an AI agent. This is important enough to be a Part 3 blog after this one…
- Establish or refine unified, intentional data pipelines for the data you need. This may be your SIEM, this may be a separate security pipeline tool, this may be magick for all I care … but it needs to exist. I met people who use AI to parse human analyst screen videos to understand how humans access legacy data sources, and this is very cool, but perhaps not what you want in prod.
- Revamp case management to force structured data entry (e.g., categorized root causes, tagged MITRE ATT&CK techniques) instead of relying on garbled unstructured text descriptions, which provides clean training data for future AI learning. And, yes, if you have to ask: modern gen AI can understand your garbled stream of consciousness ticket description…. but what it makes of it, you will never know…
Where you arrive: your AI component, AI-powered tool or AI agent can get the data it needs nearly every time. The cases where it cannot become visible, and obvious immediately.
#2 SOC Process Framework and Maturity
Reminder: pillar #2 is “Common SOC workflows do NOT rely on human-to-human communication are essential for AI success.” As somebody called it, you need “machine-intelligible processes.”
Readiness check: SOC workflows are defined as machine-intelligible processes that can be queried programmatically, and explicit, structured handoff criteria are established for all Human-in-the-Loop (HITL) processes, clearly delineating what is handled by the agent versus the person. Examples for handoff to human may include high decision uncertainty, lack of context to make a call (see pillar #1), extra-sensitive systems, etc.
Common investigation and response workflows do not rely on ad-hoc, human-to-human communication or “tribal knowledge,” such knowledge is discovered and brought to surface.
Steps to get ready:
- Codify the “Tribal Knowledge” into APIs: Stop burying your detection logic in dusty PDFs or inside the heads of your senior analysts. You must document workflows in a structured, machine-readable format that an AI can actually query. If your context — like CMDB or asset inventory — isn’t accessible via API (BTW MCP is not magic!), your AI is essentially flying blind.
- Draw a Hard Line Between Agent and Human: Don’t let the AI “guess” its level of authority. Explicitly delegate the high-volume drudgery (log summarization, initial enrichment, IP correlation) to the agent, while keeping high-stakes “kill switches” (like shutting down production servers) firmly in human hands.
- Implement a “Grading” System for Continuous Learning: AI shouldn’t just execute tasks; it needs to go to school. Establish a feedback loop where humans actively “grade” the AI’s triage logic based on historical resolution data. This transforms the system from a static script into a living “recipe” that refines itself over time.
- Target Processes for AI-Driven Automation: Stop trying to “AI all the things.” Identify specific investigation workflows that are candidates for automation and use your historical alert triage data as a training ground to ensure the agent actually learns what “good” looks like.
Where you arrive: The “tribal knowledge” that previously drove your SOC is recorded for machine-readable workflows. Explicit, structured handoff points are established for all Human-in-the-Loop processes, and the system uses human grading to continuously refine its logic and improve its ‘recipe’ over time. This does not mean that everything is rigid; “Visio diagram or death” SOC should stay in the 1990s. Recorded and explicit beats rigid and unchanging.
#3 SOC Human Element and Skills
Reminder: pillar #3 is “Cultivating a culture of augmentation, redefining analyst roles, providing training for human-AI collaboration, and embracing a leadership mindset that accepts probabilistic outcomes.” You say “fluffy management crap”? Well, I say “ignore this and your SOC is dead.”
Readiness check: Leaders have secured formal CISO sign-off on a quantified “AI Error Budget,” defining an acceptable, measured, probabilistic error rate for autonomously closed alerts (that is definitely not zero, BTW). The team is evolving to actively review, grade, and edit AI-generated logic and detection output.
Steps to get ready:
- Implement the “AI Error Budget”: Stop pretending AI will be 100% accurate. You must secure formal CISO sign-off on a quantified “AI Error Budget” — a predefined threshold for acceptable mistakes. If an agent automates 1,000 hours of labor but has a 5% error rate, the leadership needs to acknowledge that trade-off upfront. It’s better to define “allowable failure” now than to explain a hallucination during an incident post-mortem.
- Pivot from “Robot Work” to Agent Shepherding: The traditional L1/L2 analyst role is effectively dead; long live the “Agent Supervisor.” Instead of manually sifting through logs — work that is essentially “robot work” anyway — your team must be trained to review, grade, and edit AI-generated logic. They are no longer just consumers of alerts; they are the “Editors-in-Chief” of the SOC’s intelligence.
- Rebuild the SOC Org Chart and RACI: Adding AI isn’t a “plug and play” software update; it’s an organizational redesign. You need to redefine roles: Detection Engineers become AI Logic Editors, and analysts become Supervisors. Most importantly, your RACI must clearly answer the uncomfortable question: If the AI misses a breach, is the accountability with the person who trained the model or the person who supervised the output?
Where you arrive: well, you arrive at a practical realization that you have “AI in SOC” (and not AI SOC). The tools augment people (and in some cases, do the work end to end too). No pro- (“AI SOC means all humans can go home”) or contra-AI (“it makes mistakes and this means we cannot use it”) crazies nearby.
#4 Modern SOC Technology Stack
Reminder: pillar #4 is “Modern SOC Technology Stack.” If your tools lack APIs, take them and go back to the 1990s from whence you came! Destroy your time machine when you arrive, don’t come back to 2026!
Readiness check: The security stack is modern, fast (“no multi-hour data queries”) interoperable and supports new AI capabilities to integrate seamlessly, tools can communicate without a human acting as a manual bridge and can handle agentic AI request volumes.
Steps to get ready:
- Mandate “Detection-as-Code” (DaC): This is no longer optional. To make your stack machine-readable, you must implement version control (Git), CI/CD pipelines, and automated testing for all detections. If your detection logic isn’t codified, your AI agent has nothing to interact with except a brittle GUI — and that is a recipe for failure.
- Find Your “Interoperability Ceiling” via Stress Testing: Before you go live, simulate reality. Have an agent attempt to enrich 50 alerts simultaneously to see where the pipes burst. Does your SOAR tool hit a rate limit? Does your threat intel provider cut you off? You need to find the breaking point of your tech stack’s interoperability before an actual incident does it for you.
- Decouple “Native” from “Custom” Agents: Don’t reinvent the wheel, but don’t expect a vendor’s “native” agent to understand your weird, proprietary legacy systems. Define a clear strategy: use native agents for standard tool-specific tasks, and reserve your engineering resources for custom agents designed to navigate your unique compliance requirements and internal “secret sauce.”
Where you arrive: this sounds like a perfect quote from Captain Obvious but you arrive at the SOC powered by tools that work with automation, and not with “human bridge” or “swivel chair.”
#5 SOC Metrics and Feedback Loop
Reminder: pillar #5 is “You are ready for AI if you can, after adding AI, answer the “what got better?” question. You need metrics and a feedback loop to get better.”
Readiness check: Hard baseline metrics (MTTR, MTTD, false positive rates) are established before AI deployment, and the team has a way to quantify the value and improvements resulting from AI. When things get better, you will know it.
Steps to get ready:
- Establish the “Before” Baseline and Fix the Data Slop: You cannot claim victory if you don’t know where the goalposts were to begin with. Measure your current MTTR and MTTD rigorously before the first agent is deployed. Simultaneously, force your analysts to stop treating case notes like a private diary. Standardize on structured data entry — categorized root causes and MITRE tags — so the machine has “clean fuel” to learn from rather than a collection of “fixed it” or “closed” comments.
- Build an “AI Gym” Using Your “Golden Set”: Do not throw your agents into the deep end of live production traffic on day one. Curate a “Golden Set” of your 50–100 most exemplary past incidents — the ones with flawless notes, clean data, and correct conclusions. This serves as your benchmark; if the AI can’t solve these “solved” problems correctly, it has no business touching your live environment.
- Adopt Agent-Specific KPIs for Performance Management: Traditional SOC metrics like “number of alerts closed” are insufficient for an AI-augmented team. You need to track Agent Accuracy Rate, Agent Time Savings, and Agent Uptime as religiously as you track patch latency. If your agent is hallucinating 5% of its summaries, that needs to be a visible red flag on your dashboard, not a surprise you discover during an incident post-mortem.
- Close the Loop with Continuous Tuning: Ensure triage results aren’t just filed away to die in an archive. Establish a feedback loop where the results of both human and AI investigations are automatically routed back to tune the underlying detection rules. This transforms your SOC from a static “filter” into a learning system that evolves with every alert.
Where you arrive: you have a fact-based visual that shows your SOC becoming better in ways important to your mission after you add AI (in fact, you SOC will get better even before AI but after you do the prep-work from this document)
As a result, we can hopefully get to this instead:
The path to an AI-ready SOC isn’t paved with new tools; it’s paved with better data, cleaner processes, and a fundamental shift in how we think about human-machine collaboration. If you ignore these pillars, your AI journey will be a series of expensive lessons in why “magic” isn’t a strategy.
But if you get these right? You move from a SOC that is constantly drowning in alerts to a SOC that operates truly 10X effectiveness.
P.S. Anton, you said “10X”, so how does this relate to ASO and “engineering-led” D&R? I am glad you asked. The five pillars we outlined are not just steps for AI; they are the also steps on the road to ASO (see original 2021 paper which is still “the future” for many).
ASO is the vision for a 10X transformation of the SOC, driven by an adaptive, agile, and highly automated approach to threats. The focus on codified, machine-intelligible workflows, a modern stack supporting Detection-as-Code, and reskilling analysts as “Agent Supervisors” directly supports the core of engineering-led D&R. So focusing on these five readiness dimensions, you move from a traditional operations room (lots of “O” for operations) to a scalable, engineering-centric D&R function (where “E” for engineering dominates).
So, which pillar is your SOC’s current ‘weakest link’? Let’s discuss in the comments and on socials!
Related blogs and podcasts:
- “Simple to Ask: Is Your SOC AI Ready? Not Simple to Answer!” (Part 1 to this blog)
- “Modern SecOps: What an AI-ready SOC actually means with Anton Chuvakin” video
- “A Brief Guide for Dealing with ‘Humanless SOC’ Idiots” (the classic!)
- “SOC is Not Dead Yet It May Be Reborn As Security Operations Center of Excellence” (oddly related!)
- EP236 Accelerated SIEM Journey: A SOC Leader’s Playbook for Modernization and AI
- EP242 The AI SOC: Is This The Automation We’ve Been Waiting For?
- EP252 The Agentic SOC Reality: Governing AI Agents, Data Fidelity, and Measuring Success
- EP249 Data First: What Really Makes Your SOC ‘AI Ready’?
Beyond “Is Your SOC AI Ready?” Plan the Journey! was originally published in Anton on Security on Medium, where people are continuing the conversation by highlighting and responding to this story.