Case study: Securing AI application supply chains
The rapid adoption of AI applications, including agents, orchestrators, and autonomous workflows, represents a significant shift in how software systems are built and operated. Unlike traditional applications, these systems are active participants in execution. They make decisions, invoke tools, and interact with other systems on behalf of users. While this evolution enables new capabilities, it also introduces an expanded and less familiar attack surface.
Security discussions often focus on prompt-level protections, and that focus is justified. However, prompt security addresses only one layer of risk. Equally important is securing the AI application supply chain, including the frameworks, SDKs, and orchestration layers used to build and operate these systems. Vulnerabilities in these components can allow attackers to influence AI behavior, access sensitive resources, or compromise the broader application environment.
The recent disclosure of CVE-2025-68664, known as LangGrinch, in LangChain Core highlights the importance of securing the AI supply chain. This blog uses that real-world vulnerability to illustrate how Microsoft Defender posture management capabilities can help organizations identify and mitigate AI supply chain risks.
Case example: Serialization injection in LangChain (CVE-2025-68664)
A recently disclosed vulnerability in LangChain Core highlights how AI frameworks can become conduits for exploitation when workloads are not properly secured. Tracked as CVE-2025-68664 and commonly referred to as LangGrinch, this flaw exposes risks associated with insecure deserialization in agentic ecosystems that rely heavily on structured metadata exchange.
Vulnerability summary
CVE-2025-68664 is a serialization injection vulnerability affecting the langchain-core Python package. The issue stems from improper handling of internal metadata fields during the serialization and deserialization process. If exploited, an attacker could:
- Extract secrets such as environment variables without authorization
- Instantiate unintended classes during object reconstruction
- Trigger side effects through malicious object initialization
The vulnerability carries a CVSS score of 9.3, highlighting the risks that arise when AI orchestration systems do not adequately separate control signals from user-supplied data.
Understanding the root cause: The lc marker
LangChain utilizes a custom serialization format to maintain state across different components of an AI chain. To distinguish between standard data and serialized LangChain objects, the framework uses a reserved key called lc. During deserialization, when the framework encounters a dictionary containing this key, it interprets the content as a trusted object rather than plain user data.
The vulnerability originates in the dumps() and dumpd() functions in affected versions of the langchain-core package. These functions did not properly escape or neutralize the lc key when processing user-controlled dictionaries. As a result, if an attacker is able to inject a dictionary containing the lc key into a data stream that is later serialized and deserialized, the framework may reconstruct a malicious object.
This is a classic example of an injection flaw where data and control signals are not properly separated, allowing untrusted input to influence the execution flow.
Mitigation and protection guidance
Microsoft recommends that all organizations using LangChain review their deployments and apply the following mitigations immediately.
1. Update LangChain Core
The most effective defense is to upgrade to a patched version of the langchain-core package.
- For 0.3.x users: Update to version 0.3.81 or later.
- For 1.x users: Update to version 1.2.5 or later.
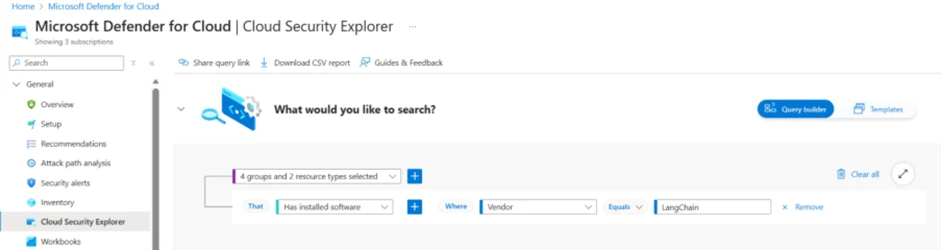
2. Query the security explorer to identify any instances of LangChain in your environment
To identify instances of LangChain package in the assets protected by Defender for Cloud, customers can use the Cloud Security Explorer:
*Identification in cloud compute resources requires Defender CSPM / Defender for Containers / Defender for Servers plan.
*Identification in code environment requires connecting your code environment to Defender for Cloud Learn how to set up connectors
3. Remediate based on Defender for Cloud recommendations across the software development cycle: Code, Ship, Runtime
*Identification in cloud compute resources requires Defender CSPM / Defender for Containers / Defender for Servers plan.
*Identification in code environment requires connecting your code environment to Defender for Cloud Learn how to set up connectors
4. Create GitHub issues with runtime context directly from Defender for Cloud, track progress, and use Copilot coding agent for AI-powered automated fix
Learn more about Defender for Cloud seamless workflows with GitHub to shorten remediation times for security issues.
Microsoft Defender XDR detections
Microsoft security products provide several layers of defense to help organizations identify and block exploitation attempts related to AI vulnerable software.
Microsoft Defender provides visibility into vulnerable AI workloads through its Cloud Security Posture Management (Defender CSPM).
Vulnerability Assessment: Defender for Cloud scanners have been updated to identify containers and virtual machines running vulnerable versions of langchain-core. Microsoft Defender is actively working to expand coverage to additional platforms and this blog will be updated when more information is available.
Hunting queries
Microsoft Defender XDR
Security teams can use the advanced hunting capabilities in Microsoft Defender XDR to proactively look for indicators of exploitation. A common sign of exploitation is a Python process associated with LangChain attempting to access sensitive environment variables or making unexpected network connections immediately following an LLM interaction.
The following Kusto Query Language (KQL) query can be used to identify devices that are using the vulnerable software:
DeviceTvmSoftwareInventory
| where SoftwareName has "langchain"
and (
// Lower version ranges
SoftwareVersion startswith "0."
and toint(split(SoftwareVersion, ".")[1]) References
- NVD - CVE-2025-68664
- All I Want for Christmas is Your Secrets: LangGrinch hits LangChain Core (CVE-2025-68664) - Cyata | The Control Plane for Agentic Identity
- fix(core): serialization patch by mdrxy · Pull Request #34458 · langchain-ai/langchain · GitHub
- fix(core): serialization patch by ccurme · Pull Request #34455 · langchain-ai/langchain · GitHub
- What is Cloud Security Posture Management (CSPM) - Microsoft Defender for Cloud | Microsoft Learn
- Build queries with cloud security explorer - Microsoft Defender for Cloud | Microsoft Learn
This research is provided by Microsoft Defender Security Research with contributions from Tamer Salman, Astar Lev, Yossi Weizman, Hagai Ran Kestenberg, and Shai Yannai.
Learn more
Review our documentation to learn more about our real-time protection capabilities and see how to enable them within your organization.
Learn more about securing Copilot Studio agents with Microsoft Defender
Learn more about Protect your agents in real-time during runtime (Preview) – Microsoft Defender for Cloud Apps | Microsoft Learn
Explore how to build and customize agents with Copilot Studio Agent Builder
The post Case study: Securing AI application supply chains appeared first on Microsoft Security Blog.